基础爬虫小案例:约会吧小姐姐照片,联系方式随手可得(附源码)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了基础爬虫小案例:约会吧小姐姐照片,联系方式随手可得(附源码),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2069字,纯文字阅读大概需要3分钟。
内容图文
")

前言
百度贴吧是以兴趣主题聚合志同道合者的互动平台,同好网友聚集在这里交流话题、展示自我、结交朋友。贴吧中有的帖子当中有用户上传的图片,今天跟着老师把约会吧全吧的图片给爬取下来吧
预先清理磁盘哦~~
本文亮点:
1、分析页面(静态or动态)
2、两层数据解析
3、海量图片数据保存
环境介绍:
python 3.6
pycharm
requests
parsel(xpath)
爬虫的一般思路
1、确定爬取的url路径,headers参数
2、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
3、解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
4、保存数据
开始我们的案例吧
步骤
1、导入工具
import requests import parsel
2、确定爬取的url路径,headers参数
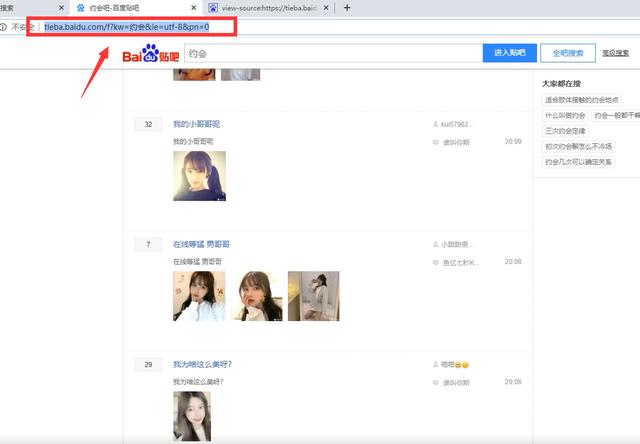
base_url = 'https://tieba.baidu.com/f?ie=utf-8&kw=%E7%BE%8E%E5%A5%B3&fr=search'
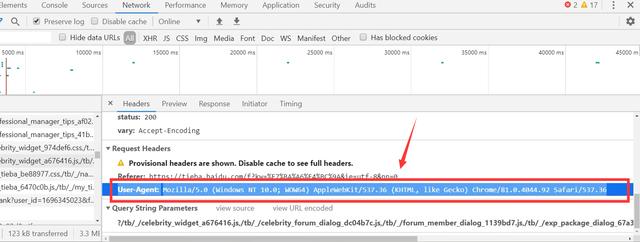
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'}
3、发送请求 -- requests 模拟浏览器发送请求,获取响应数据
response = requests.get(base_url, headers=headers) html_str = response.text # print(html_data)
4、解析数据 -- parsel 转化为Selector对象,Selector对象具有xpath的方法,能够对转化的数据进行处理
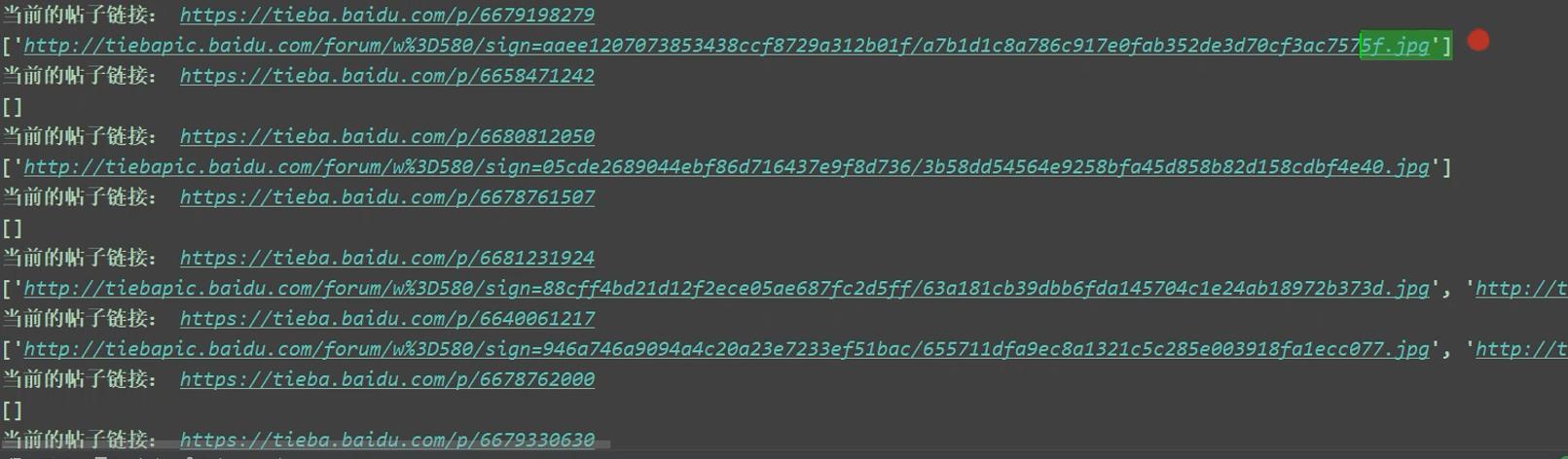
html = parsel.Selector(html_str)
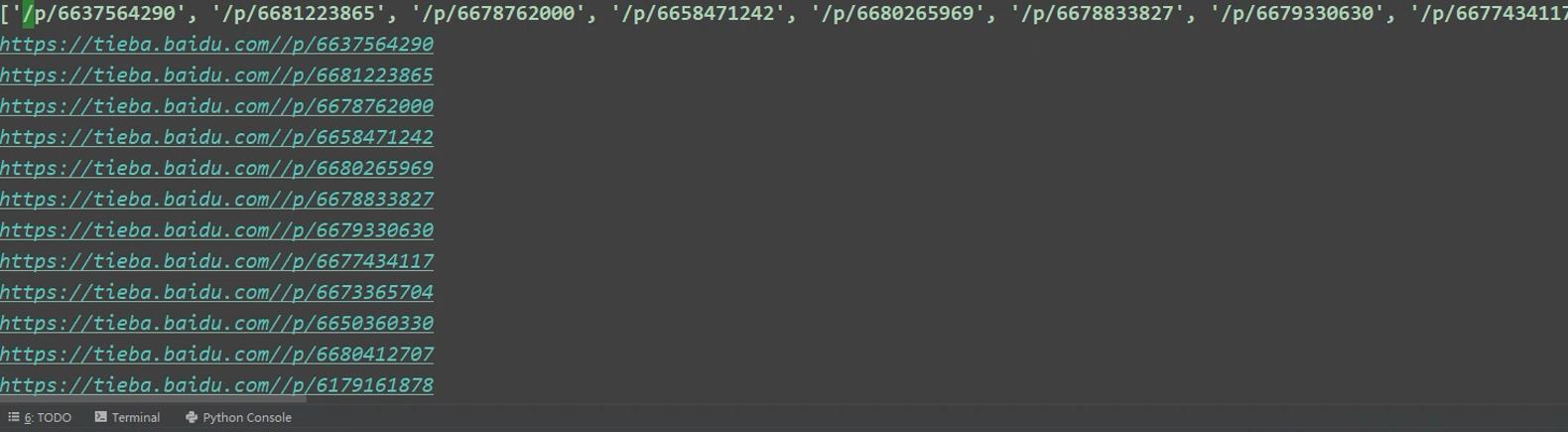
title_url = html.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href').extract()
# print(title_url)
# 拼接完整的帖子链接
second_url = 'https://tieba.baidu.com'
for url in title_url:
all_url = second_url + url
print('当前的帖子链接为:',all_url)
# 继续发送帖子的请求
response_2 = requests.get(all_url, headers=headers).text
# 第二次解析
response_2_data = parsel.Selector(response_2)
result_list = response_2_data.xpath('//cc/div/img[@class="BDE_Image"]/@src').extract() # 提取帖子内部图片的链接
# print(result_list)
# 发送图片链接请求
for li in result_list:
img_data = requests.get(li, headers=headers).content # 图片数据
# 图片文件名
file_name = li.split("/")[-1]
5、保存图片数据
with open("img\\" + file_name, 'wb') as f:
print('正在下载图片:',file_name)
f.write(img_data)
运行代码,结果如下图:
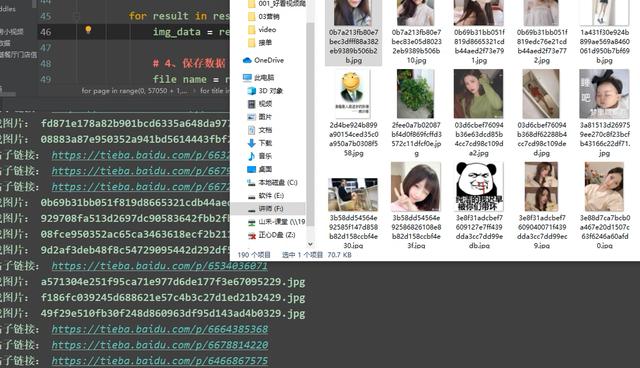
这样我们这一次的爬虫就算圆满成功了
欢迎点击右上角关注小编,除了分享技术文章之外还有很多福利,私信学习资料可以领取包括不限于Python实战演练、PDF电子文档、面试集锦、学习资料等。
内容总结
以上是互联网集市为您收集整理的基础爬虫小案例:约会吧小姐姐照片,联系方式随手可得(附源码)全部内容,希望文章能够帮你解决基础爬虫小案例:约会吧小姐姐照片,联系方式随手可得(附源码)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。