centos x64搭建 hadoop2.4.1 HA
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了centos x64搭建 hadoop2.4.1 HA,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含9485字,纯文字阅读大概需要14分钟。
内容图文

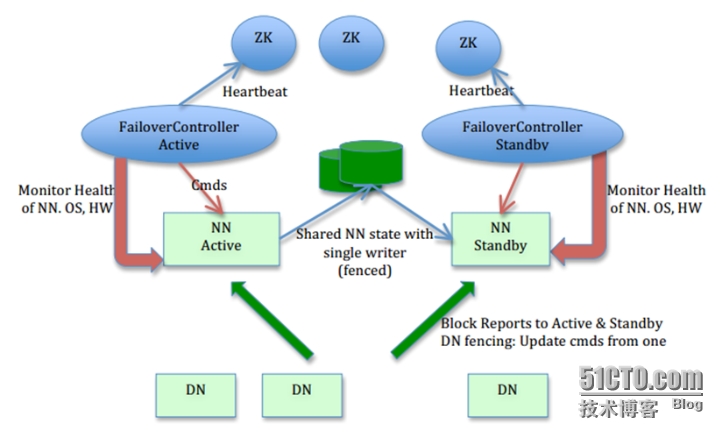
Hadoop HA 的实现方式
{kind=link}
上图大致架构包括:
1、
利用共享存储来在两个
NN
间同步
edits
信息。
以前的
HDFS
是
share nothing but NN
,现在
NN
又
share storage
,这样其实是转移了单点故障的位置,但中高端的存储设备内部都有各种
RAID
以及冗余硬件包括电源以及网卡等,比服务器的可靠性还是略有提高。通过
NN
内部每次元数据变动后的
flush
操作,加上
NFS
的
close-to-open
,数据的一致性得到了保证。
2、
DataNode
同时向两个
NN
汇报块信息。
这是让
Standby NN
保持集群最新状态的必需步骤。
3、
用于监视和控制
NN
进程的
FailoverController
进程
显然,我们不能在
NN
进程内进行心跳等信息同步,最简单的原因,一次
FullGC
就可以让
NN
挂起十几分钟,所以,必须要有一个独立的短小精悍的
watchdog
来专门负责监控。这也是一个松耦合的设计,便于扩展或更改,目前版本里是用
ZooKeeper(
以下简称
ZK)
来做同步锁,但用户可以方便的把这个
ZooKeeper FailoverController(
以下简称
ZKFC)
替换为其他的
HA
方案或
leader
选举方案。
4、 隔离(Fencing) ) ,防止 脑裂) ,就是保证在任何时候只有一个主 NN ,包括三个方面:
a) 共享存储 fencing ,确保只有一个 NN 可以写入 edits 。
b) 客户端 fencing ,确保只有一个 NN 可以响应客户端的请求。
c) DataNode fencing ,确保只有一个 NN 可以向 DN 下发命令,譬如删除块,复制块,等等。
部署环境介绍
系统环境: centos6.4 x86_64
Hadoop2.4.1
Jdk 1.7.0
hadoop环境:5台vmware虚拟机
Namenode1 192.168.1.10 zkfc
Namenode2 192.168.1.11 zkfc
Datanode1 192.168.1.12 Zookeeper
Datanode2 192.168.1.13 Zookeeper
Datanode3 192.168.1.14 Zookeeper
安装配置 jdk
#tar -xvf jdk-7u60-linux-x64.tar.gz #mv jdk1.7.0_60 /usr
在/etc/profile最后加入
export JAVA_HOME=/usr/jdk1.7.0_60 export JAVA_OPTS="-Xms1024m-Xmx1024m" export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$CLASSPATH export PATH=.:$PATH:$JAVA_HOME/bin
# source /etc/profile
# java -version
java version "1.7.0_60" Java(TM) SE Runtime Environment (build 1.7.0_60-b19) Java HotSpot(TM) 64-Bit Server VM (build 24.60-b09,mixed mode)
配置系统信息
/etc/hosts (所有机子上一样)
192.168.1.10 namenode1 192.168.1.11 namenode2 192.168.1.12 datanode1 192.168.1.13 datanode2 192.168.1.14 datanode3
添加ssh密钥认证,使hadoop所有几点间可以互相访问
# useradd hadoop
# passwd hadoop
# su – hadoop
$ ssh-keygen
$ ssh-copy-id -iid_rsa.pub namenode2
$ ssh-copy-id -iid_rsa.pub datanode1
$ ssh-copy-id -iid_rsa.pub datanode2
$ ssh-copy-id -iid_rsa.pub datanode3
Zookeeper 安装配置
Zookeeper是google的chubby的开源实现,是一个高效、可靠地协同工作系统。在此我们使用zookeeper监控实现namenode的故障自动切换。我们把zookeeper服务端程序安装在3台DN上,NN1和NN2上运行zkfc进程。
1、下载zookeeper-3.4.6.tar.gz
2、将tar包解压到指定目录
tar zxvfzookeeper-3.4.6.tar.gz
3、修改zookeeper配置, 将zookeeper安装目录下conf/zoo_sample.cfg重命名为zoo.cfg, 修改其中的内容:
# The number of milliseconds of each tick tickTime=2000 #服务器与客户端之间交互的基本时间单元(ms) # The number of ticks that the initial # synchronization phase can take initLimit=10 #zookeeper所能接受的客户端数量 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 #服务器和客户端之间请求和应答之间的时间间隔 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/hadoop/zookeeper #保证zookeeper数据,日志的路径 # the port at which the clients will connect clientPort=2181 #客户端与zookeeper相互交互的端口 server.1= datanode1:2888:3888 server.2= datanode2:2888:3888 server.3= datanode3:2888:3888 #server.A=B:C:D 其中A是一个数字,代表这是第几号服务器;B是服务器的IP地址;C表示服务器与群集中的“领导者”交换信息的端口;当领导者失效后,D表示用来执行选举时服务器相互通信的端口。 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. # #http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1
4、在配置的dataDir目录下创建一个myid文件,里面写入一个0-255之间的一个随意数字,每个zookeeper上这个文件的数字要是不一样的,这些数字应该是从1开始,依次写每个服务器。
5、分别启动所有的zookeeper
bin/zkServer.sh start
启动进程:QuorumPeerMain
6、使用客户端连接zookeeper测试是否成功
bin/zkCli.sh -server ip地址:clientPort
Hadoop 安装配置
注:x64系统下不能直接下载编译好的二进制包,官网上的二进制包是32环境下的,会出现无法加载本地块的情况,在官网下载源码包自己手动编译。
1、下载hadoop-2.4.1-src.tar.gz
2、编译过程略,完成后在hadoop-2.4.1-src/hadoop-dist/target目录下取包:
hadoop-2.4.1.tar.gz
3、解压hadoop-2.4.1.tar.gz 到目录/home/hadoop
tar -xvf hadoop-2.4.1.tar.gz -C /home/hadoop
4、修改环境变量:
vi /etc/profile exportHADOOP_HOME=/home/hadoop/hadoop exportHADOOP_COMMON_HOME=$HADOOP_HOME exportHADOOP_HDFS_HOME=$HADOOP_HOME exportHADOOP_MAPRED_HOME=$HADOOP_HOME exportHADOOP_YARN_HOME=$HADOOP_HOME exportHADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=.:$PATH:$JAVA_HOME/bin:/$HADOOP_HOME/bin:/$HADOOP_HOME/sbin
5、 修改hadoop安装目录下etc/hadoop/hadoop-env.sh 文件末尾添加java环境变量
exportJAVA_HOME=/usr/jdk1.7.0_60
6、修改hadoop安装目录下etc/hadoop/core-site.xml如下:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value> datanode1:2181, datanode2:2181,datanode3:2181</value> </property> <property> <name>hadoop.security.authorization</name> <value>false</value> </property> </configuration>
7、 修改hadoop安装目录下etc/hadoop/core-site.xml如下:
<configuration> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/name</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>namenode1:9000</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>namenode2:9000</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>namenode1:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>namenode2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>/opt/nameshare</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>ha.zookeeper.quorum</name> <value> datanode1:2181, datanode2:2181,datanode3:2181</value> </property> <property> <name>dfs.data.dir</name> <value>/opt/sdb/data</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
8、 修改hadoop安装目录下etc/hadoop/slave如下:
datanode1 datanode2 datanode3
9、在NN上配置nfs共享目录
nn1和nn2任意一个作为server,另一个为client
Server端
# rpm -qa |grep nfs
nfs-utils-lib-1.1.5-6.el6.x86_64
nfs-utils-1.2.3-39.el6_5.3.x86_64
如果没有需要安装
# yum -y install nfs-utils
Nfs里会有两个主程序rpcbind 和 nfs-utils (在 CentOS 5.x 以前这个软件称为 portmap,在 CentOS 6.x 之后才称为 rpcbind 的!)
# /etc/init.d/portmap start # /etc/init.d/nfs start # chkconfig --level 35 portmap on # chkconfig --level 35 nfs on # mkdir /opt/nameshare # cat /etc/exports /opt/nameshare 192.168.1.10/24(rw,no_root_squash,async) #红色表示允许挂载的ip # exportfs–v
10、在NN2上挂载NFS目录
Client 端
# showmount -e 192.168.1.10 #红色表示nfs服务器ip # mkdir /opt/nameshare # chmod 600 /opt/nameshare # mount 192.168.1.10:/opt/nameshare /opt/nameshare
df –h 可以查看到挂载信息
设置开机自动挂载,添加下边这行到/etc/fstab
192.168.1.10:/opt/namshare /opt/nameshare nfs defaults 0 0
# mount –a
11、在NN上设置nfs共享目录所属权限给用户hadoop
chown -R hadoop.hadoop /opt/nameshare
12、分别在3个DN上建立数据目录
mkdir -p /opt/sdb/data chown -R hadoop.hadoop /opt/sdb
13、在NN和NN1上建立目录
mkdir /opt/name chown -R hadoop.hadoop /opt/name
14、复制NN上配置好的hadoop目录到另外4个节点
scp -r /home/hadoop/hadoop-2.4.1 namenode2:/home/hadoop scp -r /home/hadoop/hadoop-2.4.1 datanode1:/home/hadoop scp -r /home/hadoop/hadoop-2.4.1 datanode2:/home/hadoop scp -r /home/hadoop/hadoop-2.4.1 datanode3:/home/hadoop
15、格式化namenode,首先在NN上执行:
hadoop namenode -format –clusterid mysluster
16、格式化完成后,把NN节点上/opt/name目录下生成的文件完全拷贝到NN1节
点的/opt/name目录里。
cd /opt/name scp -r * namenode2:/opt/name
17、格式化zfkc,在zookeeper客户端NN、NN1上执行
bin/hdfs zkfc –formatZK
18、启动hadoop分布式系统
sbin/start-dfs.sh
启动成功后NN和NN1上启动进程:
NameNode
DFSZKFailoverController
DN上启动进程:
DataNode
QuorumPeerMain
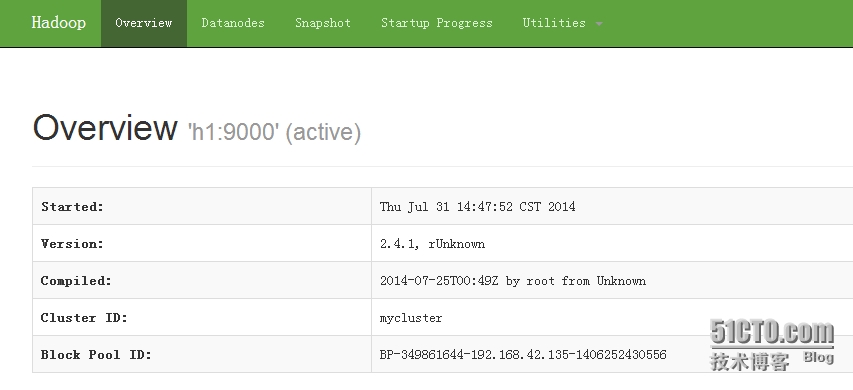
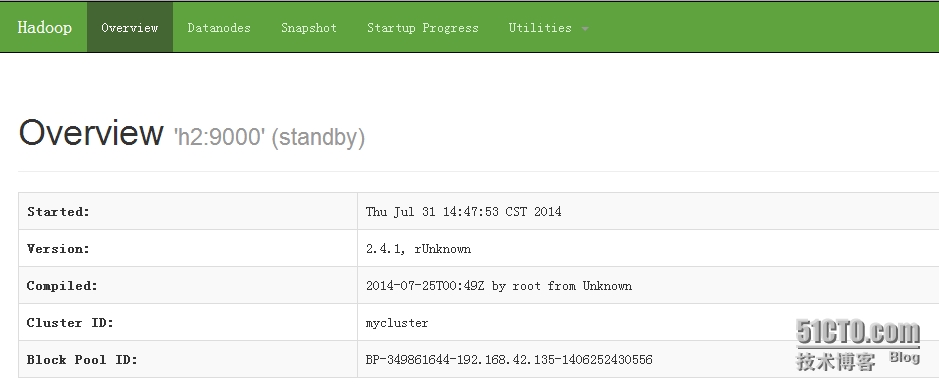
19、通过web查看hdfs启动情况
NN1 http://192.168.1.10:50070
{kind=link}
{kind=link}
上图可看出两个namenode一主一备都启动成功。
20、HDFS(HA)的管理
使用如下命令设置Active 节点 (手动方式)
bin/hdfs haadmin –DFSHAadmin –transitionToActive nn1
如果让nn2 成为变为active nn1 变为standby ,则
bin/hdfs haadmin -DFSHAadmin -failover nn1 nn2
如果失败(is not ready to become active) 则
bin/hdfs haadmin -DFSHAadmin -failover --forceactive nn1 nn2
具体参照bin/hdfs haadmin命令
21、验证高可用是否成功
当前NN1处于Active状态,手动停掉NN1上的namenode进程
hadoop-daemon.sh stop namenode
再次查看NN1和NN2的状态,可以看到NN2变为Active。
手动重启启动NN1上的namenode进程后,发现NN上的现在为Standby状态,高可用成功。
随后会附上hadoop2.4.1 x86_64环境下编译完成的二进制文件。
本文出自 “央了个样” 博客,请务必保留此出处http://yayang.blog.51cto.com/826316/1533379
原文:http://yayang.blog.51cto.com/826316/1533379
内容总结
以上是互联网集市为您收集整理的centos x64搭建 hadoop2.4.1 HA全部内容,希望文章能够帮你解决centos x64搭建 hadoop2.4.1 HA所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。