惊了,2行python代码干了1天的工作量,python太强了
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了惊了,2行python代码干了1天的工作量,python太强了,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2185字,纯文字阅读大概需要4分钟。
内容图文

事情是这样的,元旦前有朋友向我寻求帮助,吐槽老板在放假前给他安排一个苦逼的差事,想问问我能不能帮个忙,要不然假期都过不好了
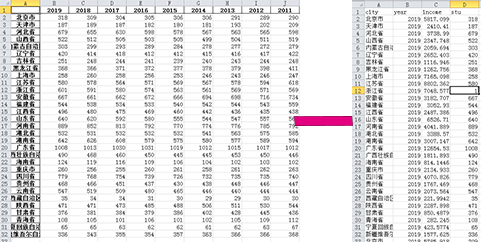
工作具体内容如下,主要是想把一个二维表格转成一维表格,如下图(表格为替代品):
于是我马上想到了pandas,想着这么强大的函数肯定有这个功能,于是我开始翻阅资料,没想到还真找到了,而且仅用三行代码就搞定了,惊的朋友直呼python牛批
下面个大家详细介绍一下整个过程
1.正确读取表格
首先按照传统的方式读表格:
import pandas as pd
data1 = pd.read_excel('高中生数量.xlsx')
data1
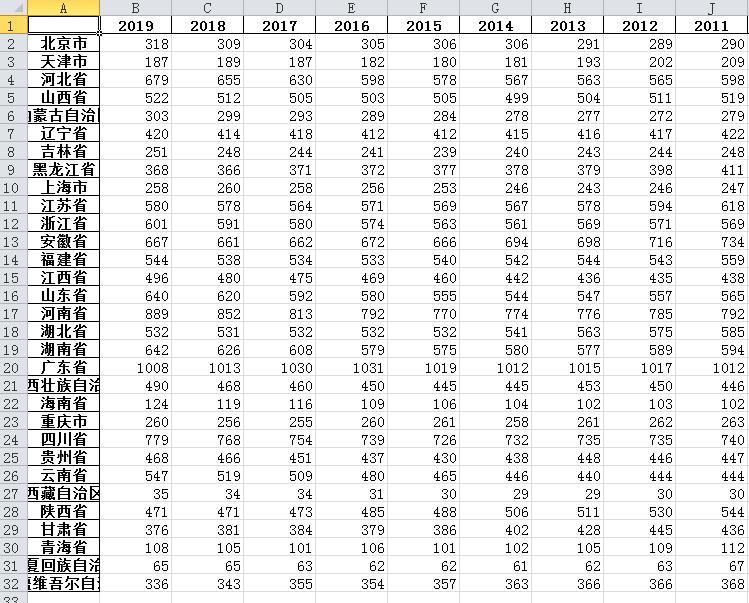
发现索引列没有被识别,产生了Unnamed: 0列,所以我们应该把第一列设置为索引列,代码如下:
import pandas as pd
data1 = pd.read_excel('高中生数量.xlsx',index_col=0) #index_col用来设置索引列
data1
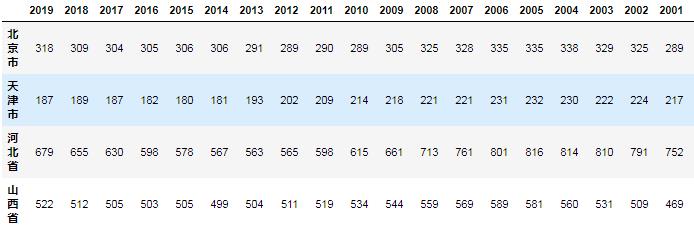
这样就正常读取并识别表格了
2.重置索引
这一步主要是将索引列重置,变为普通列,便于下步,代码如下
data2=data1.reset_index()
data2
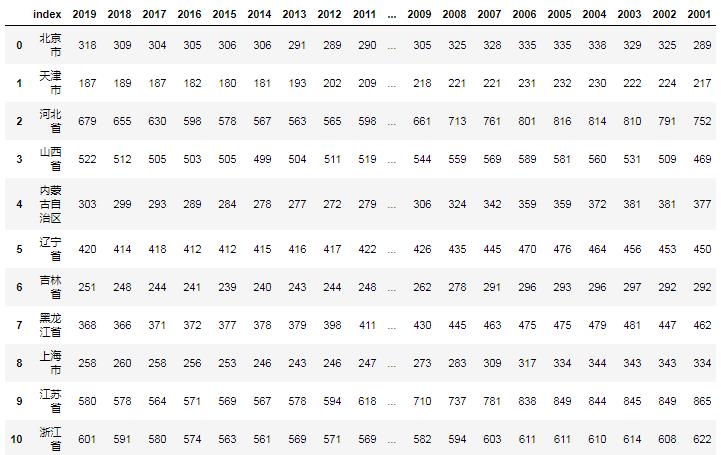
可以发现,之前的索引列编程‘index’列了
3.将列名转换为列数据
这一步主要用到pandas的melt函数,melt是逆转操作函数,可以将列名转换为列数据(columns name → column values),重构DataFrame,用法如下:
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)
参数解释:
frame:要处理的数据集;
id_vars:不需要被转换的列名;
value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了;
var_name和value_name是自定义设置对应的列名;
col_level :如果列是MultiIndex,则使用此级别。
我们把’index’列保留,并把转换后的列命名为’year’,value命名为’stu_num’:
data3=data2.melt(id_vars='index', var_name='year',value_name='stu_num')
data3
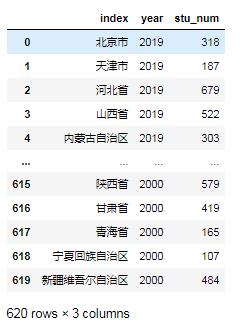
4.把第一列设置为索引列
为了防止保存后的表格带有数字索引,需要把第一列设置为索引列:
data4=data3.set_index('index')
data4
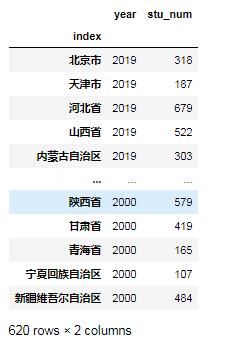
5.保存表格
data4.to_excel('转换后表格.xlsx')
大功告成,上述代码可以用3行代码搞定:
data = pd.read_excel('高中生数量.xlsx',index_col=0)
data=data.reset_index().melt('index', var_name='col').set_index('index')
data.to_excel('转换后表格.xlsx')
是不是很强悍!
一起感受一下妹子的夸赞吧!
幸福就是这么简单,不是哥优秀,而是python太强大,哈哈!
?最后,为了方便大家学习,鸟哥给大家准备一份pandas视频教程。这套视频即生动有趣,又通俗易懂,而且是高清视频,非常适合pandas学习者,总共30个课时,而且附带源码和数据素材,已经给大家打包准备好,获取方式如下:
获取视频:
1.扫码下面的公众号
2.输入:pandas

内容总结
以上是互联网集市为您收集整理的惊了,2行python代码干了1天的工作量,python太强了全部内容,希望文章能够帮你解决惊了,2行python代码干了1天的工作量,python太强了所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。