20行Python代码爬取100W多条音频文件素材~
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了20行Python代码爬取100W多条音频文件素材~,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2260字,纯文字阅读大概需要4分钟。
内容图文

前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!??¤
QQ群:961562169
相关环境配置
- python 3.6
- pycharm
- requests
- parsel
相关模块可pip安装,如果觉得安装速度太慢点击下面链接查看相关教程
?
请求网页
import requests
url = 'http://sc.chinaz.com/yinxiao/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
print(response.text)
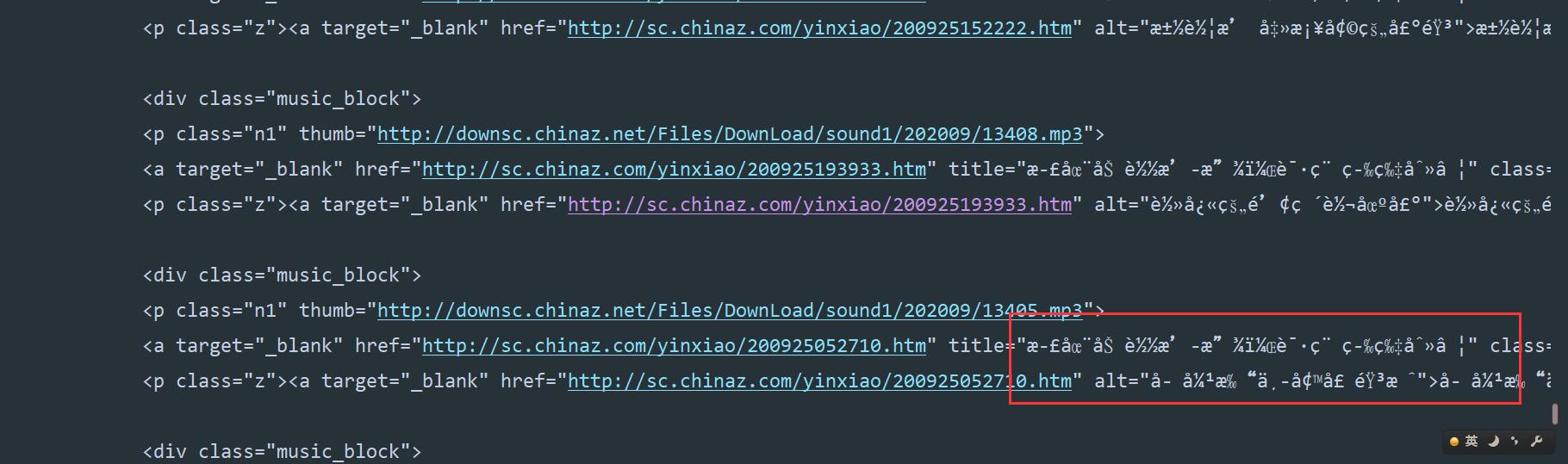
?
但是返回数据有中文乱码,编码出现了问题,所以咱们只需要转码一下就可以了
response.encoding = response.apparent_encoding
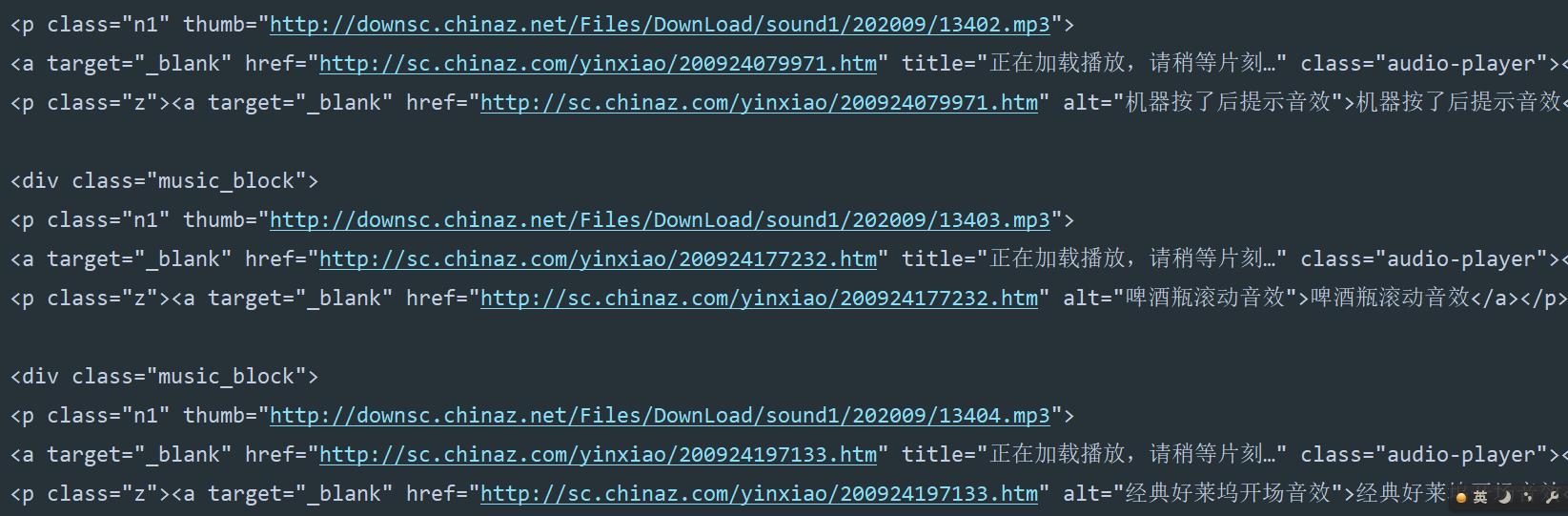
?
解析数据
import parsel
selector = parsel.Selector(response.text)
urls = selector.css('#musiclist .n1::attr(thumb)').getall()
titles = selector.css('#musiclist .z a::attr(alt)').getall()
data = zip(urls, titles)
for i in data:
print(i)
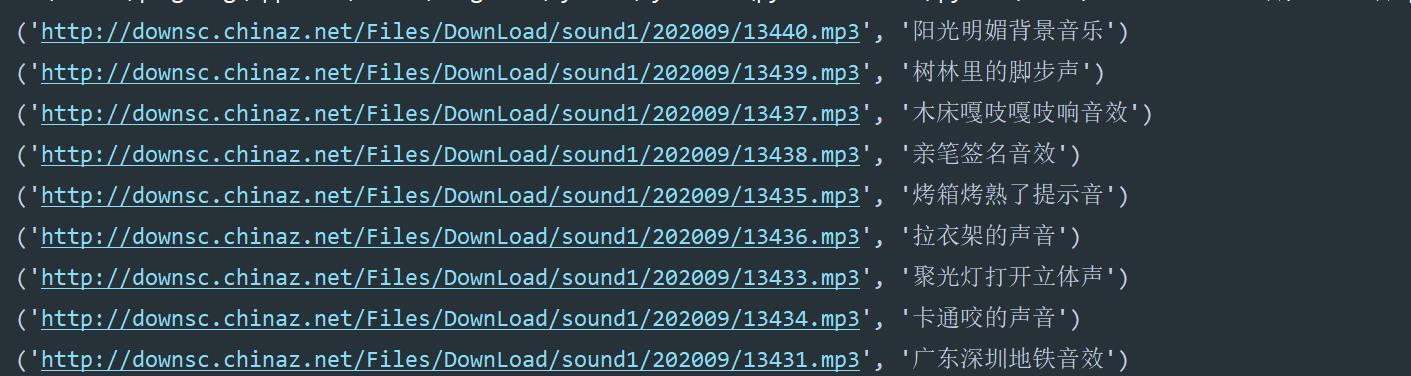
?
保存数据
response_2 = requests.get(url=download_url, headers=headers)
filename = '路径' + title + '.mp3'
with open(filename, mode='wb') as f:
f.write(response_2.content)

?
一页的音频文件就都保存到本地文件了
多页爬取音频文件代码
import requests
import parsel
for page in range(1, 603):
url = 'http://sc.chinaz.com/yinxiao/index_{}.html'.format(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = response.apparent_encoding
selector = parsel.Selector(response.text)
urls = selector.css('#musiclist .n1::attr(thumb)').getall()
titles = selector.css('#musiclist .z a::attr(alt)').getall()
data = zip(urls, titles)
for i in data:
print(i)
download_url = i[0]
title = i[1]
response_2 = requests.get(url=download_url, headers=headers)
filename = '路径' + title + '.mp3'
with open(filename, mode='wb') as f:
f.write(response_2.content)

?
每页40个文件,一共是602页数据,一共大概是2W多个音频文件素材,这边咱们就不等了就下载了一千多个文件,主要下载多了也占硬盘内存~ 代码还是有很多可以优化的地方~
内容总结
以上是互联网集市为您收集整理的20行Python代码爬取100W多条音频文件素材~全部内容,希望文章能够帮你解决20行Python代码爬取100W多条音频文件素材~所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。