Python|基于百度API五行代码实现OCR文字高识别率
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python|基于百度API五行代码实现OCR文字高识别率,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1295字,纯文字阅读大概需要2分钟。
内容图文


朋友扔过来一张图片,说在整理试题答案,但是试题是图片,想从网上搜索答案一个一个敲太累了,能不能将图片里的文字提取出来?
我一看这是典型的OCR识别啊,直接祭出神器Tesseract.
tesseract -l chi_sim 4.png stdout
目
二 画 口 “ 口 出再对比原图一看
哦,不,是不是差的有点儿多?
怎么办呢?tesseract识别不利,肯定是咱玩的不溜,为了识别几张图,再进行一通识别训练是不是有点儿浪费时间?现在都2020年了,各大厂商都提供这种文字识别服务,像我知道的百度都号称50000次/天免费,就它了,开干
第一步 登陆 https://login.bce.baidu.com/
需要百度帐号,是偷是抢,各凭本事吧.
第二步 找到文字识别服务
乖乖,这大厂,就是不一样,产品真多.
第三步 创建一个应用
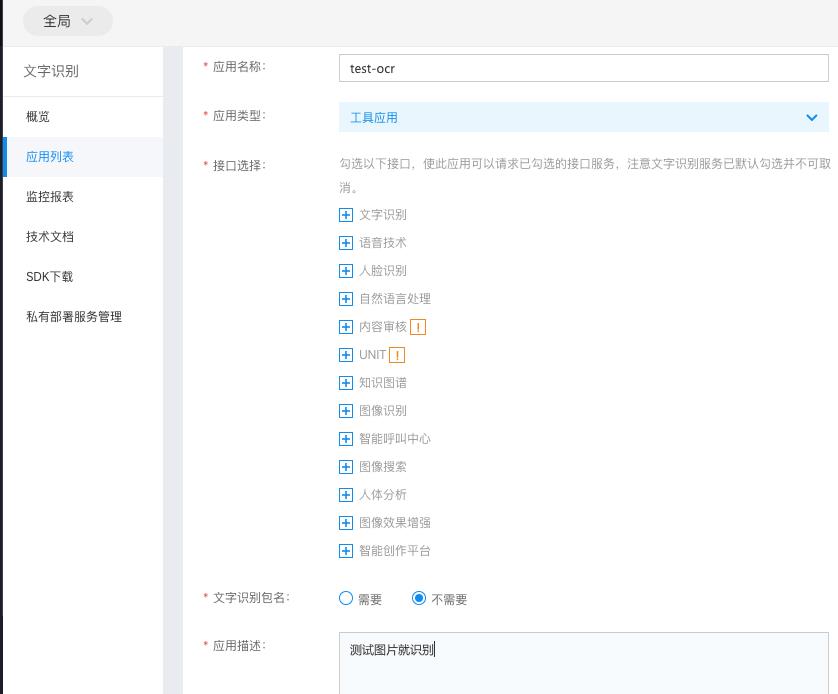
立即创建
第四步 拿到AppID,API Key,Secret Key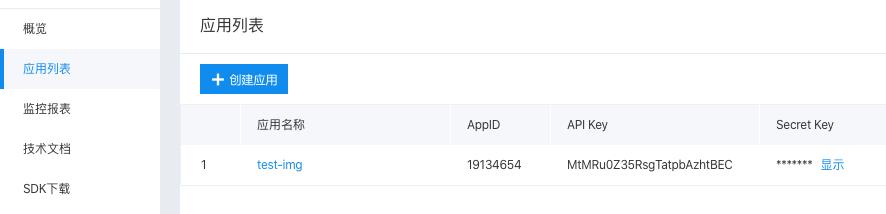
下面是见证五行代码的时刻了
第一步 安装百度Python SDK
pip install baidu-aip第二步 替换之前拿到 AppID,API Key,Secret Key并修改图片地址
from aip import AipOcr
APP_ID = 'xxx'
API_KEY = 'xxx'
SECRET_KEY = 'xxx'
IMAGE_URL='~/4.png'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
with open(IMAGE_URL, 'rb') as fp:
res = client.basicGeneral(fp.read())
for words_arr in res.get('words_result'):
print(words_arr['words'].replace('.口','.').replace('.回','.'))第三步 run
$ python ocr-baidu.py
4、知觉的特性包括()
A.整体性
B.选择性
C.恒常性
D.间接性
E.理解性
5、注意的功能有()
A.调节功能
B.维持功能
C.抑制功能
D.选择功能
E.启动功能
嗯 对比图片,比较完美, 收工!
that's all
内容总结
以上是互联网集市为您收集整理的Python|基于百度API五行代码实现OCR文字高识别率全部内容,希望文章能够帮你解决Python|基于百度API五行代码实现OCR文字高识别率所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。