【python网络数据采集】再来碗BeautifulSoup汤!
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了【python网络数据采集】再来碗BeautifulSoup汤!,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1938字,纯文字阅读大概需要3分钟。
内容图文

上一篇我带你品尝了beautifulsoup,这次咱作为干饭人再来一碗BeautifulSoup汤!
首先抛出一个问题:当我们要采集一个网页上特定css样式的内容时,我们怎样操作呢?
首先我们要大致了解一下html的基础知识。

这是一张html structure的示意图,每个html页面均遵循此格式。
咱们可以看到一个页面中有许多tag(标签),我们以书中实例页面来看看:
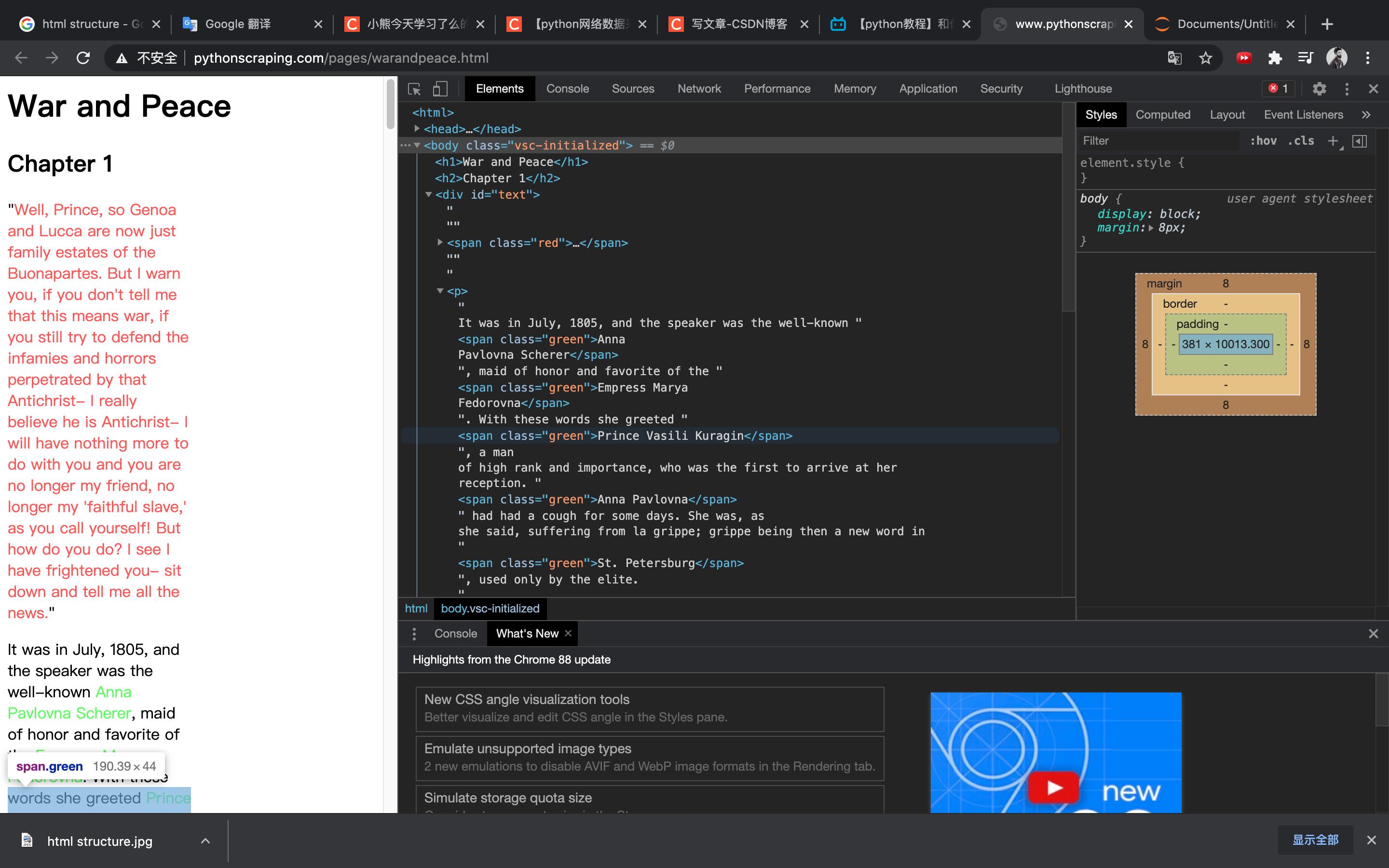
书中要求抓取所有人名,仔细观察可以发现在这个页面中,人名都是被span tag标记的,用的green class渲染,这样我们的程序就可以判断这是不是要抓取的内容了。
okk,接下来咱开始下厨做汤!!!
#导入所需的函数
from urllib.request import urlopen
from bs4 import BeautifulSoup
#打开要抓取的页面链接
html = urlopen("http://www.pythonscraping.com/pages/warandpeace.html")
bsobj = BeautifulSoup(html)
#调用findAll函数
#这句函数的意思是:找出所有tga(标签)为span,class为green的数据
nameList = bsobj.findAll("span", {"class":"green"})
for name in nameList:
print(name.get_text())
#将这些采集到的数据打印出来看看

至此,我们完成了对此页面的人物名称采集。但是不知道细心的你有没有喝出这汤不对啊?感觉少了点儿盐!
在原文中,Anna Pavlovna Scherer是同一个名字,而python似乎将它当成了两个名字处理???

实际上python并没有搞错,放盐这种业余厨师都会的技能作为大厨的python是不会搞错的!!!
咱们可以来看看python到底有没有忘记放盐:

喏,实际上python是记得加盐的,只是在html中Pavlovna Scherer被换行了(文本中看不出来)

所以如果把网页比做菜谱,python是个厨师,那么大厨python是严格按照菜谱将Pavlovna Scherer换行了。
题外话:
①在findAll函数中,获取到的数据是以列表的形式存储的,所以我们可以通过访问列表的方法访问具体的名称:

②通过上面的例子,你有没有好奇为什么透过列表的方式访问的nameList输出会带有span、class等字符串???
原因是在代码
for name in nameList:
print(name.get_text())
#将这些采集到的数据打印出来看看
中,get._text()函数已经将其他的干扰字符串剔除了,只将我们想要的内容保留并输出。
实际上我们还可以这样遍历nameList:
for _ in nameList:
print(_.get_text())
也就是用下划线代替name
③此外,在新版beautifulsoup中,findAll更新为find_all,使用时需注意??
内容总结
以上是互联网集市为您收集整理的【python网络数据采集】再来碗BeautifulSoup汤!全部内容,希望文章能够帮你解决【python网络数据采集】再来碗BeautifulSoup汤!所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。