首页 / PYTHON / Python高级应用程序设计任务
Python高级应用程序设计任务
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python高级应用程序设计任务,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含12455字,纯文字阅读大概需要18分钟。
内容图文

Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
同城帮二手苹果手机的爬取
2.主题式网络爬虫爬取的内容与数据特征分析
爬虫爬取的内容:
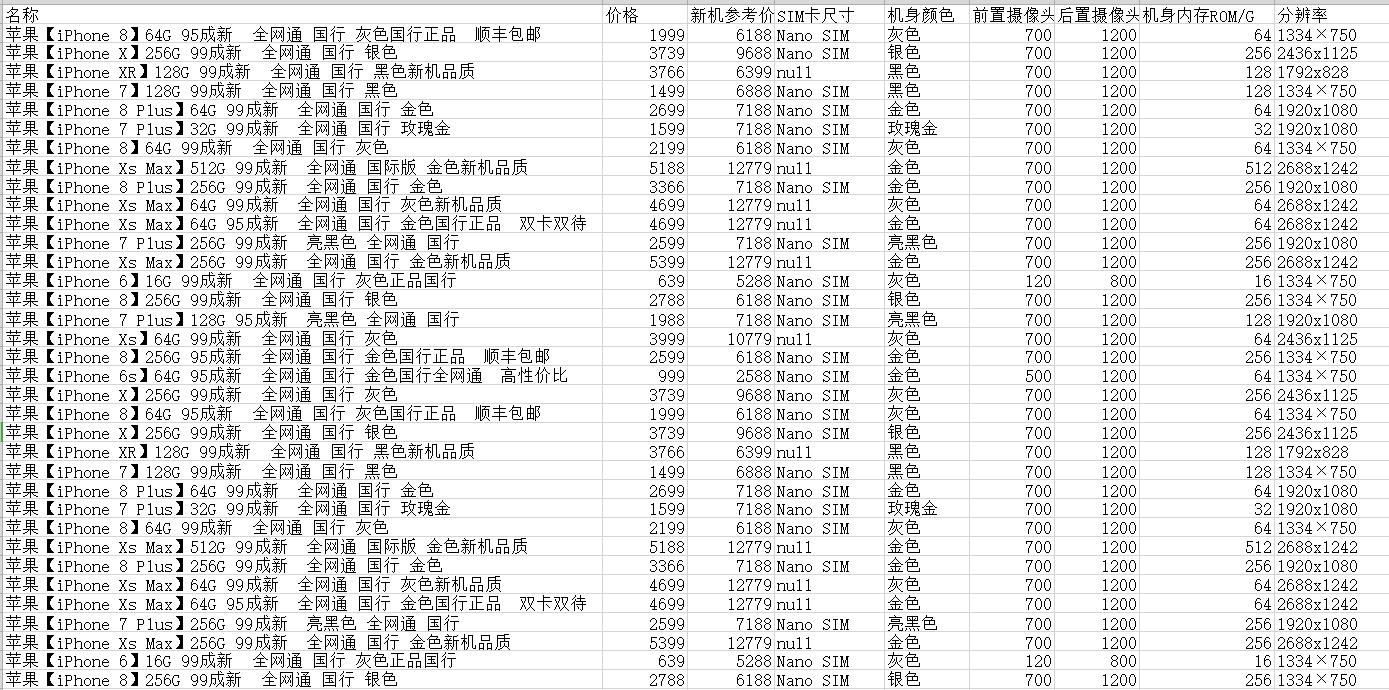
标题,名称,价格,新机参考价,SIM卡尺寸,机身颜色,前置摄像头像素,后置摄像头像素,机身内存,分辨率。
数据特征分析:
比较机身内存和价格之间的关系,并建立可视化图
获取机身内内存容量占比情况,进行可视化
比较前后摄像头像素和价格之间的关系,并建立数据模型图
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
利用requests中get方法请求网页,如果状态码是200则继续下一步
通过循环利用xpath获取每个网页下面详情页面的url
利用xpath获取每个详情页面的数据,并判断所要获取的数据是否在每个详情页面的特定位置
通过循环进行翻页处理,并把数据存储在指定位置
技术难点:
部分所要获取的数据信息存在空值。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
同城帮网页共47页每页20项数据,每页的数据都是静态的。按F12进入网页HTML代码,可以发现要获取的数据都在div标签下。
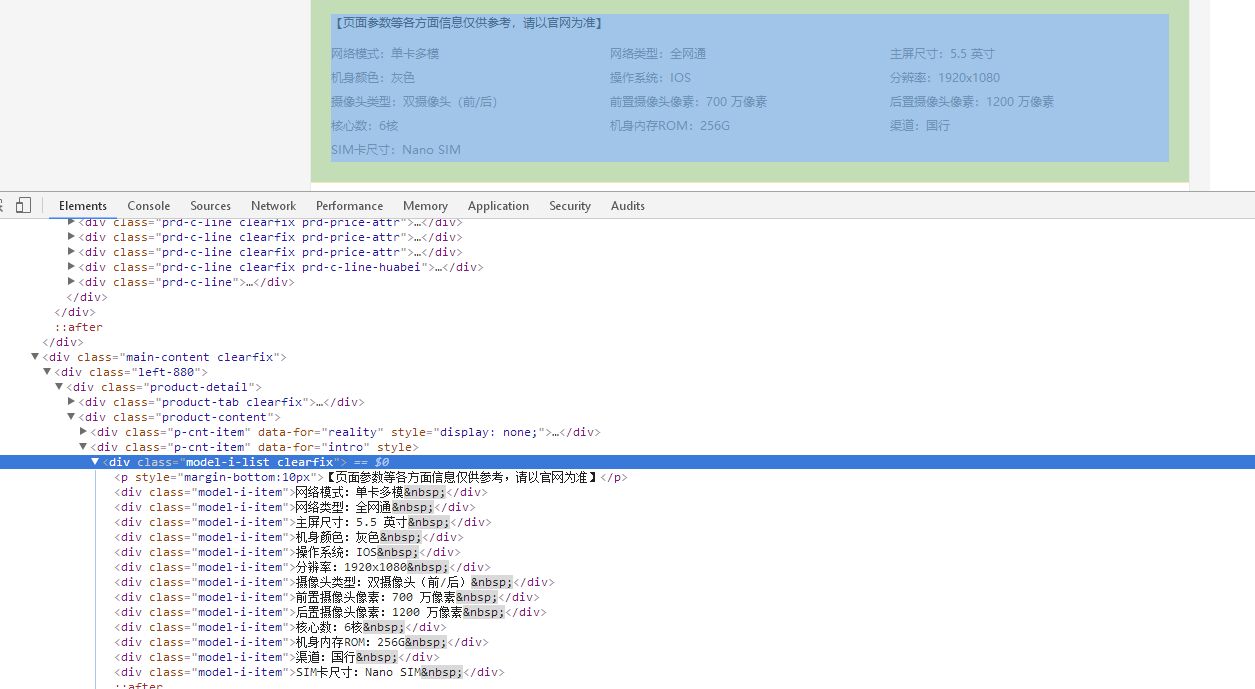

2.Htmls页面解析
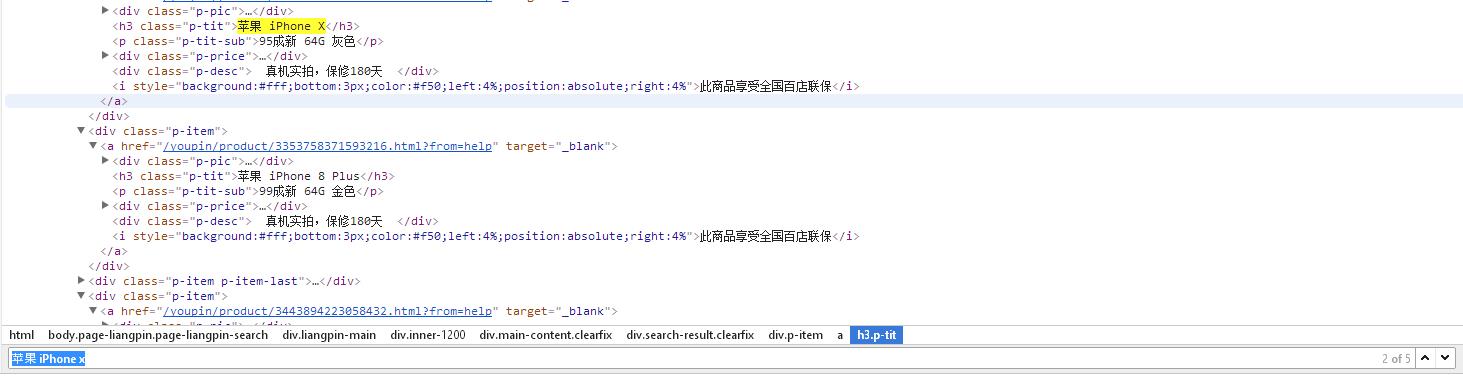
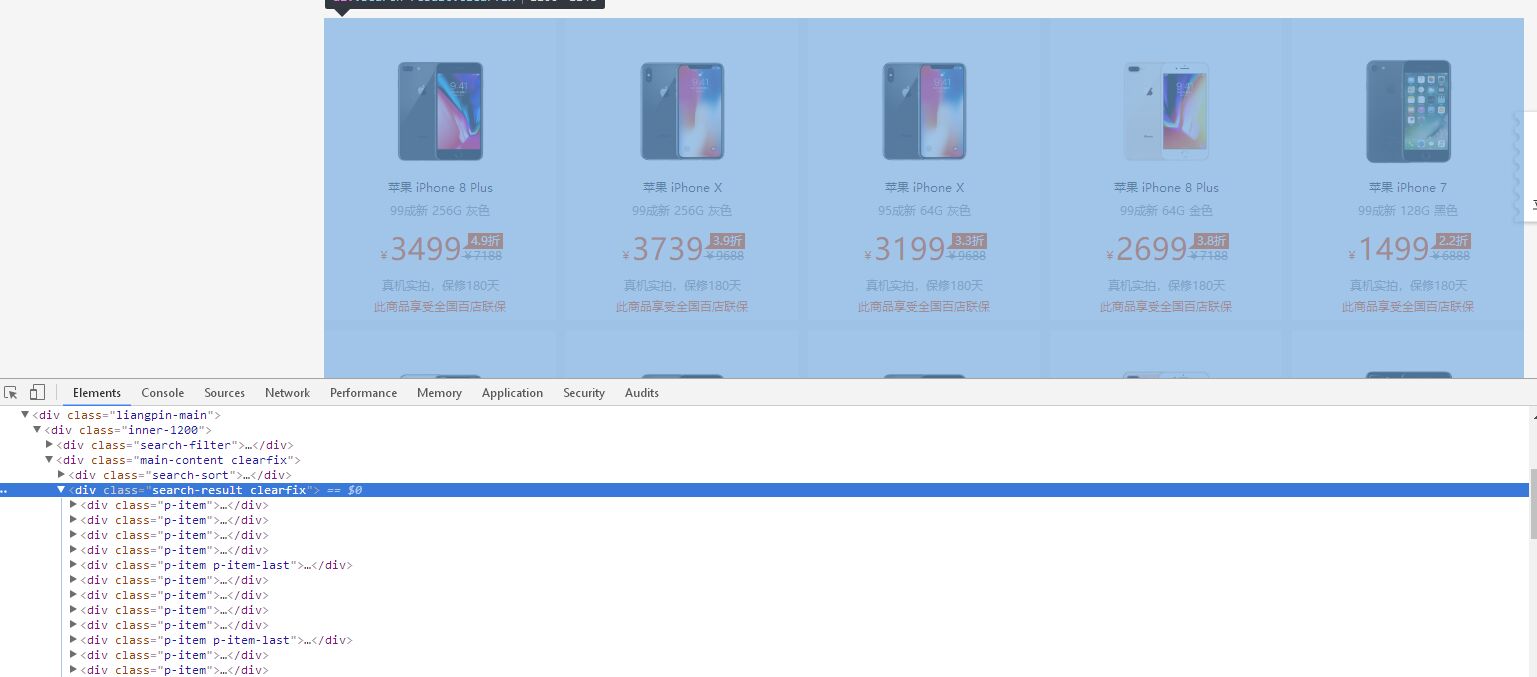
利用BeautifulSoup语法解析网站页面,并解析要获取的内容,通过解析可以发现我们想要获取的数据是在div标签下,div class=”search-result clearfix”下class="p-item"下的a标签中
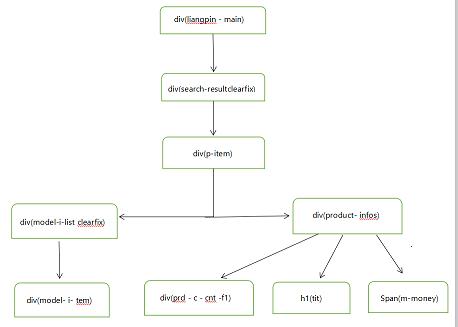
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
节点的查找利用xpath方法,解析网页下的节点。遍历方法利用for循环方法,实现对div标签的全部遍历。
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
from operator import contains
import requests
from lxml import etree
from bs4 import BeautifulSoup
from pandas import DataFrame
import os
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
'Cookie': 'test_cookie_enable=null; __huid=11IyQjgRXq+X6T46lzx2UgqjxOuAbeUq4tQDhue0PUbuQ=; __guid=214012238.4477127272234200064.1575253447001.0742; cid=119; UM_distinctid=16efd85610b80e-0df6f53071f2f9-34564a7c-144000-16efd85610cb7b; CNZZDATA1259008268=545082855-1576209056-https%253A%252F%252Fwww.sogou.com%252F%7C1576209056; Hm_lvt_3792a17d88db1d642cabc993daa66b8d=1576211407,1576211437; test_cookie_enable=null; Hm_lpvt_3792a17d88db1d642cabc993daa66b8d=1576212651; bang_session=eyJpdiI6IjFaUTlnbGhWazNkNFwvUjVVSmVIUFlBPT0iLCJ2YWx1ZSI6Iktpb3pGT1JQVVRZXC9xQnlvaFVcL0M2NUVWbFVlWmVpTERWR1lcL2dvdDRPVXBYa2M4WXFsNDd5eFE1aWMzWmJHVDRDTFRKMVdxdFkrTkxjY2dreExsS0pRPT0iLCJtYWMiOiIzMzJlMjc0ZWU0YTIyYzhlNDc3YTRkZTI1NjliMWEwOTFhZTFlMzIwYmFmZGI4MzgwNTkxOGI1ZjdlN2VjOWMzIn0%3D; client_citycode=eyJpdiI6ImU3QlwvK1c5SVpLQ3FLZGdodzlJYnp3PT0iLCJ2YWx1ZSI6Ikc1R3VFVUF5WVZ6bTVPN2t1eTluM3c9PSIsIm1hYyI6ImJlNTNlODM4YWQxNDRmY2I4MzA5NGUwOWU1NjQ1OGQyMDFhNjk0OThiMjdmMTI3NTkxMjE3ODZiM2EzYWRlYTMifQ%3D%3D; client_cityname=eyJpdiI6InluQ2VOQ3BFMGx6RU5pbFA2M29iXC9RPT0iLCJ2YWx1ZSI6Im1GOWdlOXlibFRQRzBMU09pM0JpVWc9PSIsIm1hYyI6ImU4NDYwMDY3MDAwMjY0ZjA5N2VlYTEzNTI2Y2YyNDk4Zjc3ZWQwY2I5ZGFiYzBlYzdlOGM0NjhkMTNmMTEzYmUifQ%3D%3D'
}
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'tongchenban_data.csv')
def getdiv_url(url):
resp = requests.get(url, headers=headers)
text = resp.content.decode('utf-8')
# print(text)
html = etree.HTML(text)
# print(html)
div =html.xpath('//div[@class="search-result clearfix"]')[0]
# print(div)
divs =div.xpath('./div')
# print(divs)
div_urls=[]
for div in divs:
div_url=div.xpath('./a/@href')
div_url='https://bang.360.cn'+div_url[0]
# print(div_url)
div_urls.append(div_url)
return(div_urls)
def getxiangxi(url):
text = requests.get(url, headers=headers)
resp = text.content.decode('utf-8')
html = etree.HTML(resp)
# print(html)
#获取标题
Iphone_Goods = {}
name =html.xpath('//div[@class="product-infos"]/h1/text()')[0]
# print(name)
#获取价格
Iphone_price=html.xpath('//div[@class="product-price"]//span[@class="m-money"]/span/text()')[0]
# print(price)
#获取新机的参考价格
newprice=html.xpath('//div[@class="prd-c-line clearfix"]//div[@class="prd-c-cnt fl"]/span/text()')
if(len(newprice)==0):
newprice='null'
else:
newprice=newprice[0].split('¥')[1]
# print(newprice)
jishen=html.xpath('//div[@class="model-i-list clearfix"]/div[@class="model-i-item"]/text()')
# print(jishen)
Iphone_Key=[]
Iphone_Value=[]
for i in jishen:
Iphone_Key.append(i.split(":")[0])
Iphone_Value.append(i.split(":")[1])
if('SIM卡尺寸' in Iphone_Key):
index=Iphone_Key.index('SIM卡尺寸')
Iphone_SIM=Iphone_Value[index].strip()
else:
Iphone_SIM ='null'
if ('机身颜色' in Iphone_Key):
index = Iphone_Key.index('机身颜色')
Iphone_Color = Iphone_Value[index].strip()
else:
Iphone_Color = 'null'
if ('前置摄像头像素' in Iphone_Key):
index = Iphone_Key.index('前置摄像头像素')
Iphone_Front = Iphone_Value[index].strip().split(r' 万像素')[0]
else:
Iphone_Front = 'null'
if ('后置摄像头像素' in Iphone_Key):
index = Iphone_Key.index('后置摄像头像素')
Iphone_Back = Iphone_Value[index].strip().split(r' 万像素')[0]
else:
Iphone_Back = 'null'
if ('机身内存ROM' in Iphone_Key):
index = Iphone_Key.index('机身内存ROM')
Iphone_ROM = Iphone_Value[index].strip().split(r'G')[0]
else:
Iphone_ROM = 'null'
if ('分辨率' in Iphone_Key):
index = Iphone_Key.index('分辨率')
Iphone_FenBianLv = Iphone_Value[index].strip()
else:
Iphone_FenBianLv = 'null'
Iphone_Goods['名称'] = name
Iphone_Goods['价格']=Iphone_price
Iphone_Goods['新机参考价'] = newprice
Iphone_Goods['SIM卡尺寸'] = Iphone_SIM
Iphone_Goods['机身颜色'] = Iphone_Color
Iphone_Goods['前置摄像头像素/万像素'] = Iphone_Front
Iphone_Goods['后置摄像头像素/万像素'] = Iphone_Back
Iphone_Goods['机身内存ROM/G'] = Iphone_ROM
Iphone_Goods['分辨率'] = Iphone_FenBianLv
return (Iphone_Goods)
def main():
base_url = 'https://bang.360.cn/youpin/search?brand_id=2&from=index&attr[]=141&pn={}/'
for x in range(0,43): #循环实现翻页
url=base_url.format(x)
div_urls=getdiv_url(url)
# print(div_urls)
for div_url in div_urls:
Iphone_Goods=getxiangxi(div_url)
print(Iphone_Goods)
df = DataFrame(Iphone_Goods, index=[0])
if os.path.exists(file_path):
# 字符编码采用utf-8
df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") # 写入数据
else:
df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig")
if __name__ == '__main__':
main()
2.对数据进行清洗和处理
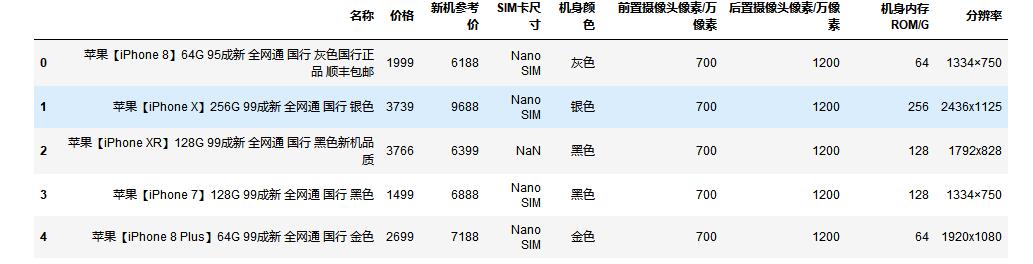
#利用DataFrame进行数据加载,并查看前5行数据
import pandas as pd
import numpy as np
df = pd.read_csv('E:/untitled/venv/tongchenban_data.csv')
df.head()
#删除无效列与行
df.drop('后置摄像头像素/万像素',axis=1,inplace=True)
df.head()

#重复值处理 df.duplicated()

df=df.drop_duplicates() df.head()

#空值与缺失值处理 df['SIM卡尺寸'].isnull().value_counts()

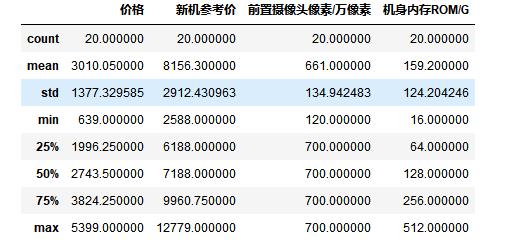
#异常值处理 df.describe()
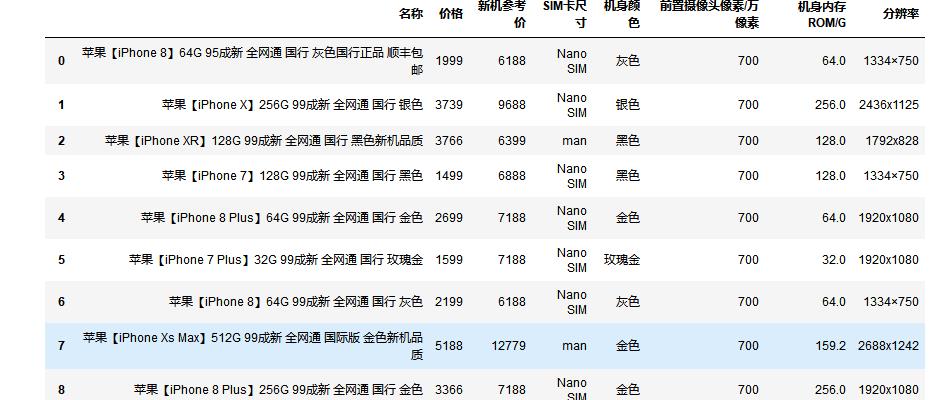
#将异常值替换成平均值 df.replace([512.000000],df['机身内存ROM/G'].mean())
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
4.1机身内存和价格之间的关系
import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.boxplot(x="机身内存ROM/G",y="价格",data=df)
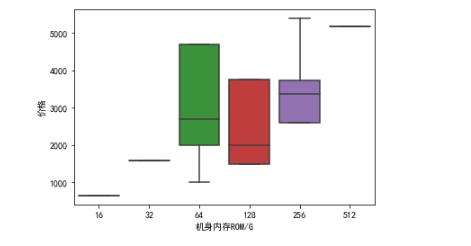
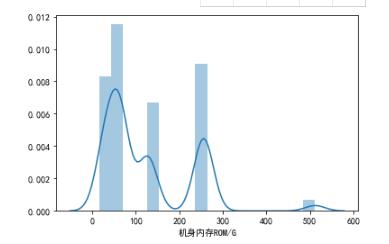
4.2机身内内存容量占比情况
import pandas as pd import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False sns.distplot(df['机身内存ROM/G'])
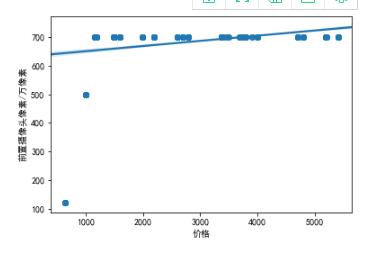
4.3比较前后摄像头像素和价格之间的关系
import pandas as pd import numpy as np sns.regplot(df["价格"],df["前置摄像头像素/万像素"])
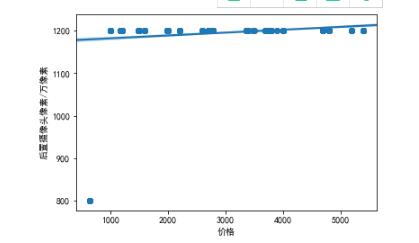
import pandas as pd import numpy as np sns.regplot(df["价格"],df["后置摄像头像素/万像素"])
4.4价格占比情况
import numpy as np df["价格"].quantile(np.arange(0,1,0.1))
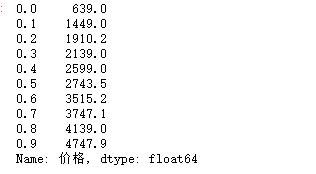
5.数据持久化
6.附完整程序代码
from operator import contains
import requests
from lxml import etree
from bs4 import BeautifulSoup
from pandas import DataFrame
import os
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400',
'Cookie': 'test_cookie_enable=null; __huid=11IyQjgRXq+X6T46lzx2UgqjxOuAbeUq4tQDhue0PUbuQ=; __guid=214012238.4477127272234200064.1575253447001.0742; cid=119; UM_distinctid=16efd85610b80e-0df6f53071f2f9-34564a7c-144000-16efd85610cb7b; CNZZDATA1259008268=545082855-1576209056-https%253A%252F%252Fwww.sogou.com%252F%7C1576209056; Hm_lvt_3792a17d88db1d642cabc993daa66b8d=1576211407,1576211437; test_cookie_enable=null; Hm_lpvt_3792a17d88db1d642cabc993daa66b8d=1576212651; bang_session=eyJpdiI6IjFaUTlnbGhWazNkNFwvUjVVSmVIUFlBPT0iLCJ2YWx1ZSI6Iktpb3pGT1JQVVRZXC9xQnlvaFVcL0M2NUVWbFVlWmVpTERWR1lcL2dvdDRPVXBYa2M4WXFsNDd5eFE1aWMzWmJHVDRDTFRKMVdxdFkrTkxjY2dreExsS0pRPT0iLCJtYWMiOiIzMzJlMjc0ZWU0YTIyYzhlNDc3YTRkZTI1NjliMWEwOTFhZTFlMzIwYmFmZGI4MzgwNTkxOGI1ZjdlN2VjOWMzIn0%3D; client_citycode=eyJpdiI6ImU3QlwvK1c5SVpLQ3FLZGdodzlJYnp3PT0iLCJ2YWx1ZSI6Ikc1R3VFVUF5WVZ6bTVPN2t1eTluM3c9PSIsIm1hYyI6ImJlNTNlODM4YWQxNDRmY2I4MzA5NGUwOWU1NjQ1OGQyMDFhNjk0OThiMjdmMTI3NTkxMjE3ODZiM2EzYWRlYTMifQ%3D%3D; client_cityname=eyJpdiI6InluQ2VOQ3BFMGx6RU5pbFA2M29iXC9RPT0iLCJ2YWx1ZSI6Im1GOWdlOXlibFRQRzBMU09pM0JpVWc9PSIsIm1hYyI6ImU4NDYwMDY3MDAwMjY0ZjA5N2VlYTEzNTI2Y2YyNDk4Zjc3ZWQwY2I5ZGFiYzBlYzdlOGM0NjhkMTNmMTEzYmUifQ%3D%3D'
}
file_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'tongchenban_data.csv')
def getdiv_url(url):
resp = requests.get(url, headers=headers)
text = resp.content.decode('utf-8')
# print(text)
html = etree.HTML(text)
# print(html)
div =html.xpath('//div[@class="search-result clearfix"]')[0]
# print(div)
divs =div.xpath('./div')
# print(divs)
div_urls=[]
for div in divs:
div_url=div.xpath('./a/@href')
div_url='https://bang.360.cn'+div_url[0]
# print(div_url)
div_urls.append(div_url)
return(div_urls)
def getxiangxi(url):
text = requests.get(url, headers=headers)
resp = text.content.decode('utf-8')
html = etree.HTML(resp)
# print(html)
#获取标题
Iphone_Goods = {}
name =html.xpath('//div[@class="product-infos"]/h1/text()')[0]
# print(name)
#获取价格
Iphone_price=html.xpath('//div[@class="product-price"]//span[@class="m-money"]/span/text()')[0]
# print(price)
#获取新机的参考价格
newprice=html.xpath('//div[@class="prd-c-line clearfix"]//div[@class="prd-c-cnt fl"]/span/text()')
if(len(newprice)==0):
newprice='null'
else:
newprice=newprice[0].split('¥')[1]
# print(newprice)
jishen=html.xpath('//div[@class="model-i-list clearfix"]/div[@class="model-i-item"]/text()')
# print(jishen)
Iphone_Key=[]
Iphone_Value=[]
for i in jishen:
Iphone_Key.append(i.split(":")[0])
Iphone_Value.append(i.split(":")[1])
if('SIM卡尺寸' in Iphone_Key):
index=Iphone_Key.index('SIM卡尺寸')
Iphone_SIM=Iphone_Value[index].strip()
else:
Iphone_SIM ='null'
if ('机身颜色' in Iphone_Key):
index = Iphone_Key.index('机身颜色')
Iphone_Color = Iphone_Value[index].strip()
else:
Iphone_Color = 'null'
if ('前置摄像头像素' in Iphone_Key):
index = Iphone_Key.index('前置摄像头像素')
Iphone_Front = Iphone_Value[index].strip().split(r' 万像素')[0]
else:
Iphone_Front = 'null'
if ('后置摄像头像素' in Iphone_Key):
index = Iphone_Key.index('后置摄像头像素')
Iphone_Back = Iphone_Value[index].strip().split(r' 万像素')[0]
else:
Iphone_Back = 'null'
if ('机身内存ROM' in Iphone_Key):
index = Iphone_Key.index('机身内存ROM')
Iphone_ROM = Iphone_Value[index].strip().split(r'G')[0]
else:
Iphone_ROM = 'null'
if ('分辨率' in Iphone_Key):
index = Iphone_Key.index('分辨率')
Iphone_FenBianLv = Iphone_Value[index].strip()
else:
Iphone_FenBianLv = 'null'
Iphone_Goods['名称'] = name
Iphone_Goods['价格']=Iphone_price
Iphone_Goods['新机参考价'] = newprice
Iphone_Goods['SIM卡尺寸'] = Iphone_SIM
Iphone_Goods['机身颜色'] = Iphone_Color
Iphone_Goods['前置摄像头像素/万像素'] = Iphone_Front
Iphone_Goods['后置摄像头像素/万像素'] = Iphone_Back
Iphone_Goods['机身内存ROM/G'] = Iphone_ROM
Iphone_Goods['分辨率'] = Iphone_FenBianLv
return (Iphone_Goods)
def main():
base_url = 'https://bang.360.cn/youpin/search?brand_id=2&from=index&attr[]=141&pn={}/'
for x in range(0,43): #循环实现翻页
url=base_url.format(x)
div_urls=getdiv_url(url)
# print(div_urls)
for div_url in div_urls:
Iphone_Goods=getxiangxi(div_url)
print(Iphone_Goods)
df = DataFrame(Iphone_Goods, index=[0])
if os.path.exists(file_path):
# 字符编码采用utf-8
df.to_csv(file_path, header=False, index=False, mode="a+", encoding="utf_8_sig") # 写入数据
else:
df.to_csv(file_path, index=False, mode="w+", encoding="utf_8_sig")
if __name__ == '__main__':
main()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.1苹果手机价格越高,手机的内存越高。
1.2苹果手机的内存大部分都是64G,128G,而且价格也都集中在这范围。
1.3苹果手机的价格大部分都处于2743到4747之间。
1.4苹果手机大部分前置摄像头像素都处于700左右,后置摄像头像素大部分都处于1200左右,而且前后置摄像头像素随着价格的增加而增加。
2.对本次程序设计任务完成的情况做一个简单的小结。
通过这次爬虫让我对python更加的了解和熟练的使用xpath以及对request库的使用,对爬虫更加有了兴趣,希望之间不断学习不断进步。
内容总结
以上是互联网集市为您收集整理的Python高级应用程序设计任务全部内容,希望文章能够帮你解决Python高级应用程序设计任务所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。