Spark SQL用UDF实现按列特征重分区
浪尖 浪尖聊大数据 欢迎关注,浪尖公众号,bigdatatip,建议置顶。
这两天,球友又问了我一个比较有意思的问题:解决问题之前,要先了解一下Spark 原理,要想进行相同数据归类到相同分区,肯定要有产生shuffle步骤。比如,F到G这个shuffle过程,那么如何决定数据到哪个分区去的呢?这就有一个分区器的概念,默认是hash分区器。
假如,我们能在分区这个地方着手的话肯定能实现我们的目标。
那么,...
源构建,例如:结构化数据文件(JSON文件,xml文件),Hive中的表,外部数据库或现有RDD。
2、RDD与DataFrames的对比
spark(三)spark sql标签:ram pac source html http uid 关系型数据库 taf 数据 本文系统来源:http://www.cnblogs.com/liuwei6/p/6675230.html
一、RDD转DataFrame方法一:通过 case class 创建 DataFramesimport org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContextobject TestDataFrame {def main(args: Array[String]): Unit = {/*** 1、初始化 spark config*/val conf = new SparkConf().setAppName("TestDataFrame").setMaster("local"); /*** 2、初始化spark context*/val sc = new SparkContext(conf);/*** ...
参数优化 合理的参数调优,能有效的优化部分SQL性能。
set spark.sql.adaptive.skewedJoin.enabled=true; --开启自动处理 Join 时数据倾斜 set spark.sql.adaptive.skewedPartitionMaxSplits=20; --Join 时数据倾斜最大切分Partition数 set spark.sql.adaptive.skewedPartitionRowCountThreshold=10000000; --按行数开启自动处理 Join 时数据倾斜阈值,1千万行 set spark.sql.adaptive.skewedPartitionSizeThreshold=134217728; --...
职工姓名,职工id,职工性别,职工年龄,入职年份,职位,所在部门id
Michael,1,male,37,2001,developer,2Andy,2,female,33,2003,manager,1Justin,3,female,23,2013,recruitingspecialist,3John,4,male,22,2014,developer,2Herry,5,male,27,2010,developer,1Brewster,6,male,37,2001,manager,2Brice,7,female,30,2003,manager,3Justin,8,male,23,2013,recruitingspecialist,3John,9,male,22,2014,developer,1Herry,10,female,27,2010,rec...
1. 连接mysql
首先需要把mysql-connector-java-5.1.39.jar 拷贝到 spark 的jars目录里面;
scala> import org.apache.spark.sql.SQLContextimport org.apache.spark.sql.SQLContext
scala> val sqlContext=new SQLContext(sc)warning: there was one deprecation warning; re-run with -deprecation for detailssqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@3a649f9a
scala> sqlContext.read...
针对hive on mapreduce
1:我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并:
参数详细内容可参考官网:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties1
2
3
4hive.merge.mapfiles 在 map-only job后合并文件,默认true
hive.merge.mapredfiles 在map-reduce job后合并文件,默认false
hive.merge.size.per.task 合并后每个文件的大小,默认256000000
hive.merge.smallfiles.avgsize ...
一、JDBC数据源实战Spark SQL支持使用JDBC从关系型数据库(比如MySQL)中读取数据。读取的数据,依然由DataFrame表示,可以很方便地使用Spark Core提供的各种算子进行处理。这里有一个经验之谈,实际上用Spark SQL处理JDBC中的数据是非常有用的。比如说,你的MySQL业务数据库中,有大量的数据,比如1000万,然后,你现在需要编写一个程序,对线上的脏数据某种复杂业务逻辑的处理,甚至复杂到可能涉及到要用Spark SQL反复查询Hive中...
Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
(1) 查询所有数据;
(2) 查询所有数据,并...
(1)骨灰级案例--UDTF求wordcount
数据格式:每一行都是字符串并且以空格分开。代码实现:
object SparkSqlTest {def main(args: Array[String]): Unit = {//屏蔽多余的日志Logger.getLogger("org.apache.hadoop").setLevel(Level.WARN)Logger.getLogger("org.apache.spark").setLevel(Level.WARN)Logger.getLogger("org.project-spark").setLevel(Level.WARN)//构建编程入口val conf: SparkConf = new SparkConf()conf.setAppNam...
文章目录
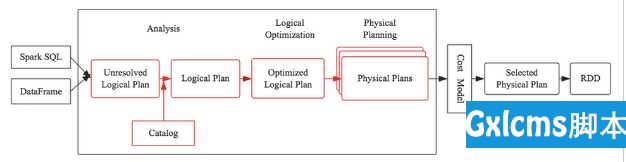
TreesRulesSpark SQL中使用CatalystAnalysis逻辑优化(Logical Optimizations)物理计划(Physical Planning)代码生成(Code Generation)参考
此篇文章,翻译之Databricks Blog中的一篇文章——Deep Dive into Spark SQL’s Catalyst Optimizer。
Spark SQL的核心是Catalyst优化器,它以一种与众不同的方式利用高级编程语言特性来构建可扩展的查询优化器。
Catalyst是一个基于Scala的函数式编程结构设计的可扩展优化器。...
scala> case class offices(office:Int,city:String,region:String,mgr:Int,target:Double,sales:Double)defined class officesscala> val rddOffices=sc.textFile("/user/hive/warehouse/orderdb.db/offices/offices.txt").map(_.split("\t")).map(p=>offices(p(0).trim.toInt,p(1),p(2),p(3).trim.toInt,p(4).trim.toDouble,p(5).trim.toDouble))rddOffices: org.apache.spark.rdd.RDD[offices] = MapPartitionsRDD[3] at map at...
Spark SQL原理解析前言:
Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述
这一次要开始真正介绍Spark解析SQL的流程,首先是从Sql Parse阶段开始,简单点说,这个阶段就是使用Antlr4,将一条Sql语句解析成语法树。
可能有童鞋没接触过antlr4这个内容,推荐看看《antlr4权威指南》前四章,看完起码知道antlr4能干嘛。我这里就不多介绍了。
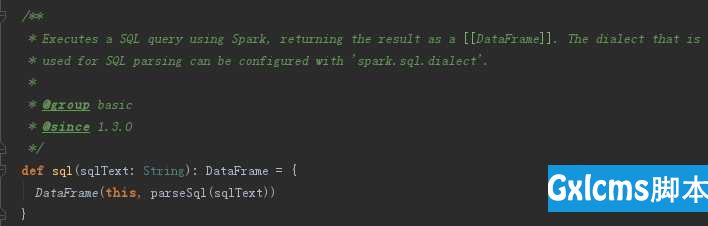
这篇首先先介绍调用spark.sql()时候的流程,再看看antlr4在这个其中的主要功能,最后再...
rows selected (22.709 seconds)
2、非broadcast join
(1)DAG
(2)执行时间122 rows selected (55.512 seconds) 对于broadcast join模式,会将小于spark.sql.autoBroadcastJoinThreshold值(默认为10M)的表广播到其他计算节点,不走shuffle过程,所以会更加高效。一、Spark源码解析 源码中的基本流程如下所示:1、org.apache.spark.sql.execution.SparkStrategies类 决定是否使用broadcast join的逻辑在Spark...
。以及2个商业化选择Oracle Big Data SQL 和IBM Big SQL,IBM 尚未将后者更名为“Watson SQL”。
(有读者问:Druid 呢?我的回答是:检查后,我同意Druid 属于这一类别。)
使用SQL 引擎一词是有点随意的。例如Hive 不是一个引擎,它的框架使用MapReduce、TeZ 或者Spark 引擎去执行查询,而且它并不运行SQL,而是HiveQL,一种类似SQL 的语言,非常接近SQL。“SQL-in-Hadoop” 也不适用,虽然Hive 和Impala 主要使用Hadoop,但是Sp...