Python高级应用程序设计任务要求
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python高级应用程序设计任务要求,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4275字,纯文字阅读大概需要7分钟。
内容图文

用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
NBA球员拉塞尔-威斯布鲁克生涯表现
2.主题式网络爬虫爬取的内容与数据特征分析
对NBA球员拉塞尔-威斯布鲁克生涯信息进行爬取分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
获取NBA球员拉塞尔-威斯布鲁克生涯信息,提取其中的赛况数据与比分累计。设计方案主要靠requests库结合beautifulsoup进行数据解析。技术难点主要是怎么对获取的信息做可视图分析。
技术路线:requests beautifulsoup
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
https://nba.hupu.com/players/russellwestbrook-3016.html
2.Htmls页面解析



3. 节点(标签)查找方法与遍历方法
(必要时画出节点树结构)

利用find标签进行查找
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
2.对数据进行清洗和处理
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
程序代码:
# -*- coding: utf-8 -*-
import requests
import pandas as pd
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
list = [] #数据数组
def getWeb(url):
#获取网页数据
try:
r = requests.get(url)
r.raise_for_status()
return r.text
except:
return "响应失败"
def getdata(html):
#初始化
soup = BeautifulSoup(html, "html.parser")
#选择器
table = soup.select("table.players_table.bott.bgs_table > tbody > tr.color_font1.borders_btm")
#循环取出每组数据
for tables in table:
datas = tables.get_text().split('\n')
#去掉数据里的空元素
for i in datas:
if len(i) == 0:
datas.remove(i)
#加入数据组
list.append(datas)
#保存数据
fo = open("russellwestbrook.txt", "w+")
#循环取出每组数据
for datas in list:
#内循环单数据
for i in datas:
fo.writelines(i + " ")
print(i)
#大循环换行
fo.writelines("\n")
fo.close()
def table(html):
#设置空列表保存数据
list=[]
soup = BeautifulSoup(html, "html.parser")
#寻找球员各对手战队数据的助攻数,并添加进列表
for i in soup.find_all('tr' ,class_='color_font1 borders_btm'):
j=i.select('td')[11].text
list.append(j)
#将前六个对手战队的助攻数作为整型返回
results = ([int(x) for x in list[2:8]])
#设置图表绘制模式
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
#绘制图表
s=pd.Series([results[0],results[1],results[2],results[3],results[4],results[5]],['马刺','魔术','骑士','国王','太阳','猛龙'])
s.plot(kind='bar',title='助攻数量')
plt.show()
if __name__=='__main__':
html = getWeb("https://nba.hupu.com/players/russellwestbrook-3016.html")
getdata(html)
table(html)
运行结果:



- 数据爬取与采集
# -*- coding: utf-8 -*- import requests import pandas as pd import matplotlib.pyplot as plt from bs4 import BeautifulSoup list = [] #数据数组 def getWeb(url): #获取网页数据 try: r = requests.get(url) r.raise_for_status() return r.text except: return "响应失败" def getdata(html): #初始化 soup = BeautifulSoup(html, "html.parser") #选择器 table = soup.select("table.players_table.bott.bgs_table > tbody > tr.color_font1.borders_btm") #循环取出每组数据 for tables in table: datas = tables.get_text().split('\n') #去掉数据里的空元素 for i in datas: if len(i) == 0: datas.remove(i) #加入数据组 list.append(datas) - 数据取出与保存
#保存数据 fo = open("russellwestbrook.txt", "w+") #循环取出每组数据 for datas in list: #内循环单数据 for i in datas: fo.writelines(i + " ") print(i) #大循环换行 fo.writelines("\n") fo.close() def table(html): #设置空列表保存数据 list=[] soup = BeautifulSoup(html, "html.parser") #寻找球员各对手战队数据的助攻数,并添加进列表 for i in soup.find_all('tr' ,class_='color_font1 borders_btm'): j=i.select('td')[11].text list.append(j) #将前六个对手战队的助攻数作为整型返回 results = ([int(x) for x in list[2:8]]) - 数据可视化
#设置图表绘制模式 plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['font.family'] = 'sans-serif' #绘制图表 s=pd.Series([results[0],results[1],results[2],results[3],results[4],results[5]],['马刺','魔术','骑士','国王','太阳','猛龙']) s.plot(kind='bar',title='助攻数量') plt.show() if __name__=='__main__': html = getWeb("https://nba.hupu.com/players/russellwestbrook-3016.html") getdata(html) table(html)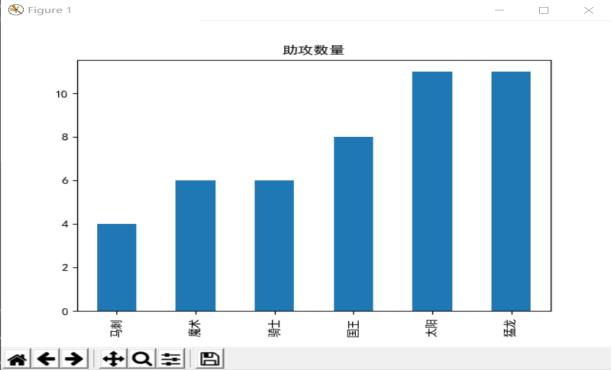
- 经过对主题数据的分析与可视化,可以得到哪些结论?
易看出助攻的数量在猛龙与太阳队最多,在马刺队最少。
- 对本次程序设计任务完成的情况做一个简单的小结。
由于自己对于requests库的不熟练,无法把爬虫做到面面俱到,经过这次任务加深了我对python爬虫的认识也加深了我对爬虫学习的兴趣。
内容总结
以上是互联网集市为您收集整理的Python高级应用程序设计任务要求全部内容,希望文章能够帮你解决Python高级应用程序设计任务要求所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。