基于Zookeeper的使用详解
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了基于Zookeeper的使用详解,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2280字,纯文字阅读大概需要4分钟。
内容图文

更多内容请查看zookeeper官网
Zookper: 一种分布式应用的协作服务Zookper是一种分布式的,开源的,应用于分布式应用的协作服务。它提供了一些简单的操作,使得分布式应用可以基于这些接口实现诸如同步、配置维护和分集群或者命名的服务。Zookper很容易编程接入,它使用了一个和文件树结构相似的数据模型。可以使用Java或者C来进行编程接入。
众所周知,分布式的系统协作服务很难有让人满意的产品。这些协作服务产品很容易陷入一些诸如竞争选择条件或者死锁的陷阱中。Zookper的目的就是将分布式服务不再需要由于协作冲突而另外实现协作服务。
设计目标 Zookeeper是简易的Zookeeper通过一种和文件系统很像的层级命名空间来让分布式进程互相协同工作。这些命名空间由一系列数据寄存器组成,我们也叫这些数据寄存器为znodes。这些znodes就有点像是文件系统中的文件和文件夹。和文件系统不一样的是,文件系统的文件是存储在存储区上的,而zookeeper的数据是存储在内存上的。同时,这就意味着zookeeper有着高吞吐和低延迟。
Zookeeper实现了高性能,高可靠性,和有序的访问。高性能保证了zookeeper能应用在大型的分布式系统上。高可靠性保证它不会由于单一节点的故障而造成任何问题。有序的访问能保证客户端可以实现较为复杂的同步操作。
Zookeeper是可重用的ZooKeeper Service
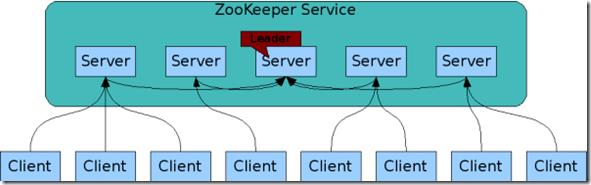
组成Zookeeper的各个服务器必须要能相互通信。他们在内存中保存了服务器状态,也保存了操作的日志,并且持久化快照。只要大多数的服务器是可用的,那么Zookeeper就是可用的。
客户端连接到一个Zookeeper服务器,并且维持TCP连接。并且发送请求,获取回复,获取事件,并且发送连接信号。如果这个TCP连接断掉了,那么客户端可以连接另外一个服务器。
Zookeeper是有序的Zookeeper使用数字来对每一个更新进行标记。这样能保证Zookeeper交互的有序。后续的操作可以根据这个顺序实现诸如同步操作这样更高更抽象的服务。
Zookeeper是高效的Zookeeper的高效更表现在以读为主的系统上。Zookeeper可以在千台服务器组成的读写比例大约为10:1的分布系统上表现优异。
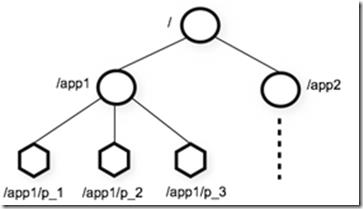
数据结构和分等级的命名空间Zookeeper的命名空间的结构和文件系统很像。一个名字和文件一样使用/的路径表现,zookeeper的每个节点都是被路径唯一标识
ZooKeeper's Hierarchical Namespace
下图显示了ZooKeeper服务的高级组件服务。除了请求处理器,Zookeeper服务器组的每个服务器复制他们自己的每个组件。
ZooKeeper Components
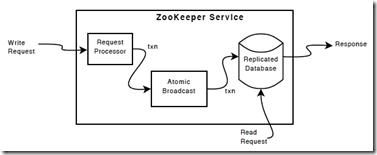
replicated database是一个存储在内存中的包含整个数据树的结构。所有的更新操作都做日志到硬盘上了。并且写操作在作用在数据库的时候会序列化存储到硬盘上。
每个ZooKeeper服务器都连接了许多个客户端。客户端连接到一个服务器来提交请求。
内容总结
以上是互联网集市为您收集整理的基于Zookeeper的使用详解全部内容,希望文章能够帮你解决基于Zookeeper的使用详解所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。