python,爬取小说网站小说内容,同时每一章存在不同的txt文件中
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python,爬取小说网站小说内容,同时每一章存在不同的txt文件中,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2357字,纯文字阅读大概需要4分钟。
内容图文

思路,第一步小说介绍页获取章节地址,第二部访问具体章节,获取章节内容
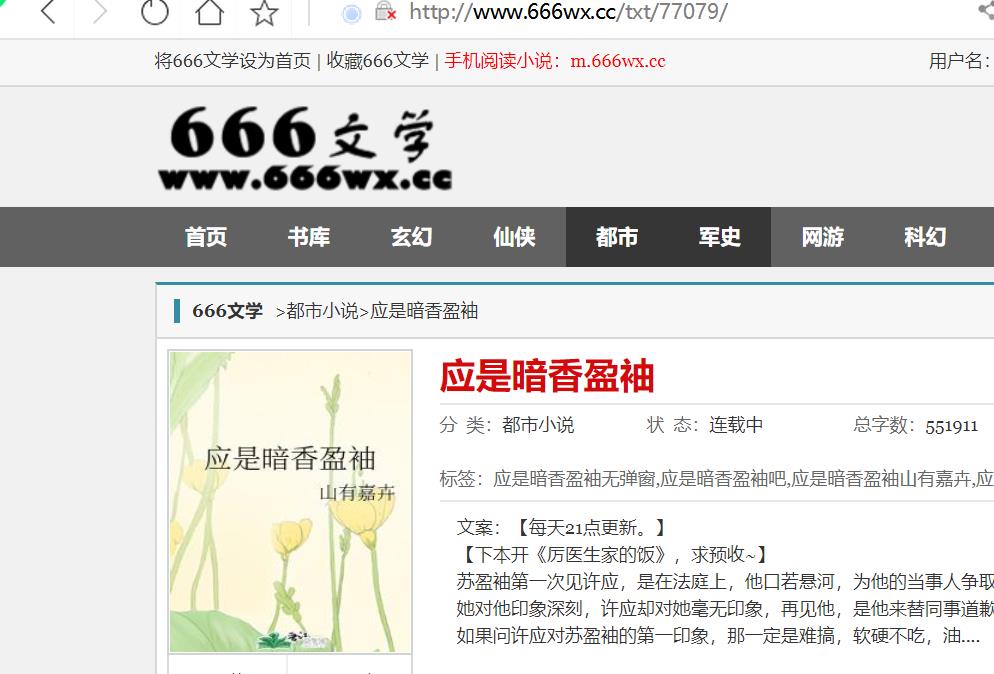
具体如下:先获取下图章节地址

def stepa(value,headers):
lit=[]
response = requests.get(value, headers=headers)
html = etree.HTML(response.text)
url = html.xpath('//*[@id="chapterlist"]//@href')#获取每章地址
lit.append(url)
return(lit)
add=stepa(value,headers)
allurl=add[0]#去掉括号
上方代码可获取到下图红色区域内内容,即每一章节地址的变量部分,且全部存在脚本输出的集合中
第二部,循环访问集合中的章节地址,获取章节内容,同时逐行存储在对应章节命名的txt文件中
for link in allurl:
link = 'http://www.666wx.cc'+link#拼接地址,可访问
response = requests.get(link, headers=headers)
html = etree.HTML(response.text)
name = html.xpath('//*[@id="center"]/div[1]/h1/text()')#章节
name =name[0]
content = html.xpath('//*[@id="content"]/text()')#章节内容
for 内容 in content:
内容 = 内容.strip()#去掉每行后的换行符
with open(path+'\\'+str(name)+'.txt', 'a',encoding='utf-8') as w:
w.write(str(内容))
w.close()
生成的文件一览

txt内容

全部脚本
# -*-coding:utf8-*-
# encoding:utf-8
#本脚本爬取http://www.666wx.cc站小说
import requests
from lxml import etree
import os
import sys
import re
headers = {
'authority': 'cl.bc53.xyz',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'none',
'sec-fetch-mode': 'navigate',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': '__cfduid=d9b8dda581516351a1d9d388362ac222c1603542964',
}
value = "http://www.666wx.cc/txt/77079/"#小说地址
path = os.path.abspath(os.path.dirname(sys.argv[0]))
def stepa(value,headers):
lit=[]
response = requests.get(value, headers=headers)
html = etree.HTML(response.text)
url = html.xpath('//*[@id="chapterlist"]//@href')#获取每章地址
lit.append(url)
return(lit)
add=stepa(value,headers)
allurl=add[0]#去掉括号
for link in allurl:
link = 'http://www.666wx.cc'+link#拼接地址,可访问
response = requests.get(link, headers=headers)
html = etree.HTML(response.text)
name = html.xpath('//*[@id="center"]/div[1]/h1/text()')#章节
name =name[0]
content = html.xpath('//*[@id="content"]/text()')#章节内容
for 内容 in content:
内容 = 内容.strip()#去掉每行后的换行符
with open(path+'\\'+str(name)+'.txt', 'a',encoding='utf-8') as w:
w.write(str(内容))
w.close()
print("ok")
内容总结
以上是互联网集市为您收集整理的python,爬取小说网站小说内容,同时每一章存在不同的txt文件中全部内容,希望文章能够帮你解决python,爬取小说网站小说内容,同时每一章存在不同的txt文件中所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】