首页 / PYTHON / python爬取微博热门话题榜
python爬取微博热门话题榜
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python爬取微博热门话题榜,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5883字,纯文字阅读大概需要9分钟。
内容图文

前言
python的爬虫应该是比较火热的,趁着国庆闲来无事,爬取一下微博热搜榜,也算是把之前用过的爬虫在博客简单的温习和记录一下。
爬虫定义
引用自维基百科
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
爬虫策略
- 选择策略
- 要爬取的url
- 页面元素
- 页面的链接
- 重新访问的策略
- 网站更新
- 页面变化
- 过度访问
- 爬虫和反爬虫
- IP代理池
- 访问次数
- robos.txt协议
- 并行策略
- 多线程运行爬虫
- 同一页面的重复爬取
python爬虫
获取数据
基本概念罗列完成了,我们就需要一个实战来简单的体验一下爬虫,思来想去,最后选择微博热点事件,进行数据爬取,实现一个简单的爬虫。
微博热点榜单网址:https://s.weibo.com/top/summary,打开网址看看
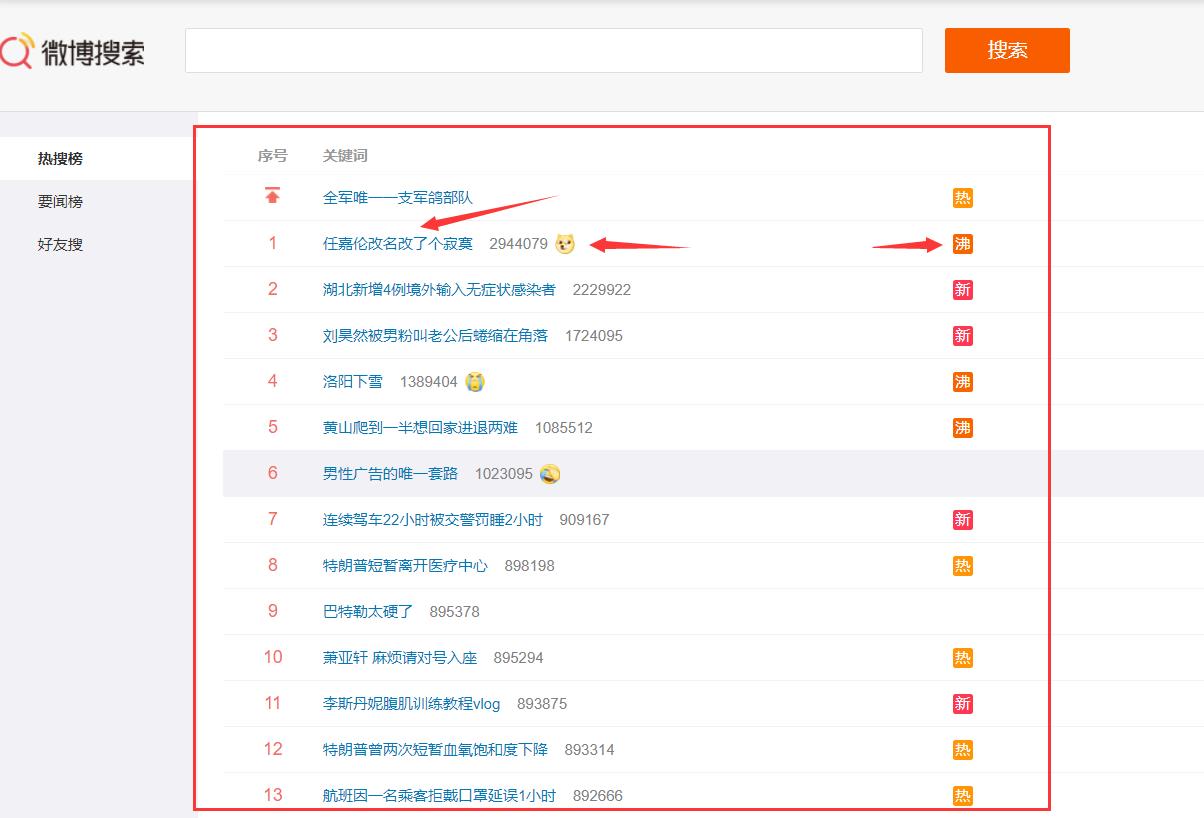
这就是一个简单的排行榜,我们将在这个页面进行一次爬虫,首页我们对这个页面需要进行一个分析,我们需要爬取那些数据。
我们可以看到箭头所指的部分,分为以下三种:
热点内容,热点浏览次数,热点类型
我们将对这三个数据进行获取,那么怎么获取呢,我们来看看
python有一个很方便的库,可以对网页的内容进行获取,requests库
pip install requests
我们先试试获取一下
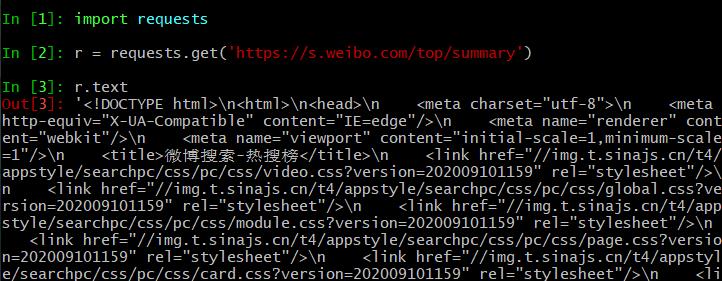
可以看到三行代码,我们就获取到了微博热搜榜的网页内容。
内容获取到了,我们需要对HTML内容进行解析,获取到我们想要的内容。
解析数据有很多的方式,比如正则表达式,字符串,beautifulsoup4等
在这里我们选择beautifulsoup4去进行解析,主要是方便易用。
解析网页数据
-
安装beautifulsoup4解析HTML文档的库
pip install beautifulsoup4 -
安装
lxml解析库pip install lxml
beautifulsoup4常见的解析库和优缺点
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") |
1.Python的内置标准库 2.执行速度适中 3.文档容错能力强 |
Python 2.7.3 or 3.2.2)前的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") |
1.速度快 2.文档容错能力强 |
需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") |
1.速度快 2.唯一支持xml的解析器 |
需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") |
1.最好的容错性 2.以浏览器的方式解析文档 3.生成HTML5格式的文档 |
1. 速度慢 2.不依赖外部扩展 |
beautifulsoup4的安装已经介绍完了,获取到数据之后我们要进行的就是解析数据了。
我们先看看文档 https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/,里面有详细的说明教程。我们就不一一列举了。
这里只选择我们这次使用的进行简单的说明,在说明之前我们首先先用chrome看看我们需要解析那些数据:
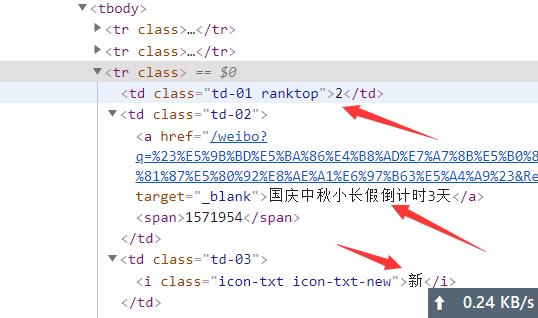
使用F12开发者工具查看之后我们所需要的数据就在箭头所指的部分。
这个一个HTML表格,我们需要获取所有的tr节点里面的这三个文本,一起来吧。
-
生成解析对象
soup = BeautifulSoup(htmls, 'lxml') -
获取tag信息
ranks = soup.find_all('td', class_='td-01 ranktop') tags = soup.find_all('td', class_='td-02') -
获取文本信息
ranks.string -
获取子节点的tag信息
tags.a
好了我们所能用到的就是这些了。刚才数据已经获取到了,我们一起来看看,解析后的数据。
def analysis(self):
"""提取数据"""
results = []
htmls = self.get_html()
soup = BeautifulSoup(htmls, 'lxml')
ranks = soup.find_all('td', class_='td-01 ranktop')
tags = soup.find_all('td', class_='td-02')
hots = soup.find_all('td', class_='td-03')
for rank, tag, hot in zip(ranks, tags, hots):
results.append(
(rank.string if rank else 0,
tag.a.string,
tag.span.string if tag.span else 9999999,
hot.i.string if hot.i else ''))
return results
我们分别通过三个find_all方法获取到所有的文本,然后通过zip方法把每一组放在各自的列表中。
数据排序
在这个里面添加的数据是按照正常的顺序排列的,但是我的不想把数据按照正序排列,我希望能按照倒序排列,就是浏览次数少的在前面。应该怎么实现呢,我们需要借助python的sorted方法进行一次倒序排列。
def __sort(self):
result = self.analysis()
return sorted(result, key=lambda x: int(x[2]), reverse=False) # 反向排序
通过sorted方法并指定阅读数量为排序的key,我们实现了倒序的排列。
展示数据
数据也获取到了,也进行排序了我们接下来就需要对获取的数据进行一个展示了。
我们需要把数据展示一种好看的形式,比如下面这种:
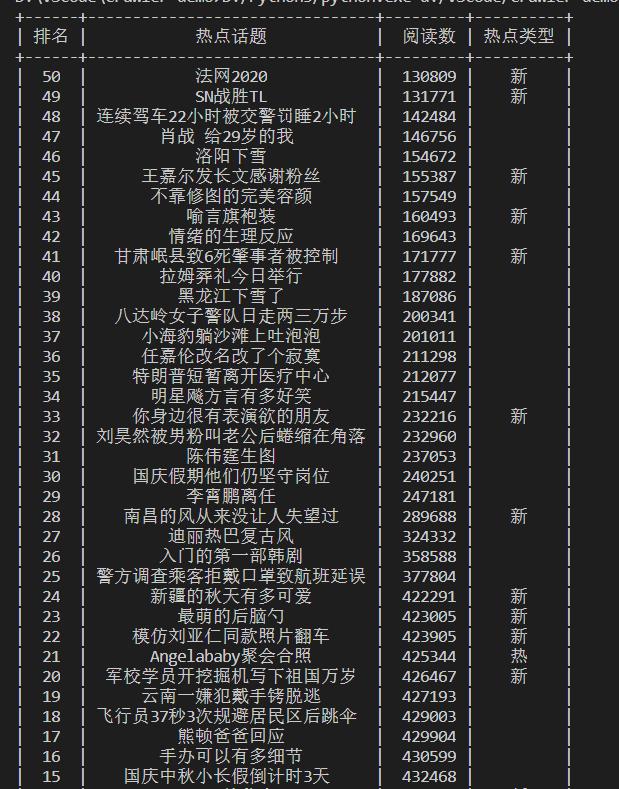
想要实现下面这种自己写的话比较麻烦,我们可以中python的第三方库prettytable,来实现这个表格打印。
首先我们安装一下。
pip install prettytable
然后编写展示数据的代码:
from prettytable import PrettyTable
tb = PrettyTable()
sorts_data = self.__sort()
tb.field_names = '排名,热点话题,阅读数,热点类型'.split(',')
for i in sorts_data:
tb.add_row(i)
print(tb)
然后我们执行,很快执行结果出来了,结果打印出来了,但是却报错了。
RecursionError: maximum recursion depth exceeded in comparison
超过最大递归数,什么鬼,这个问题我查了很久终于找到了问题所在
在prettytable源码的第1253行和1255行

有一个deepcopy方法,我们把它去掉就可以了。
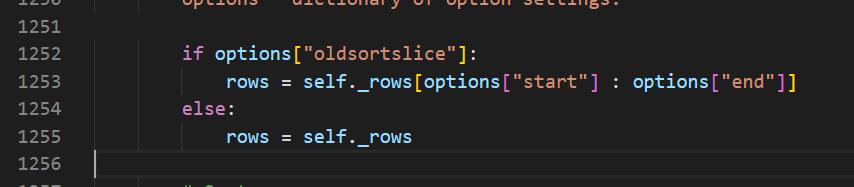
至于为什么,原因是这样的,deepcopy在python中是深复制和浅复制的不同是,复制完成后和原来的变量是有所不同的,内存地址变了,导致我们在运行过程中由于每次的sorts_data列表会被不停的复制,然后每次的内存地址不一样,会一直在执行,所以会陷入递归调用。所以我们只要删除这个深复制方法就好了,执行的时候就不会出现最大递归的报错了。
然后这次的修改我已经给这个仓库提交了PR了,期待审核通过。
函数去掉后,运行一切正常。
执行源代码
至此,我们的爬虫也就写完了。废话也不多说了,直接上源码,希望我在记录的同时能对你有所帮助。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup
from prettytable import PrettyTable
class WeiboTop(object):
def __init__(self):
self.url = 'https://s.weibo.com/top/summary' # 微博热搜地址
def get_html(self):
"""获取网页内容"""
r = requests.get(self.url)
return r.text
def analysis(self):
"""提取数据"""
results = []
htmls = self.get_html()
soup = BeautifulSoup(htmls, 'lxml')
ranks = soup.find_all('td', class_='td-01 ranktop')
tags = soup.find_all('td', class_='td-02')
hots = soup.find_all('td', class_='td-03')
for rank, tag, hot in zip(ranks, tags, hots):
results.append(
[rank.string if rank else '',
tag.a.string,
tag.span.string if tag.span else 9999999,
hot.i.string if hot.i else ''])
return results
def __sort(self):
"""排序(倒序)"""
result = self.analysis()
return sorted(result, key=lambda x: int(x[2]), reverse=False) # 反向排序
def show(self):
"""展示数据"""
tb = PrettyTable()
sorts_data = self.__sort()
tb.field_names = '排名,热点话题,阅读数,热点类型'.split(',')
for i in sorts_data:
tb.add_row(i)
print(tb)
if __name__ == "__main__":
wt = WeiboTop()
wt.show()
python的用处太多了,每一个要学习的方向,都挺多的,以后将不再把时间精力放在爬虫上面。
内容总结
以上是互联网集市为您收集整理的python爬取微博热门话题榜全部内容,希望文章能够帮你解决python爬取微博热门话题榜所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。