一篇文章教会你使用Python定时抓取微博评论
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了一篇文章教会你使用Python定时抓取微博评论,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1738字,纯文字阅读大概需要3分钟。
内容图文

【Part1——理论篇】
试想一个问题,如果我们要抓取某个微博大V微博的评论数据,应该怎么实现呢?最简单的做法就是找到微博评论数据接口,然后通过改变参数来获取最新数据并保存。首先从微博api寻找抓取评论的接口,如下图所示。

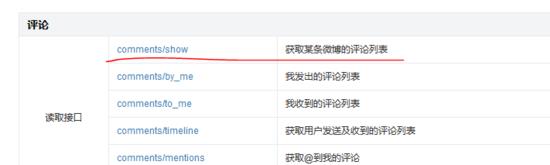
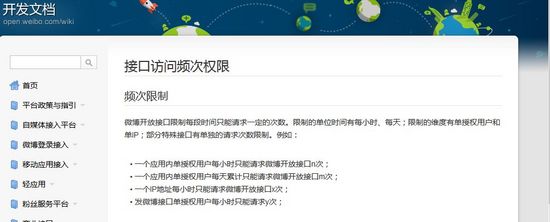
但是很不幸,该接口频率受限,抓不了几次就被禁了,还没有开始起飞,就凉凉了。
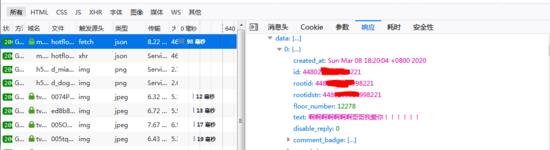
接下来小编又选择微博的移动端网站,先登录,然后找到我们想要抓取评论的微博,打开浏览器自带流量分析工具,一直下拉评论,找到评论数据接口,如下图所示。
之后点击“参数”选项卡,可以看到参数为下图所示的内容:
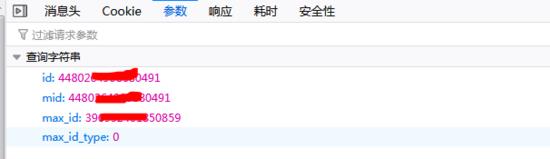
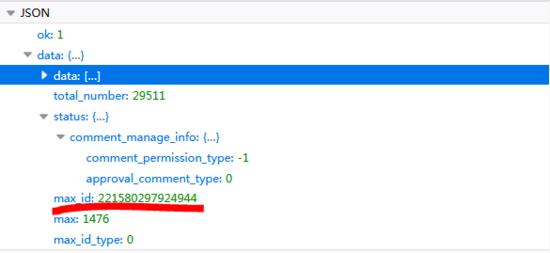
可以看到总共有4个参数,其中第1、2个参数为该条微博的id,就像人的身份证号一样,这个相当于该条微博的“身份证号”,max_id是变换页码的参数,每次都要变化,下次的max_id参数值在本次请求的返回数据中。
【Part2——实战篇】
有了上文的基础之后,下面我们开始撸代码,使用Python进行实现。

1、首先区分url,第一次不需要max_id,第二次需要用第一次返回的max_id。

2、请求的时候需要带上cookie数据,微博cookie的有效期比较长,足够抓一条微博的评论数据了,cookie数据可以从浏览器分析工具中找到。
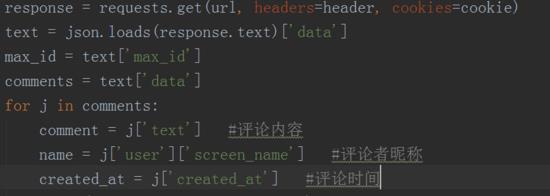
3、然后将返回数据转换成json格式,取出评论内容、评论者昵称和评论时间等数据,输出结果如下图所示。

4、为了保存评论内容,我们要将评论中的表情去掉,使用正则表达式进行处理,如下图所示。

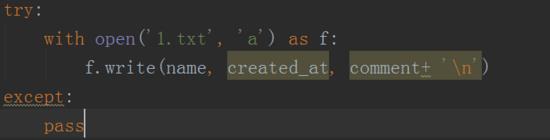
5、之后接着把内容保存到txt文件中,使用简单的open函数进行实现,如下图所示。
6、重点来了,通过此接口最多只能返回16页的数据(每页20条),网上也有说返回50页的,但是接口不同、返回的数据条数也不同,所以我加了个for循环,一步到位,遍历还是很给力的,如下图所示。

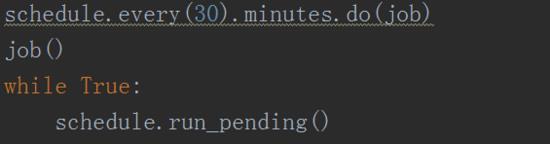
7、这里把函数命名为job。为了能够一直取出最新的数据,我们可以用schedule给程序加个定时功能,每隔10分钟或者半个小时抓1次,如下图所示。
8、对获取到的数据,做去重处理,如下图所示。如果评论已经在里边的话,就直接pass掉,如果没有的话,继续追加即可。
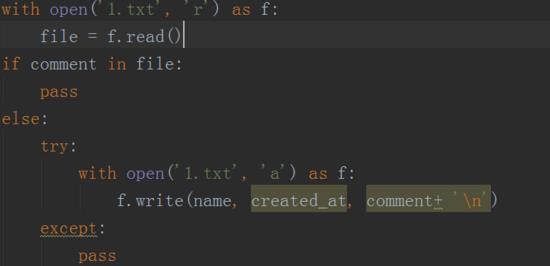
这项工作到此就基本完成了。
【Part3——总结篇】
这种方法虽然抓不全数据,但在这种微博的限制条件下,也是一种比较有效的方法
内容总结
以上是互联网集市为您收集整理的一篇文章教会你使用Python定时抓取微博评论全部内容,希望文章能够帮你解决一篇文章教会你使用Python定时抓取微博评论所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。