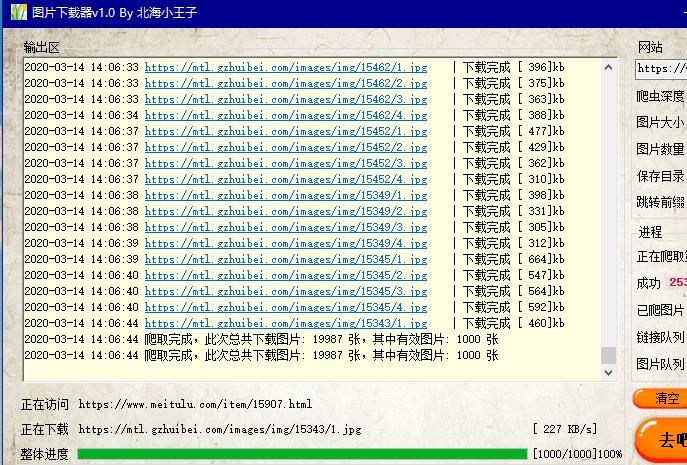
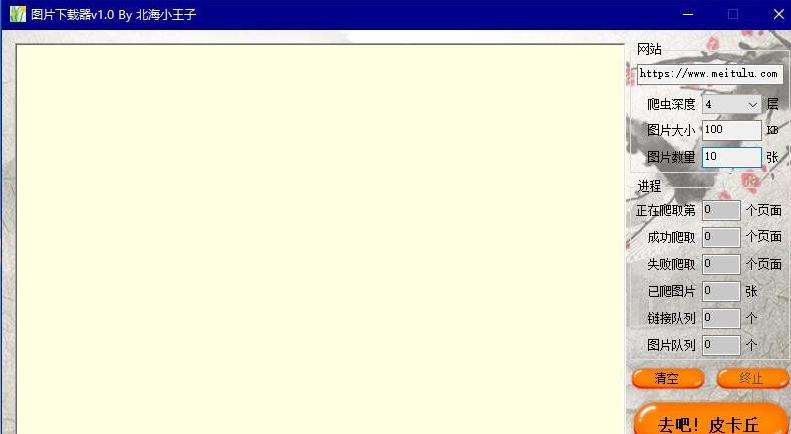
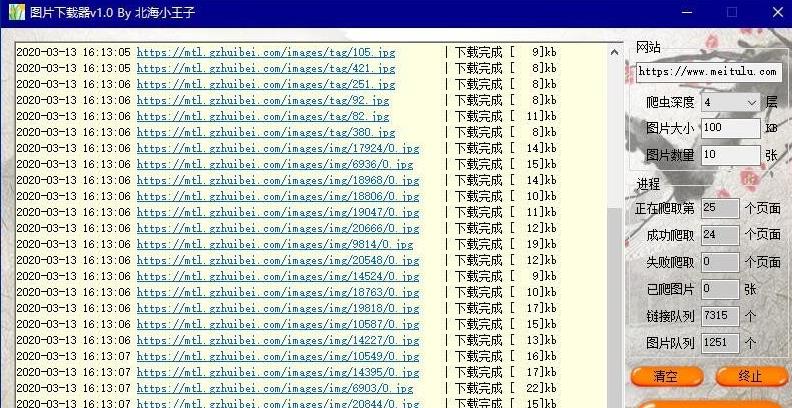
本文实例讲述了Go语言实现的web爬虫方法。分享给大家供大家参考。具体分析如下:这里使用 Go 的并发特性来并行执行 web 爬虫。
修改 Crawl 函数来并行的抓取 URLs,并且保证不重复。复制代码 代码如下:package main
import (
"fmt"
)
type Fetcher interface {
// Fetch 返回 URL 的 body 内容,并且将在这个页面上找到的 URL 放到一个 slice 中。
Fetch(url string) (body string, urls []string, err error)
}
/...
一、环境 项目:maven项目 数据库:mysql 二、项目介绍 我们要爬去的页面是https://shimo.im/doc/iKYXMBsZ5x0kui8P 假设我们需要进入这个页面,爬取页面里面的所有电影百度云链接,并保存在mysql数据库里。 三、pom.xml配置 首先我们需要新建一个maven项目,并在pom.xml配置如下jar包。<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http...
大数据时代虽然给我们的生活带来了很多的便利,但是往往我们想要获取或整理我们想要的资源却还是一件很难的事情,难在查找和搜寻资料,有了可共享数据的网站,却还要一页一页的点进去,筛选我们想要的信息,是不是很麻烦?是的,那么,这个时候你一定要有一个会写爬虫的朋友(或者男朋友^_^),前几次我们也已经实现了利用webcollector和htmlparser爬取网易云音乐和豆瓣图书,但是有很多网友评论说看不懂或者不明白,而且网上的资源...
一、网络爬虫的定义网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。
网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互...
一.前期准备,抓取HTML我们所需要关键信息 目标url:https://search.jd.com/Search?keyword=shouji&enc=utf-8&wq=shouji&pvid=a1727a28a24544829b30ef54d049feae 目标url其中page可以换页可以更改 然后跳转url转到相关数据页面: 跳转到手机详细页面我们需要找到手机相关信息eg:名称 价格 销量等 前期准备工作完成二.代码编写1.库的导入 2.函数功能 a.请求网页 b.数据处理 c.词云图设计 3.效果展示 ...
【项目愿景】系统基于智能爬虫方向对数据由原来的被动整理到未来的主动进攻的转变的背景下,将赋予”爬虫”自我认知能力,去主动寻找”进攻”目标。取代人工复杂而又单调的重复性工作。能够实现在人工智能领域的某一方向上独当一面的作用。【项目进展】项目一期基本实现框架搭建,对数据的处理和简单爬取任务实现。【项目说明】为了能够更好理解优秀框架的实现原理,本项目尽量屏蔽优秀开源第三方jar包实现,自定义实现后再去择优而...
前段时间自学了python,作为新手就想着自己写个东西能练习一下,了解到python编写爬虫脚本非常方便,且最近又学习了MongoDB相关的知识,万事具备只欠东风。程序的需求是这样的,爬虫爬的页面是京东的电子书网站页面,每天会更新一些免费的电子书,爬虫会把每天更新的免费的书名以第一时间通过邮件发给我,通知我去下载。一、编写思路: 1.爬虫脚本获取当日免费书籍信息 2.把获取到的书籍信息与数据库中的已有信息作比较,如果...
import time
from io import BytesIO
import randomimport requests
from selenium import webdriver
from selenium.webdriver import ActionChains
from PIL import Imageurl = "https://www.douban.com/"
browser = webdriver.Chrome(executable_path="E:/爬虫0基础入门/chromedriver_win32/chromedriver.exe")#2. 点击元素显示出有缺口的图片并下载
#3. 对比两张图片找出缺口的移动像素
#4. 拖动元素
url = "https://passport.b...
爬虫简单说来包括两个步骤:获得网页文本、过滤得到数据。 1、获得html文本。 python在获取html方面十分方便,寥寥数行代码就可以实现我们需要的功能。 复制代码 代码如下:def getHtml(url): page = urllib.urlopen(url) html = page.read() page.close() return html 这么几行代码相信不用注释都能大概知道它的意思。 2、根据正则表达式等获得需要的内容。 使用正则表达式时需要仔细观察该网页信息的结构,并写出正确的正则...
今天分享下scrapy爬虫的基本使用方法,scarpy是一个比较成熟稳定的爬虫框架,方便了爬虫设计,有较强的逻辑性。我们以旅游网站为例进行介绍,一方面是旅游网站多,各个网站的适用情况不同,方便我们的学习。最后有网易云评论的一个爬取思路和不同的实现方法。 话不多说,下面是scrapy的框架:创建scrapy爬虫的命令可以在cmd中输入scrapy project XXXX之后创建蜘蛛文件使用scrapy genspider xxx "xxxx.com"接着初始化工作就做完了...
css规则:选择器,以及一条或者多条生命。selector{declaration1;,,,;desclarationN}每条声明是由一个属性和一个值组成property:value例子:h1{color:red;fontsize:14px} 元素选择器:直接选择文档元素比如head,p类选择器:元素的class属性,比如<h1 class =”important”>类名就是important.important选择所有有这个类属性的元素可以结合元素选择器,比如p.important
id选择器元素的id属性,比如<h1 id=”aa”>id就是aa#aa用于选...
最近在学习Python,自然接触到了爬虫,写了一个小型爬虫软件,从初始Url解析网页,使用正则获取待爬取链接,使用beautifulsoup解析获取文本,使用自己写的输出器可以将文本输出保存,具体代码如下:Spider_main.py# coding:utf8from baike_spider import url_manager, html_downloader, html_parser, html_outputerclass SpiderMain(object):def__init__(self):self.urls = url_manager.UrlManager()self.downloader = html_downlo...
昨晚用自己写的网络爬虫程序从某网站了下载了三万多张图片,很是爽快,今天跟大家分享几点内容。一、内容摘要1:Java也可以实现网络爬虫2:Jsoup.jar包的简单使用3:可以爬某网站的图片,动图以及压缩包4:可以考虑用多线程加快下载速度二、准备工作1:安装Java JDK2:下载Jsoup.jar3:安装Eclipse或其他编程环境4:新建一个Java项目,导入Jsoup.jar三、步骤1:用Java.net包联上某个网址获得网页源代码2:用Jsoup包解析和迭代源代码...
编写tasks.py 代码如下:from celery import Celeryfrom tornado.httpclient import HTTPClientapp = Celery(tasks)app.config_from_object(celeryconfig)@app.taskdef get_html(url): http_client = HTTPClient() try: response = http_client.fetch(url,follow_redirects=True) return response.body except httpclient.HTTPError as e: return None http_client.close()
编写celeryconfig.py 代...
在swoole中,php可以借助其启动子进程的方式,实现php的多进程:<?php
$s_time = time();
echo 开始时间:.date(H:i:s,$s_time).PHP_EOL;
//进程数
$work_number=6;//
$worker=[];//模拟地址
$curl=[https://blog.csdn.net/feiwutudou,https://wiki.swoole.com/wiki/page/215.html,http://fanyi.baidu.com/?aldtype=16047#en/zh/manager,http://wanguo.net/Salecar/index.html,http://o.ngking.com/themes/mskin/login/login.jsp,http...