成功使用Python爬虫扇贝单词库实现自动测试我们的单词量
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了成功使用Python爬虫扇贝单词库实现自动测试我们的单词量,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1509字,纯文字阅读大概需要3分钟。
内容图文

import time
import requests
import re
from openpyxl import workbook#导入我们要用到的库
from bs4 import BeautifulSoup as bs
class TestYourWord:
#这个功能复制下来,并且做点改良,搞一个网页版没有的功能 ———— 自动生成错词本
def __init__(self):
self.start_url = 'https://www.shanbay.com/bdc/client/vocabtest/welcome'
#请求头,浏览器模拟
#设置这一步的目的是为了伪装我们的爬虫,防止被识别出来
#由requests自动生成的headers,可被服务器轻易识别为爬虫,所以我们要进行伪装
self.headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
}
self.which_test = int(input('请输入你想要选择的题库:(数字1-10)'))
def getHtml(self):
gu = self.start_url #url生成器
html = requests.get(gu,headers=self.headers)
soup = bs(html.text,'html.parser')
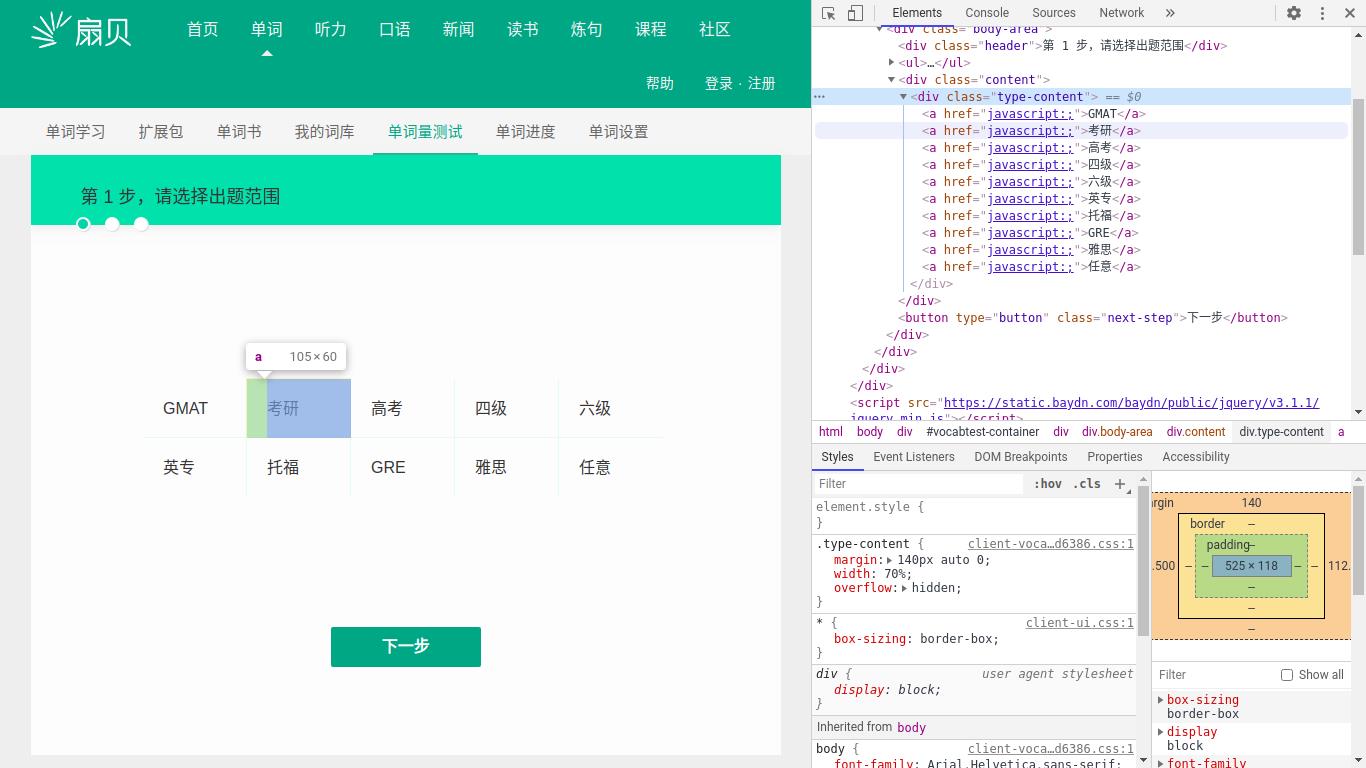
items=soup.find('div',class_='type-content').find(a)
for item in items:
print(item)
return html
def getData(self):
res = self.getHtml()
data=res.json
print(data)
if __name__ == '__main__':
start = time.time()
test = TestYourWord()
test.getData()
 问题出现在我们是一个动态网页,应该在XHR里面找内容,
问题出现在我们是一个动态网页,应该在XHR里面找内容,
 把链接改成上图所示的链接则可以成功提取数据了。
把链接改成上图所示的链接则可以成功提取数据了。
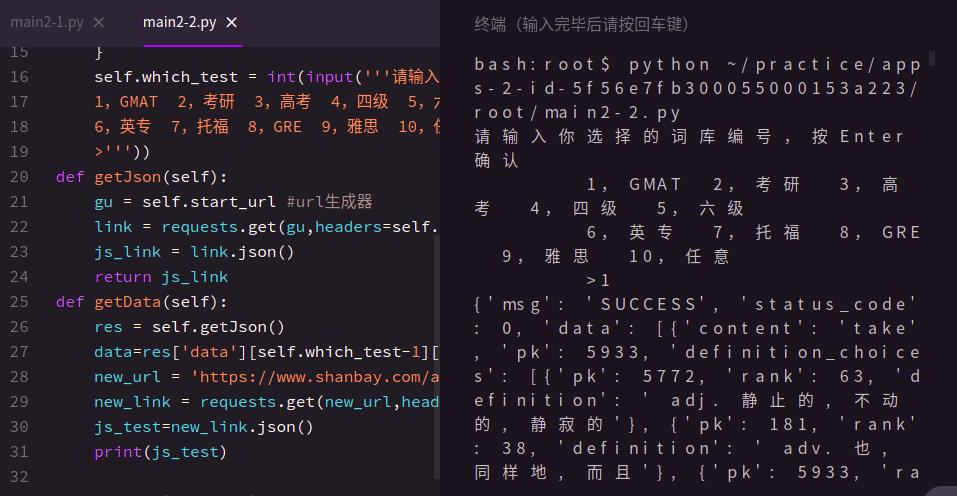
打印Json文件可以得到如下内容
请输入你选择的词库编号,按Enter确认
1,GMAT 2,考研 3,高考 4,四级 5,六级
6,英专 7,托福 8,GRE 9,雅思 10,任意
>1
[['GMAT', 'GMAT'], ['NGEE', '考研'], ['NCEE', '高考'], ['CET4', '四级'], ['CET6', '六级'], ['TEM', '英专'], ['TOEFL', '托福'], ['GRE', 'GRE'], ['IELTS', '雅思'], ['NONE', '任意']]
我们定位到相应的词库可以得到相应的新json文件
内容总结
以上是互联网集市为您收集整理的成功使用Python爬虫扇贝单词库实现自动测试我们的单词量全部内容,希望文章能够帮你解决成功使用Python爬虫扇贝单词库实现自动测试我们的单词量所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】