MySQL分表实现上百万上千万记录分布存储的批量查询设计模式详解
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了MySQL分表实现上百万上千万记录分布存储的批量查询设计模式详解,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1727字,纯文字阅读大概需要3分钟。
内容图文

我们知道可以将一个海量记录的 MySQL 大表根据主键、时间字段,条件字段等分成若干个表甚至保存在若干服务器中。
唯一的问题就是跨服务器批量查询麻烦,只能通过应用程序来解决。谈谈在Java中的解决思路。其他语言原理类似。
这里说的分表不是 MySQL 5.1 的 partition,而是人为把一个表分开存在若干表或不同的服务器。
1. 应用程序级别实现
见示意图
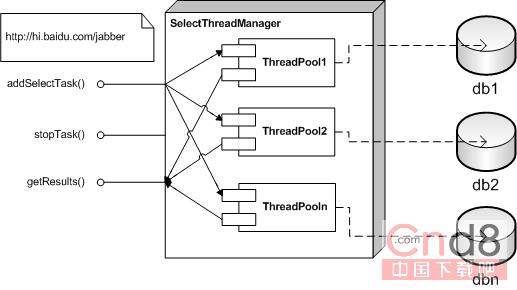
electThreadManager 分表数据查询管理器
它为分表的每个database or server 建立一个 thread pool
addTask() - 添加任务
stopTask() - 停止任务
getResult() - 获取执行结果
最快的执行时间 = 最慢的 MySQL 节点查询消耗时间
最慢的执行时间 = 超时时间
某个 ThreadPool 忙时候处理流程
1. 假如 ThreadPoolN 非常忙,(也意味 DB N 非常忙);
2. 新的查询任务到来,addTask(), 新的任务的一个thread加到ThreadPoolN任务排队中
3. 外层应用已经获得其他 thread 返回结果,继续等待
4. 外层应用等待超时的时间到,调用 stopTask() 设置该任务全部 thread 中的停止标志, 外层应用返回。
5. 若干时间后,ThreadPoolN取到该排队 Thread, 因为设置了停止位,线程直接运行完成。
2. JDBC 层实现
做一个 JDBC Driver 的包装,拦截 PreparedStatement, Statement 的 executeQuery()
然后调用 SelectThreadManager 完成
3. MySQL partition
MySQL 5.1 的 partition 功能由于单张表的数据跨文件,批量查询时候同样存在上述问题,不过它是在 MySQL 内部实现的,不需要外部调用者关心。其查询实现的原理应该大致类似。
但 partition 只解决了 IO 的瓶颈,并不能解决 CPU 计算的瓶颈,因此无法代替传统的手工分表方式。
您可能感兴趣的文章:
- 解析mysql中:单表distinct、多表group by查询去除重复记录
- mysql 开启慢查询 如何打开mysql的慢查询日志记录
- mysql中RAND()随便查询记录效率问题和解决办法分享
- mysql 查询第几行到第几行记录的语句
- MySQL随机查询记录的效率测试分析
- MySQL 查询某个字段不重复的所有记录
- 使用mysql的disctinct group by查询不重复记录
- 使用distinct在mysql中查询多条不重复记录值的解决办法
- Mysql查询最近一条记录的sql语句(优化篇)
内容总结
以上是互联网集市为您收集整理的MySQL分表实现上百万上千万记录分布存储的批量查询设计模式详解全部内容,希望文章能够帮你解决MySQL分表实现上百万上千万记录分布存储的批量查询设计模式详解所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。