实例详解Python实现简单网页图片抓取
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了实例详解Python实现简单网页图片抓取,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2940字,纯文字阅读大概需要5分钟。
内容图文
 本文主要介绍了Python实现简单网页图片抓取完整代码实例,具有一定借鉴价值,需要的朋友可以参考下。
本文主要介绍了Python实现简单网页图片抓取完整代码实例,具有一定借鉴价值,需要的朋友可以参考下。利用python抓取网络图片的步骤是:
1、根据给定的网址获取网页源代码
2、利用正则表达式把源代码中的图片地址过滤出来
3、根据过滤出来的图片地址下载网络图片
以下是比较简单的一个抓取某一个百度贴吧网页的图片的实现:
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' %x) #打开imglist中保存的图片网址,并下载图片保存在本地
x = x + 1
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
getImg(html)#从网页源代码中分析并下载保存图片进一步对代码进行了整理,在本地创建了一个“图片”文件夹来保存图片
# -*- coding: utf-8 -*-
# feimengjuan
import re
import urllib
import urllib2
import os
#抓取网页图片
#根据给定的网址来获取网页详细信息,得到的html就是网页的源代码
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#创建保存图片的文件夹
def mkdir(path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 Flase
isExists = os.path.exists(path)
if not isExists:
print u'新建了名字叫做',path,u'的文件夹'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已经存在
print u'名为',path,u'的文件夹已经创建成功'
return False
# 输入文件名,保存多张图片
def saveImages(imglist,name):
number = 1
for imageURL in imglist:
splitPath = imageURL.split('.')
fTail = splitPath.pop()
if len(fTail) > 3:
fTail = 'jpg'
fileName = name + "/" + str(number) + "." + fTail
# 对于每张图片地址,进行保存
try:
u = urllib2.urlopen(imageURL)
data = u.read()
f = open(fileName,'wb+')
f.write(data)
print u'正在保存的一张图片为',fileName
f.close()
except urllib2.URLError as e:
print (e.reason)
number += 1
#获取网页中所有图片的地址
def getAllImg(html):
#利用正则表达式把源代码中的图片地址过滤出来
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = imgre.findall(html) #表示在整个网页中过滤出所有图片的地址,放在imglist中
return imglist
#创建本地保存文件夹,并下载保存图片
if __name__ == '__main__':
html = getHtml("http://tieba.baidu.com/p/2460150866")#获取该网址网页详细信息,得到的html就是网页的源代码
path = u'图片'
mkdir(path) #创建本地文件夹
imglist = getAllImg(html) #获取图片的地址列表
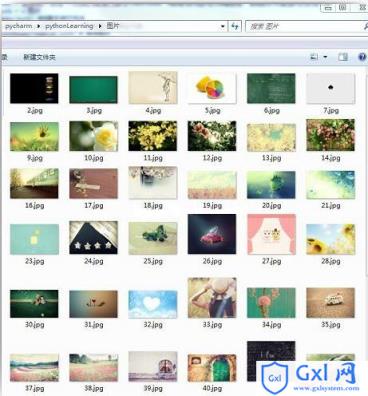
saveImages(imglist,path) # 保存图片结果在“图片”文件夹下保存了几十张图片,如截图:
相关推荐:
PHP简单网页图片抓取类
如何把这里的图片抓取到本地
PHP+Ajax远程图片抓取器下载的例子
以上就是实例详解Python实现简单网页图片抓取的详细内容,更多请关注Gxl网其它相关文章!
内容总结
以上是互联网集市为您收集整理的实例详解Python实现简单网页图片抓取全部内容,希望文章能够帮你解决实例详解Python实现简单网页图片抓取所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。