python文件编码转换流程python默认字符创编码是unicodepython文件编码跟变量编码是两个东西exampl#-*- coding:utf-8 -*-ss = "你好" #这个变量的默认编码是unicode#此python文件的默认编码是utf-8 原文:https://www.cnblogs.com/hhjmessage/p/8302158.html
python对多国语言的处理是支持的很好的,它可以处理现在任意编码的字符,这里深入的研究一下python对多种不同语言的处理。有一点需要清楚的是,当python要做编码转换的时候,会借助于内部的编码,转换过程是这样的:复制代码 代码如下:
原有编码 -> 内部编码 -> 目的编码
python的内部是使用unicode来处理的,但是unicode的使用需要考虑的是它的编码格式有两种,一是UCS-2,它一共有65536个码位,另一种是UCS-4,它有2147483648g个...
Python 3最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。你不能拼接字符串和字节包,也无法在字节包里搜索字符串(反之亦然),也不能将字符串传入参数为字节包的函数(反之亦然). python3.0中怎么创建bytes型数据12bytes([1,2,3,4,5,6,7,8,9])bytes("python", ‘...
目录1. id 和 ==2. 小数据池3. 编码和解码1. id 和 ==id:id是一个内置的函数,可以查看变量存放的内存地址(实际上不是真正的物理地址,这里暂时这样理解),用于判断是变量否属指向了同一块内存地址==:== 可以用于判断两个变量的值是否相等,这个在之前的例子中也有用过下面来看几个例子,以及具体的使用方法:In [1]: a = ‘abc‘In [2]: b = ‘abc‘In [3]: a == b
Out[3]: TrueIn [4]: a is b
Out[4]: TrueIn [5]: c = 100In...
在日常渗透,漏洞挖掘,甚至是CTF比赛中会遇到各种编码,常常伴随着这些编码之间的各种转换。下面这篇文章主要介绍了python中编码转换妙用的相关资料,需要的朋友们可以参考借鉴,下面来一起看看吧。前言记得刚入门那个时候,自己处理编码转换问题往往是“百度:url解码、base64加密、hex……”,或者是使用一款叫做“小葵多功能转换工具”的软件,再后来直接上Burpsuite的decoder功能,感觉用的还挺好的。不过,也遇到些问题:在线...
python 有str object 和 unicode object 两种字符串, 都可以存放字符的字节编码,但是他们是不同的type,这一点很重要,也是为什么会有encode 和decode。encode 和 decode在pyhton 中的意义可表示为 encodeunicode -------------------------> strunicode <--------------------------str decode几种常用法:str_string.decode(codec) 是把str_string转换为unicode_string, codec是源str_string的编码方式unicode_string...
python对多国语言的处理是支持的很好的,它可以处理现在任意编码的字符,这里深入的研究一下python对多种不同语言的处理。
有一点需要清楚的是,当python要做编码转换的时候,会借助于内部的编码,转换过程是这样的:代码如下:
原有编码 -> 内部编码 -> 目的编码python的内部是使用unicode来处理的,但是unicode的使用需要考虑的是它的编码格式有两种,一是UCS-2,它一共有65536个码位,另一种是UCS-4,它有2147483648g个码位。对于...
我们在使用其他语言的库做编码转换时,对于无法理解的字符,通常的处理也只有两种(或三种):
抛异常替换成替代字符跳过但是在复杂的现实世界中,由于各种不靠谱,我们处理的文本总会出现那么些不和谐因素,比如混合编码。在这种情况下,又回到了上面的处理办法。
那么问题来了,python有没有更好地办法呢?
答案是,有!
python的编码转换流程实际上是两段式转换:source -> unicode -> dest
首先将字符串从原始编码转换成unicod...
Python encode()和decode()方法:字符串编码转换
前面章节在介绍 bytes 类型时,已经对 encode() 和 decode() 方法的使用做了简单的介绍, 本节将对这 2 个方法做详细地说明。
我们知道,最早的字符串编码是 ASCII 编码,它仅仅对 10 个数字、26 个大小写英文字母以及一些特殊字符进行了编码。 ASCII 码做多只能表示 256 个符号,每个字符只需要占用 1 个字节。
随着信息技术的发展,各国的文字都需要进行编码, 于是相继出现了 GB...
在做爬虫的时候,有时候需要爬写中文的内容。但是中文字符在某些场合下会转为 %xx 形式的 URL 字符。
比如:
%E7%BE%8E%E5%A5%B3
以上编码表示“美女”。
Python3 的 urllib 库,就可以对中文进行 URL编码和解码。
import urllib.parsecn = input("请输入中文:")
bfb = urllib.parse.quote(cn) # 转为 url 编码
print( bfb )
print( urllib.parse.unquote(bfb) ) # 解码
python---unicode编码转换unicode编码转换 >>> chr(20000)
>>北‘ord()与chr()用法以及区别ord()函数主要用来返回对应字符的ascii码,chr()主要用来表示ascii码对应的字符他的输入时数字,可以用十进制,也可以用十六进制。
print ord(a)
#97
print chr(97)
#a
print chr(0x61)
#a例子1) #以上程序主要实现对字符串str1里面所有的字符,转换成ascii码中比他们...
1 # -*- coding:gbk -*-2 # 即使设置文件编码为gbk,下方定义的字符串s1依旧为unicode3 4 # 获取默认编码格式5 import sys6 print(sys.getdefaultencoding())7 # >>> utf-88 9 # 编码转换
10 # --------------python 2----------------
11 # utf-8 --> decode --> unicode
12 # unicode --> encode --> gbk
13
14 s = "你好"
15 # 无decode方法,由于python3默认unicode, utf-8为原本的字符集,传给decode识别
16 s_unicode ...
import requests
import json
import redef result_value_replace(result_value):#数字匹配不上返回-1try:non_decimal = re.compile(r'[^\d.]+')result_value = non_decimal.sub('', result_value)return float(result_value)except Exception:return -1def GetName(url):resp=requests.get(url);# text是获取文本,resp.json是获取jsonreturn resp.text;# a=open('C:\\Users\\10351\\Desktop\\abc.txt','r',encoding='utf-8')
# p...
str->bytes:encode编码
bytes->str:decode解码字符串通过编码成为字节码,字节码通过解码成为字符串。
>>> text = '我是文本'
>>> text
'我是文本'
>>> print(text)
我是文本
>>> bytesText = text.encode()
>>> bytesText
b'\xe6\x88\x91\xe6\x98\xaf\xe6\x96\x87\xe6\x9c\xac'
>>> print(bytesText)
b'\xe6\x88\x91\xe6\x98\xaf\xe6\x96\x87\xe6\x9c\xac'
>>> type(text)
<class 'str'>
>>> type(bytesText)
<class 'bytes'>
>>>...
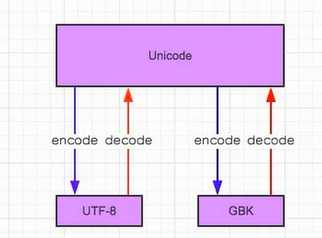
编码转换图(转自金角大王)编码转换需要先转换为Unicode编码,然后在转换为需要转换的编码:
如:UTF-8转GBK:UTF-8-->>(decode)Unicode-->>(encode)GBK