KNN算法
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了KNN算法,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1691字,纯文字阅读大概需要3分钟。
内容图文

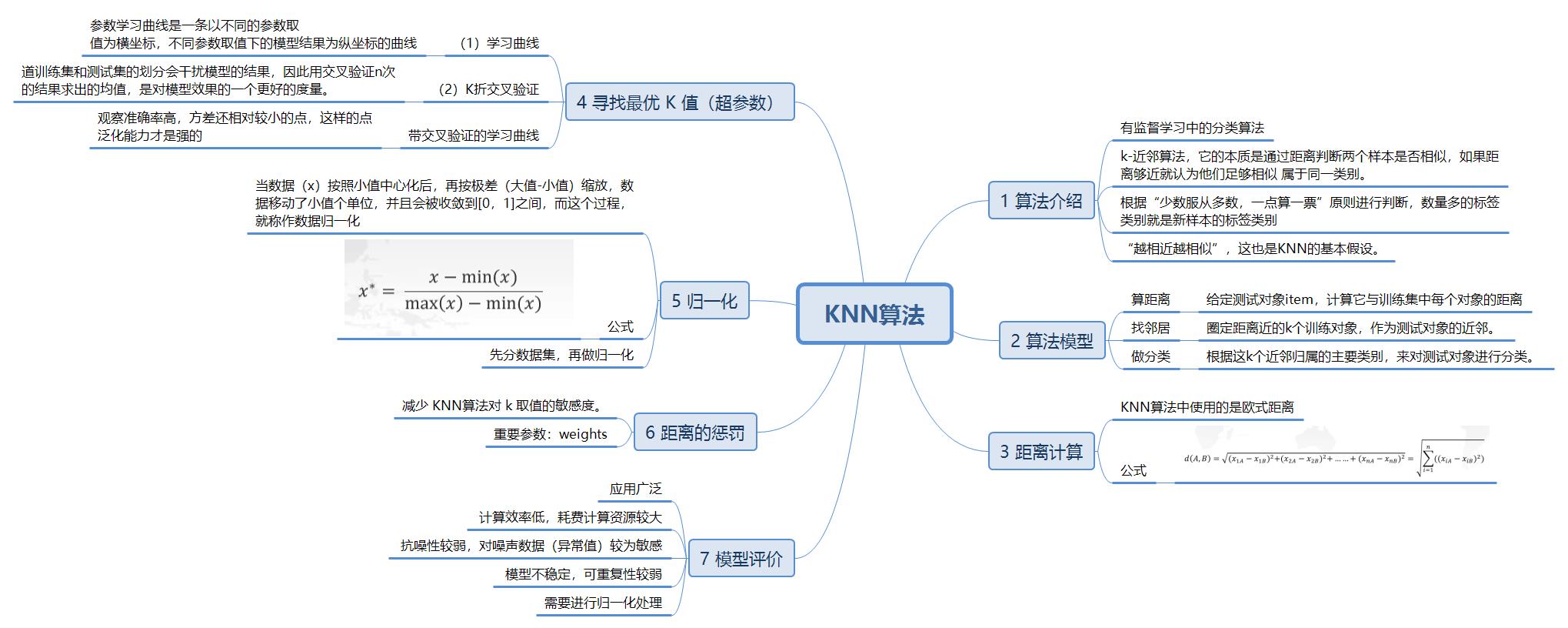
1、底层算法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#先随机设置十个样本点表示十杯酒
rowdata = {'颜色深度':[14.23,13.2,13.16,14.37,13.24,12.07,12.43,11.79,12.37,12.04],
'酒精浓度':[5.64,4.38,5.68,4.80,4.32,2.76,3.94,3. ,2.12,2.6 ],
'品种':[0,0,0,0,0,1,1,1,1,1]}
# 0代表黑皮诺 , 1代表赤霞珠
wine_data = pd.DataFrame(rowdata)
wine_data
X = np.array(wine_data.iloc[:,0:2])
X
y = np.array(wine_data.iloc[:,-1])
y
new_data = np.array([12.8,4.1]) #要判断的数据
# 1 算距离
from math import sqrt
distance = [sqrt(np.sum((x-new_data)**2)) for x in X]
distance
# 2 找邻居
sort_dist = np.argsort(distance) #排序 返回数组的索引
sort_dist
k = 3 #选取前3个样本
topK = [y[i] for i in sort_dist[:k]]
topK
# 3 做分类
from collections import Counter #对已有的数据类别进行计数,返回字典
votes = Counter(topK)
votes
predict = votes.most_common(1)[0][0] #排序,索引 次数出现最多的
predict
#打包成函数
def KNN(inx,dataset,k):
import numpy as np
import pandas as pd
from math import sqrt
from collections import Counter
result=[]
distance = [sqrt(np.sum((x-inx)**2)) for x in np.array(dataset.iloc[:,0:2])]
sort_dist = np.argsort(distance)
topK = [dataset.iloc[:,-1][i] for i in sort_dist[:k]]
result.append(Counter(topK).most_common(1)[0][0])
return result
KNN(new_data,wine_data,3)
2、sklearn实现
from sklearn.neighbors import KNeighborsClassifier # 调包 k近邻分类型
# 实例化(赋值的过程:将算法本身的模型赋值给一个变量)
clf = KNeighborsClassifier(n_neighbors=3)
# 训练模型
clf = clf.fit(X,y)
# 预测输出,返回预测的标签
result = clf.predict([[12.8,4.1]])
result
# 模型的评估,接口score返回预测的准确率
score = clf.score([[12.8,4.1]],[0])
score
# 返回预测的概率
clf.predict_proba([[12.8,4.1]])
内容总结
以上是互联网集市为您收集整理的KNN算法全部内容,希望文章能够帮你解决KNN算法所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】