Boosting 系列算法——1. 简单概述
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Boosting 系列算法——1. 简单概述,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2067字,纯文字阅读大概需要3分钟。
内容图文

写在最前
博主准备写几篇博客,主要将目前比较常见的一些Boosting算法进行汇总整理,帮助大家更好的进行机器学习算法的学习。同时对将来找工作的童鞋们也能有一些帮助。
本系列博客参考了大量网上的内容(包括Wiki,中英文博客等),涉及到的相关Boosting算法的原始论文,以及李航老师的《统计学习方法》,三位大牛的《The Elements of Statistical Learning》,还有周志华老师的《集成学习》。
为了方便大家对整个Boosting算法的理解,并且处于严谨的考虑,这一系列博客都将采用同一套符号体系。
下面为目前为止一系列博客的传送门,后续博主有时间的话会继续更新完善。
- Boosting 系列算法——1. 简单概述
- Boosting 系列算法——2. Adaboost
- Boosting 系列算法——3. Adaboost 的延伸算法
- Boosting 系列算法——4. Gradient Boosting
- Boosting 系列算法——5. XGBoost
- Boosting 系列算法——6. LightGBM
一个简单的概述
在机器学习中,Boosting 是一种可以用来减小监督式学习中偏差的机器学习算法。面对的问题是迈可·肯斯(Michael Kearns)提出的:一组“弱学习者”的集合能否生成一个“强学习者”?弱学习者一般是指一个分类器,它的结果只比随机分类好一点点;强学习者指分类器的结果非常接近真值。而 Boosting 是指一种由弱分类器组成的强分类器的一类算法族。其分类器由多个弱分类器组成,预测时用每个弱分类器分别进行预测,然后投票得到结果;训练时依次训练每个弱分类器,每个弱分类器重点关注被前面弱分类器错分的样本,并且弱分类器是非常简单的分类器,其计算量小并且不需要精度非常高。
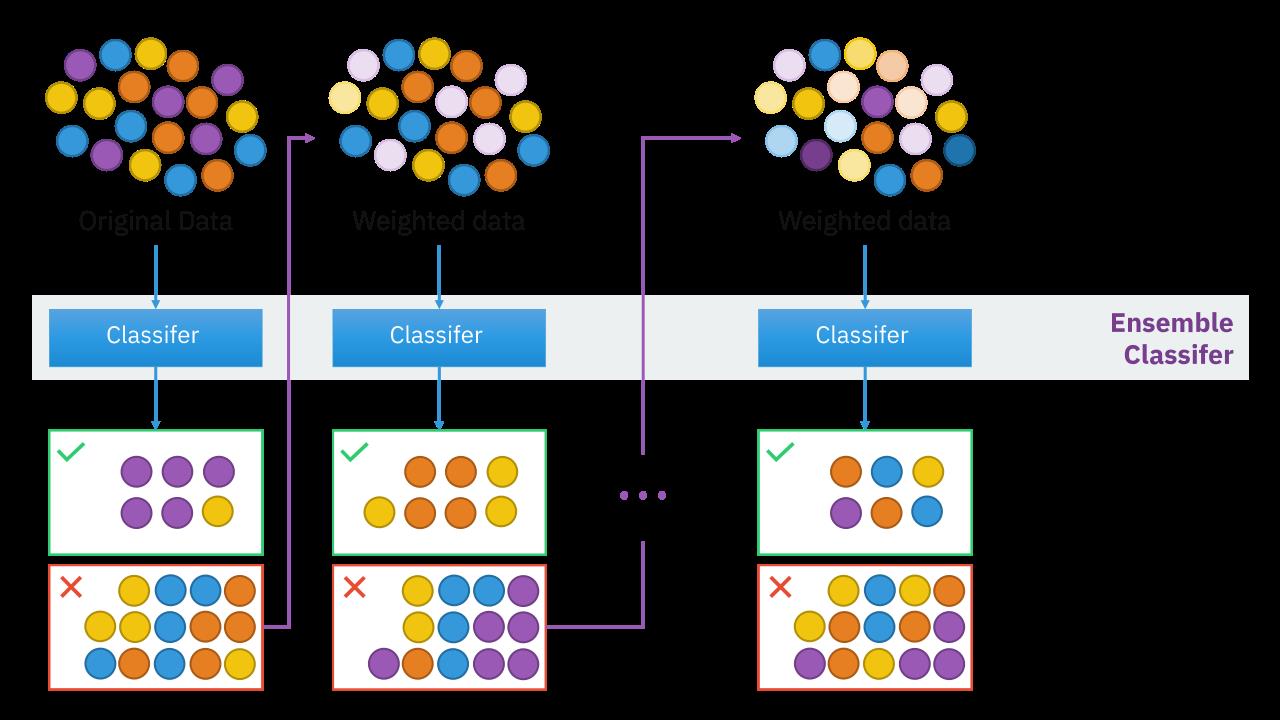
作为函数估计问题的一种,Boosting算法的核心问题也是对一个预测性能最好的函数进行估计。给定输出的响应变量为 y y y,输入的随机向量为 x = { x 1 , ? ? , x d } \mathbf{x}=\{x_1,\cdots,x_d\} x={x1?,?,xd?},其维度为 d d d,训练样本为 { y i , x i } 1 N \{y_i,\mathbf{x}_i\}_1^N {yi?,xi?}1N?。我们的目的是通过最小化一些给定的损失函数 L ( y , F ( x ) ) L(y, F(\mathbf{x})) L(y,F(x)),得到最优函数 F ? ( x ) F^{*}(\mathbf{x}) F?(x)的估计或者近似 F ^ ( x ) \hat{F}(\mathbf{x}) F^(x)。
F ? = arg ? min ? F E y , x L ( y , F ( x ) ) = arg ? min ? F E x [ E y ( L ( y , F ( x ) ) ) ∣ x ] . F^{*}={\underset {F}{\arg \min }} E_{y, \mathbf{x}} L(y, F(\mathbf{x}))={\underset {F}{\arg \min }} E_{\mathbf{x}}\left[E_{y}(L(y, F(\mathbf{x}))) \mid \mathbf{x}\right]. F?=Fargmin?Ey,x?L(y,F(x))=Fargmin?Ex?[Ey?(L(y,F(x)))∣x].
Boosting算法则是通过一种“可加”模型的方法,来对最优的 F ? F^{*} F?进行近似。
内容总结
以上是互联网集市为您收集整理的Boosting 系列算法——1. 简单概述全部内容,希望文章能够帮你解决Boosting 系列算法——1. 简单概述所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。