首页 / 爬虫 / python爬虫之requests.exceptions.ProxyError: HTTPSConnectionPool(host='www.xxxx.com', port=443
python爬虫之requests.exceptions.ProxyError: HTTPSConnectionPool(host='www.xxxx.com', port=443
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python爬虫之requests.exceptions.ProxyError: HTTPSConnectionPool(host='www.xxxx.com', port=443,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1478字,纯文字阅读大概需要3分钟。
内容图文

在测试某api时,偶然的发现一个很奇怪的现象
如下:
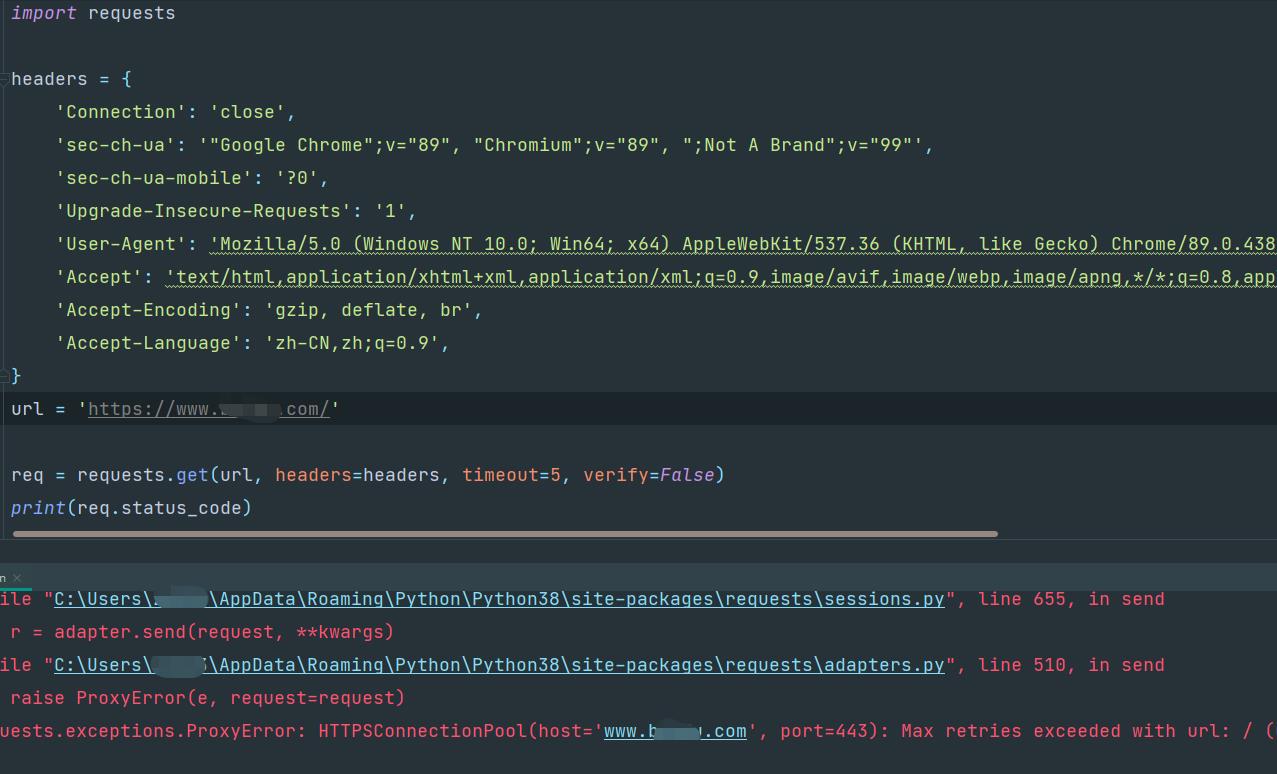
报的啥错呢:
requests.exceptions.ProxyError: HTTPSConnectionPool(host='www.xxxx.com', port=443): Max retries exceeded with url: / (Caused by ProxyError('Cannot connect to proxy.', timeout('_ssl.c:1108: The handshake operation timed out')))
根据我的经验,看到后面的Max retries exceeded with..... 之类的我都大概知道啥原因,就是请求重试量太多了,可是此时此刻我就一段同步代码啊,后面没内容了,而且也只请求了一次,headers里的Connection也是close而非keep-alive,verfiy也设置的false,
这咋回事呢
我又把https改成http:
结果还是如上,卧槽,这啥情况,我就纳了闷了,网上有朋友说需要安装这个那个的啥库:
pip install cryptography
pip install pyOpenSSL
pip install certifi
装完之后并没有什么卵用
升级requests看看呢,升级完还是不行
我换用aiohttp和httpx,也还是不行
这就很骚了。
最后突然想起有个东西:
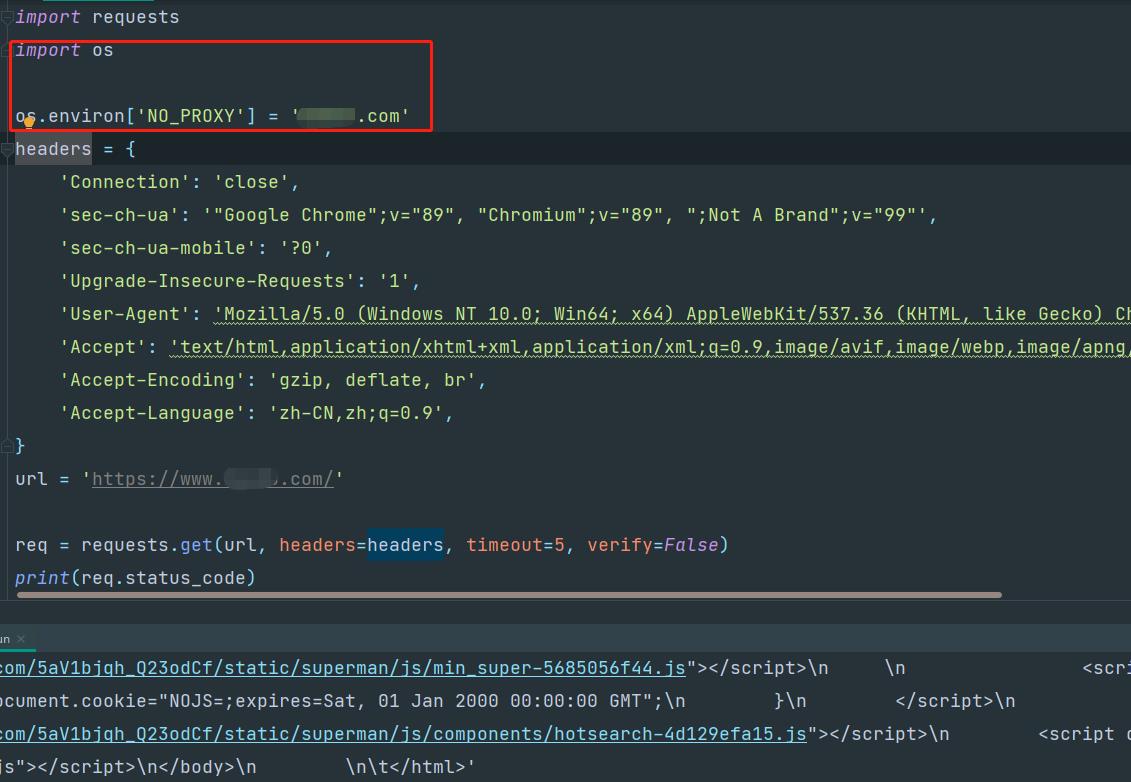
哎,卧槽,还真的可以,os.environ['NO_PROXY']设置为你的目标网址的域名即可。
如果要设置多个域名:

我查了下这个os.environ,意思就是设置系统变量的,['NO_PROXY']的意思就是指定某个域名别用代理去处理,哎,卧槽,我没加代理啊,我那个requests.get参数都没有用proxies这个参数。突然我看到开了的窗口,有这么个东西:

fiddler,卧槽,就是它了,关闭fiddler之后确实可以正常处理了,这就很骚了。
但是不对啊,我之前测试的时候,为了对比实际请求和爬虫请求的差异,开上fiddler抓包来对比参数,不是可以的吗,为啥这里就是不行。
最后我发现了,fiddler版本问题,之前我重装了系统,然后网上随便找了个安装包装上我就不管了,也没测试有没有问题
内容总结
以上是互联网集市为您收集整理的python爬虫之requests.exceptions.ProxyError: HTTPSConnectionPool(host='www.xxxx.com', port=443全部内容,希望文章能够帮你解决python爬虫之requests.exceptions.ProxyError: HTTPSConnectionPool(host='www.xxxx.com', port=443所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。