python day6 小知识点总结 str转bytes类型
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python day6 小知识点总结 str转bytes类型,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1815字,纯文字阅读大概需要3分钟。
内容图文

------------恢复内容开始------------
1. python2 ,python3的区别
python2 ascii码 python3 UTF-8
python2 prin 支持不加括号 python不支持
python中有range 还有Xrange(生成器) python只有range有序列表
python中用户交互 raw_input python3为input
2. = ,== ,is(比较内存地址) ,id(内容)查看id
= 赋值
== 比较值是否相等
is 比较内存地址
li1 = [1,2,3]
li1 = li2
print(li1 is li2)
print(id(li1),id(li2))
3.分类 数字,字符串 小数据值
数字-5-256范围内 变量对应值一致 ,共同使用一个内存地址
字符串范围使用同一个内存地址 1.不可包含特殊字符 2.s*20 同一个地址 ,s*21两个地址
i1 = 6
i2 = 6
print(id(i1),id(i2))
除了数字和str list 和 dict tuple set 没有小数据池概念
4.编码
ascii码 A :一个字符用一个字节表示 一个字节8位 0000100
unicode A :一个字符用四个字节表示 32位 00010001 0001010 00100010 00101010
utf-8 A: 一个字符用一个字节表示 8位 00101001 中:一个中文用三个字节表示24位 01010101 00100100 00101001
gbk A:一个字符用一个字节表示 8位 01010101 中: 一个中文用两个字节表示16位 01010101 00100101
1.各个编码之间的二进制是不可以互相识别的,会产生乱码
2.文件的储存和传输不能是unicode,只能是utf-8 或者utf-16 或者gbk 或者gbk2312 或者ascii 因为unicode占用流量太大
python3:
python3中的str在内存中的编码方式是unicode
bytes数据类型 str如果需要传输或存储 需要先转换为bytes数据类型
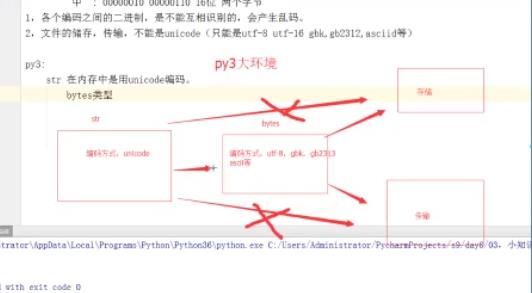
对于英文来说
str 表现形式 str = 'alex'
编码方式 01010101 unicode
bytes 表现形式 s = b’‘alex’ (前面加b表示)
编码方式:00100100 utf-8 gbk gk2312
对于中文来说
str 表现形式 str = '中国'
编码方式 01010101 unicode
bytes 表现形式 s = b‘x\e91\e91\e01\e21\e31\e32’ (16进制)
编码方式:00100100 utf-8 gbk gk2312
str 转换 bytes 英文
s1 = ‘alex’
s11 = s1.encode('utf-8')
print(s11)
str 转换bt\ytes 中文
s2 = ‘中国’
s22 = s2.encode('utf-8')
print(s22 )
------------恢复内容结束------------
内容总结
以上是互联网集市为您收集整理的python day6 小知识点总结 str转bytes类型全部内容,希望文章能够帮你解决python day6 小知识点总结 str转bytes类型所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。