首页 / PYTHON / python动态网页批量爬取
python动态网页批量爬取
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python动态网页批量爬取,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4828字,纯文字阅读大概需要7分钟。
内容图文
 四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页。我使用的是学信网,好了,网站截图如下:
四六级成绩查询网站我所知道的有两个:学信网(http://www.chsi.com.cn/cet/)和99宿舍(http://cet.99sushe.com/),这两个网站采用的都是动态网页。我使用的是学信网,好了,网站截图如下:

网站的代码如下:
由图中可以看出表单提交的链接为/cet/query,即:http://www.chsi.com.cn/cet/query,好了,填写表单和结果如下:


但是,点击查看源代码之后发现,没有成绩,即代码仍是上面那个,之后按F12查看代码:
姓名: XXXX 学校: XXXXXX 考试类别: 英语四级 准考证号: 120135151100101 总分: 考试时间: 2015年06月 403
听力: 132
阅读: 147
写作与翻译: 124
该代码显示了成绩,可以知道,该网站使用的是动态网页,用的JavaScript或者Ajax.js还是其他的我就不知道了0.0。上面为需求。
前言:使用过BeautifulSoup爬取过,但是BeautifulSoup是爬取不了动态网页的,上各种论坛找各种资料,用了n种东西,scapy,pyqt等等,走了真心不少弯路,不是不行,应该是我不会用,最终用了selenium和phantomjs,这两个应该也是目前最流行的爬虫模块了吧。
一、导入selenium和phantomjs
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='D:\phantomjs-2.1.1-windows\phantomjs.exe')
driver.get(url)
driver.find_element_by_id('zkzh').send_keys(i)
driver.find_element_by_id('xm').send_keys(xm)
driver.find_elements_by_tag_name('form')[1].submit()
代码说明:
3.selenium可以加载很多驱动,比如Chrome、FireFox等,这里需要有这两个浏览器和驱动才行,折腾了一下,网上说Phantomjs是较好的了
5、6、7分别是准考证号,姓名和提交
二、字符处理
提交之后就可以直接查找了:
print driver.find_element_by_xpath("//tr[3]/td[1]").text
print driver.find_element_by_xpath("//tr[6]/td[1]").text
代码说明:
1.查看姓名
2.查看分数及其具体成绩
打印之后为:
姓名 听力 阅读 写作
之后要对分数进行字符串处理,选取各部分的数字,这里我们采用re模块:
import re m = re.findall(r'(\w*[0-9]+)\w*', chuli2)
其中m是数组,输出的是["403","132","147","142"]
三、数据库
我们学校也不知说很渣还是人性化,反正公布了全校的四六级准考证号,当然,是excel的,需要导入mysql数据库,打开Excel之后,我发现微软大法和Oracle真是牛,Excel365居然有mysql workbench连接部分。
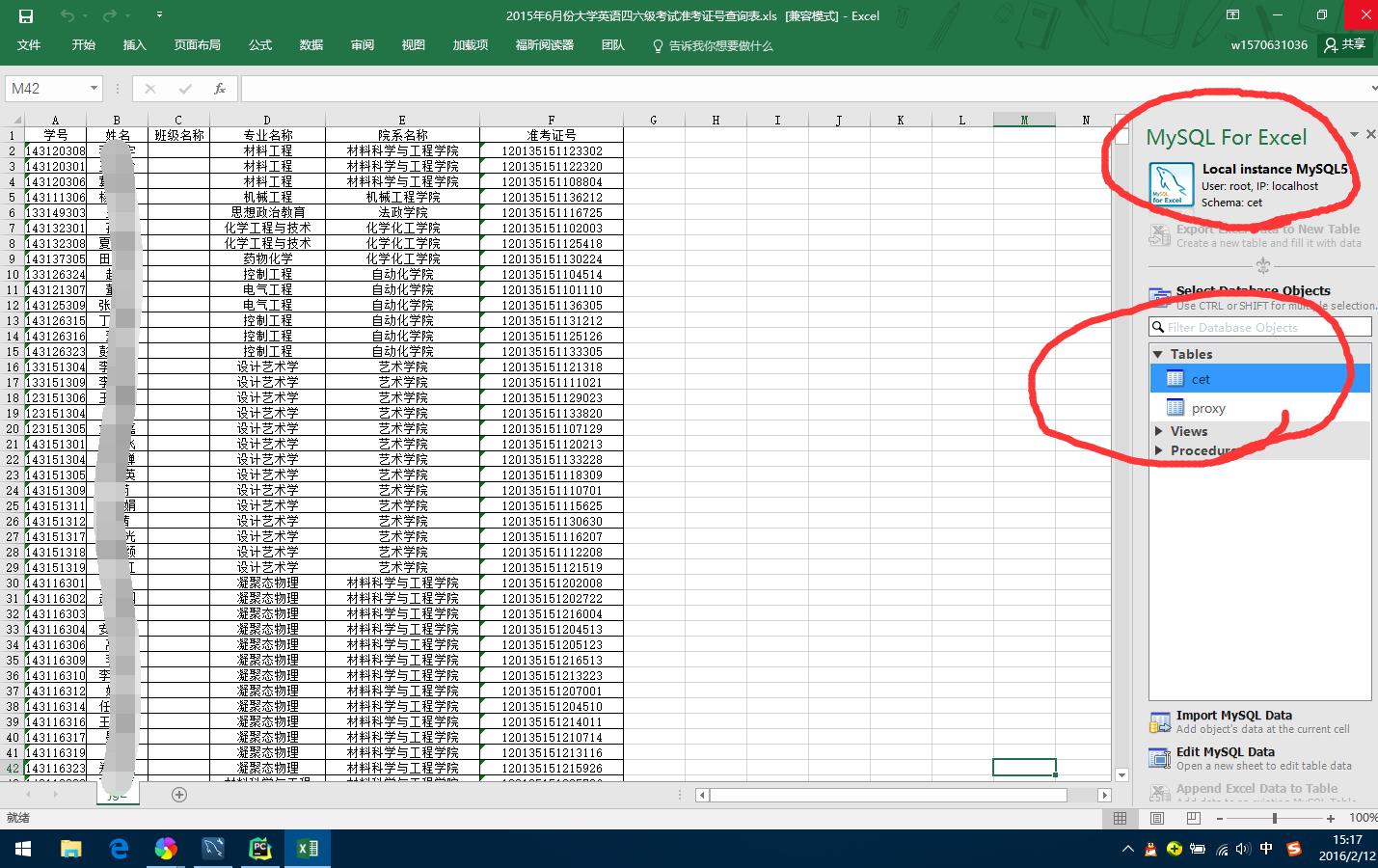
数据库代码如下:
import MySQLdb
conn = MySQLdb.Connect(host='localhost', user='root', passwd='root', db='cet', port=3306, charset='utf8')
cur = conn.cursor()
curr = conn.cursor()
cur.execute("select name from cet.cet where zkzh=(%s)" % i)
xm = cur.fetchone()[0]
print "Name is " + xm
sqltxt = "update cet.cet set leibie=(%s),zongfen=(%s),tingli=(%s),yuedu=(%s),xiezuo=(%s) WHERE zkzh=(%s)" % (
ss, m[0], m[1], m[2], m[3], i)
cur.execute(sqltxt)
conn.commit()
cur.close()
conn.close()
代码说明:
3.python连接数据库代码
6.连接数据库取得姓名部分
9.这行我好无语啊,使用‘“+ss+”'这样的写法一直报错,最终找了半天资料,这个写法我不太喜欢,但是凑合着用吧。
12.记得一定要提交事务!!!commit()!!!不然是没有效果的
四、使用代理服务器(保留以后写)
运行了一段时间之后,大概抓了几百人的吧,然后就出现要求验证码了,解决办法只能处理验证码或者使用代理服务器了,这部分继续加强学习再弄出来了↖(^ω^)↗
五、源代码和效果
# encoding=utf8
import MySQLdb
import re
import time
from selenium import webdriver
# connect mysql,get zkxh and xm
conn = MySQLdb.Connect(host='localhost', user='root', passwd='root', db='cet', port=3306, charset='utf8')
cur = conn.cursor()
curr = conn.cursor()
url = 'http://www.chsi.com.cn/cet/query'
def kaishi(i):
print i,
print " start"
try:
cur.execute("select name from cet.cet where zkzh=(%s)" % i)
xm = cur.fetchone()[0]
print "Name is " + xm
driver = webdriver.PhantomJS(executable_path='D:\phantomjs-2.1.1-windows\phantomjs.exe')
driver.get(url)
driver.find_element_by_id('zkzh').send_keys(i)
driver.find_element_by_id('xm').send_keys(xm)
driver.find_elements_by_tag_name('form')[1].submit()
driver.set_page_load_timeout(10)
leibie = driver.find_element_by_xpath("//tr[3]/td[1]").text
leibie2 = str(leibie.encode("utf-8"))
ss = ""
if leibie2.decode("utf-8") == '英语四级'.decode("utf-8"):
ss = 4
else:
ss = 6
# zongfen = driver.find_element_by_xpath("//tr[6]/th[1]").text
# print zongfen
# print "===="
chuli = driver.find_element_by_xpath("//tr[6]/td[1]").text
print chuli
chuli2 = str(chuli.encode("utf-8"))
m = re.findall(r'(\w*[0-9]+)\w*', chuli2)
sqltxt = "update cet.cet set leibie=(%s),zongfen=(%s),tingli=(%s),yuedu=(%s),xiezuo=(%s) WHERE zkzh=(%s)" % (
ss, m[0], m[1], m[2], m[3], i)
cur.execute(sqltxt)
conn.commit()
print str(i) + " finish"
except Exception, e:
print e
driver.close()
time.sleep(10)
kaishi(i)
# for j1 in range(1201351511001, 1201351512154):
for j1 in range(1201351511007, 1201351512154):
for j2 in range(0, 3):
for j3 in range(0, 10):
j = str(j1) + str(j2) + str(j3)
if str(j2) + str(j3) == "00":
print "0.0"
elif str(j2) + str(j3) == "29":
kaishi(str(j1) + str(j2) + str(j3))
j4 = str(j1) + "30"
kaishi(j4)
else:
kaishi(j)
print "END!!!"
cur.close()
conn.close()
总结:python的字符串处理细节真的很重要,动不动就输出错误,还有IDE的编码不一样,记得还有个系统编码,字符编码,环境编码,数据库编码等等都要一致。
以上就是本文的全部内容,希望对大家的学习有所帮助。
内容总结
以上是互联网集市为您收集整理的python动态网页批量爬取全部内容,希望文章能够帮你解决python动态网页批量爬取所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。