Python爬虫:网络爬虫实现豆瓣电影采集,想看啥自己挑选
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python爬虫:网络爬虫实现豆瓣电影采集,想看啥自己挑选,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3695字,纯文字阅读大概需要6分钟。
内容图文

本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本文章来自腾讯云 作者:Python爬虫与数据挖掘
想要学习Python?有问题得不到第一时间解决?来看看这里“1039649593”满足你的需求,资料都已经上传至文件中,可以自行下载!还有海量最新2020python学习资料。
点击查看
一、项目背景
豆瓣电影提供最新的电影介绍及评论包括上映影片的影讯查询及购票服务。可以记录想看、在看和看过的电影电视剧 、顺便打分、写影评。极大地方便了人们的生活。
今天以电视剧(美剧)为例,批量爬取对应的电影,写入csv文档 。用户可以通过评分,更好的选择自己想要的电影。
二、项目目标
获取对应的电影名称,评分,详情链接,下载 电影的图片,保存文档。
三、涉及的库和网站
1、网址如下:
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}
2、涉及的库:requests****、fake_useragent、json****、csv
3、软件:PyCharm
四、项目分析
1、如何多网页请求?
点击下一页时,每增加一页paged自增加20,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。
2、如何获取真正请求的地址?
请求数据时,发现页面上并没有对应数据。其实豆瓣网采用javascript动态加载内容,防止采集。
1)F12右键检查,找到Network,左边菜单Name , 找到第五个数据,点击Preview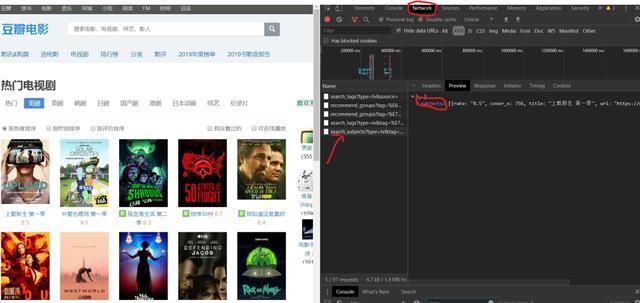
2)点开subjects,可以看到 title 就是对应电影名称。rate就是对应评分。通过js解析subjects字典,找到需要的字段。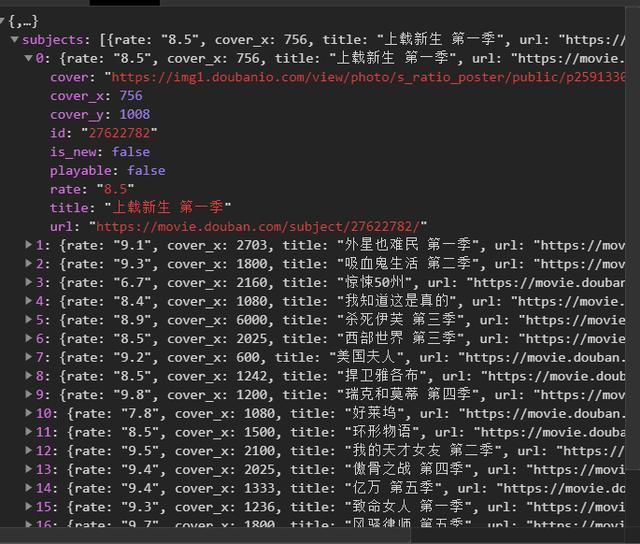
如何网页访问?
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=0 https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=20 https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=40 https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=60
当点击下一页时,每增加一页page自增加20,用{}代替变换的变量,再用for循环遍历这网址,实现多个网址请求。
五、项目实施
1、我们定义一个class类继承object,然后定义init方法继承self,再定义一个主函数main继承self。导入需要的库和请求网址。
import requests,json
from fake_useragent import UserAgent
import csv
class Doban(object):
def __init__(self):
self.url = "https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}"
def main(self):
pass
if __name__ == '__main__':
Siper = Doban()
Siper.main()
2、随机产生UserAgent,构造请求头,防止反爬。
for i in range(1, 50):
self.headers = {
'User-Agent': ua.random,
}
3、发送请求 ,获取响应,页面回调,方便下次请求。
def get_page(self, url):
res = requests.get(url=url, headers=self.headers)
html = res.content.decode("utf-8")
return html
4、json解析页面数据,获取对应的字典。
data = json.loads(html)['subjects']
# print(data[0])
5、for遍历,获取对应的电影名、 评分、下详情页链接。
print(name, goblin_herf)
html2 = self.get_page(goblin_herf) # 第二个发生请求
parse_html2 = etree.HTML(html2)
r = parse_html2.xpath('//div[@class="entry"]/p/text()')
6、创建csv文件进行写入,定义对应的标题头内容,保存数据 。
# 创建csv文件进行写入
csv_file = open('scr.csv', 'a', encoding='gbk')
csv_writer = csv.writer(csv_file)
# 写入csv标题头内容
csv_writerr.writerow(['电影', '评分', "详情页"])
#写入数据
csv_writer.writerow([id, rate, urll])
7、图片地址进行请求。定义图片名称,保存文档。
html2 = requests.get(url=urll, headers=self.headers).content
dirname = "./图/" + id + ".jpg"
with open(dirname, 'wb') as f:
f.write(html2)
print("%s 【下载成功!!!!】" % id)
8、调用方法,实现功能。
html = self.get_page(url) self.parse_page(html)
9、项目优化:
1)设置时间延时。
time.sleep(1.4)
2)定义一个变量u, for遍历,表示爬取的是第几页。(更清晰可观)。
u = 0 self.u += 1;
六、效果展示
1、点击绿色小三角运行输入起始页,终止页( 从0页开始 )。
2、将下载成功信息显示在控制台。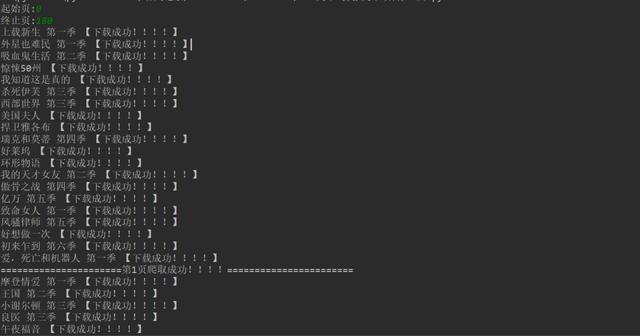
3、保存csv文档。

4、电影图片展示。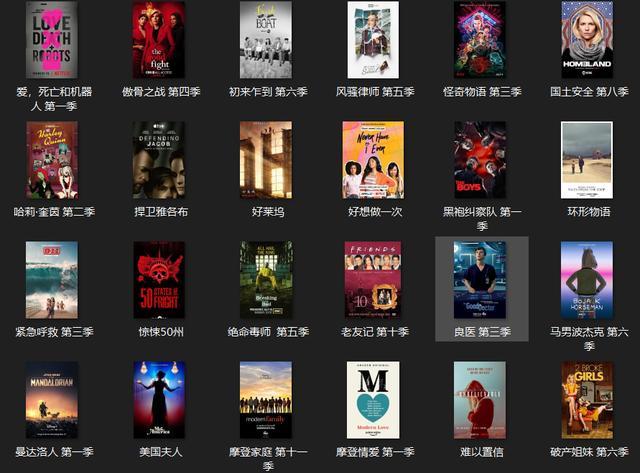
内容总结
以上是互联网集市为您收集整理的Python爬虫:网络爬虫实现豆瓣电影采集,想看啥自己挑选全部内容,希望文章能够帮你解决Python爬虫:网络爬虫实现豆瓣电影采集,想看啥自己挑选所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。