高性能MySQL-特定类型查询的优化详解
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了高性能MySQL-特定类型查询的优化详解,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1881字,纯文字阅读大概需要3分钟。
内容图文

这一节主要是对于一些特定类型的优化查询:
(1)count查询优化;
(2)关联查询
(3)子查询
(4)GROUP BY 和 DISTINCT优化
(5)LIMIT 分页优化
count查询优化
COUNT()聚合函数的作用:
(1)统计某一个列值的数量,也可以统计行数。需要注意的是统计列值时要求列值是非空的(不统计NULL)
(2)统计结果集的行数。当列值不可能为空时统计的就是表的行数。但是为了确保一定要使用COUNT()获取结果集的行数。通配符会直接忽略所有列值直接计算行数,进行优化。
对于MyISAM存储引擎,当在单表中没有限定where查询条件时COUNT(*)是非常快的,因为MyISAM本身已经存了这个行数总值。当存在where限定条件,也是需要进行查询统计的。
下面给出一个简单优化的使用示例:
(1)优化一:
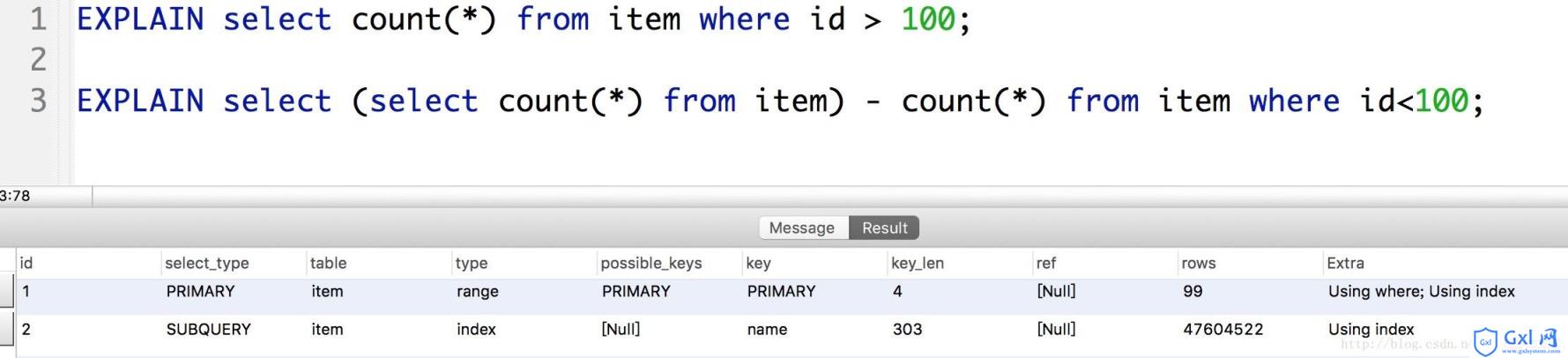
可知如果我们直接查 id>100 的记录,涉及到的有两千多万行记录扫描。但是由于COUNT()特性,我们可以用 count() - (id<100)的做法,这样扫描的行就只有100行了。效率大大提高。
(2)优化二:
此外除了还有一种优化方法就是利用覆盖索引了。
关联查询优化
(1)确保ON 或则USING 子句的列上有索引。创建索引时就要考虑关联的顺序,当表A和表B用列c关联的时候,如果优化器关联顺序是B、A,就只需要在表A上建立索引。没用的索引会占用存储
(2)确保任何Group by 和 order by操作中表达式只涉及到一个表中的列。这样MySQL就可能使用索引优化
子查询
尽量少用子查询,因为子查询会产生临时表;除非像count(*)临时表很小的。
GROUP BY 和 DISTINCT优化
GROUP BY 和 DISTINCT的优化最有效的就是使用索引。
当无法使用索引时,group by使用两种策略完成:临时表或则文件排序来做分组。
所有对于分组的列一定要建立索引。比如:
select product, count(*) from orders group by product;
这样的一个查询,对product要建立索引。
LIMIT分页优化
进行分页操作时,通常都会通过偏移量来查询某些数据。然后再加上解释的order by,性能一般都不错。
对于order by的列 一定要加上索引。
但是对于limit 10000, 10 这样检索目标10条记录必须先先查询前面的10000条记录。代价很高,这种时候优化最简单办法就是使用覆盖索引。
以上就是高性能MySQL-特定类型查询的优化详解的详细内容,更多请关注Gxl网其它相关文章!
内容总结
以上是互联网集市为您收集整理的高性能MySQL-特定类型查询的优化详解全部内容,希望文章能够帮你解决高性能MySQL-特定类型查询的优化详解所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。