python15
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python15,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含1808字,纯文字阅读大概需要3分钟。
内容图文

一、Scrapy项目创建
1.scrapy startproject ZhipinSpider
2.使用如下命令来开启 shell 调试
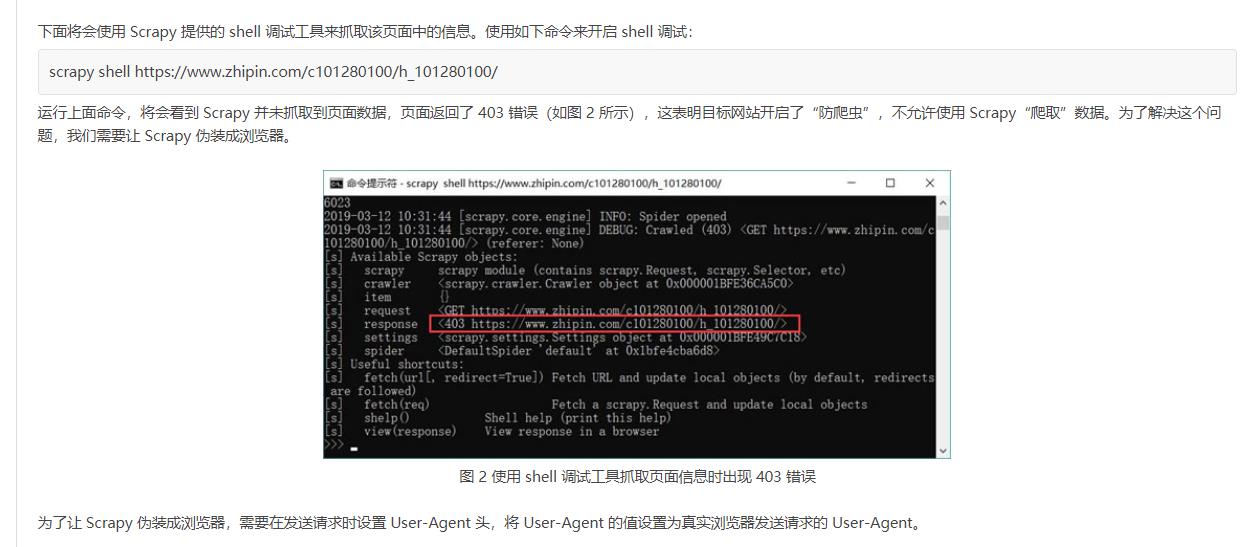
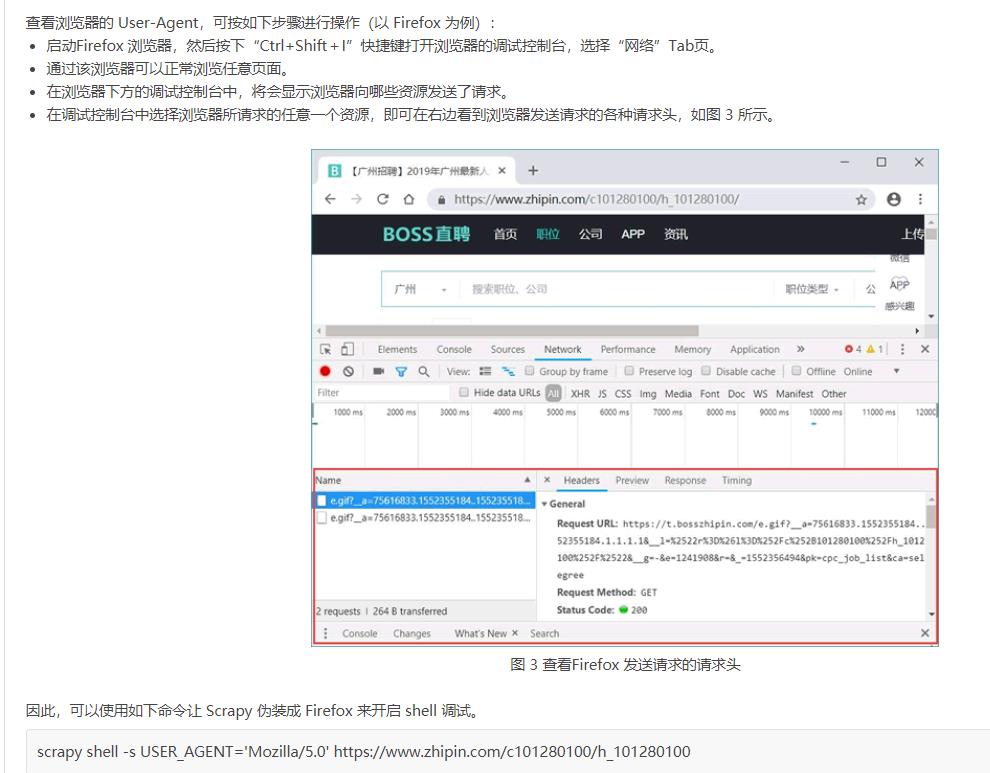


二、Scrapy爬虫项目开发过程详解


因此,开发者主要就是做两件事情:
1.将要爬取的各页面 URL 定义在 start_urls 列表中。
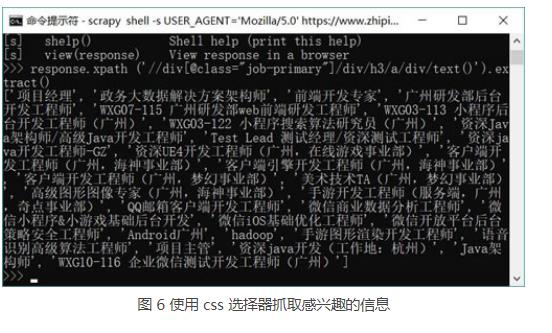
2.在 parse(self, response) 方法中通过 XPath 或 CSS 选择器提取项目感兴趣的信息。

extract()-------------------------------返回列表
extract()[0],extract_first()---------------------返回str
Spider 使用 yield 将 item 返回给 Scrapy 引擎之后,Scrapy 引擎将这些 item 收集起来传给项目的 Pipeline,因此自然就到了使用 Scrapy 开发爬虫的第二步。
三、编写 pipelines.py 文件,该文件负责将所爬取的数据写入文件或数据库中。

四、修改 settings.py 文件进行一些简单的配置,比如增加 User-Agent 头。取消 settings.py 文件中如下代码行的注释,并将这些代码行改为如下形式:



应该将上面这段代码放在 parse(self, response) 方法的后面,这样可以保证 Spider 在爬取页面中所有项目感兴趣的工作信息之后,才会向下一个页面发送请求。
上面程序中第 2 行代码解析页面中的“下一页”链接;第 7 行代码显式使用 scrapy.Request 来发送请求,并指定使用 self.parse 方法来解析服务器响应数据。需要说明的是,这是一个递归操作,即每当 Spider 解析完页面中项目感兴趣的工作信息之后,它总会再次请求“下一页”数据,通过这种方式即可爬取广州地区所有的热门职位信息。
scrapy.Request(new_line,callback=self.parse,dont_filter=True)
dont_filter=True ---------------------------------------------表示url不过滤
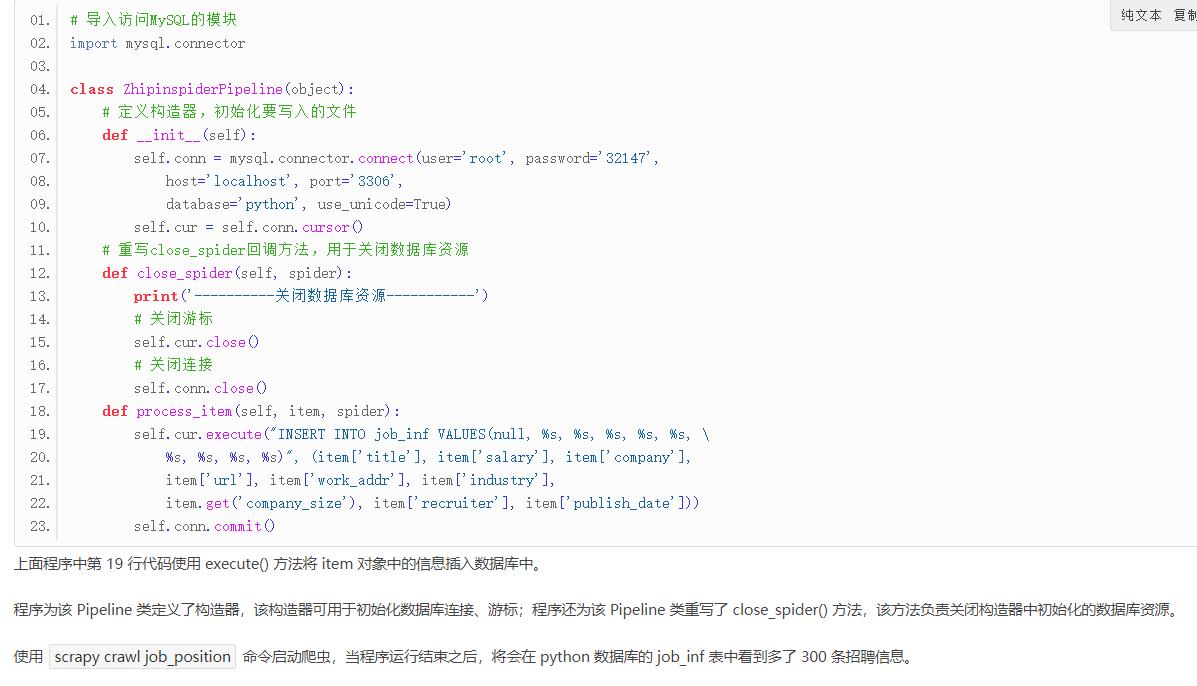
六、scrapy爬虫数据保存到MySQL数据库
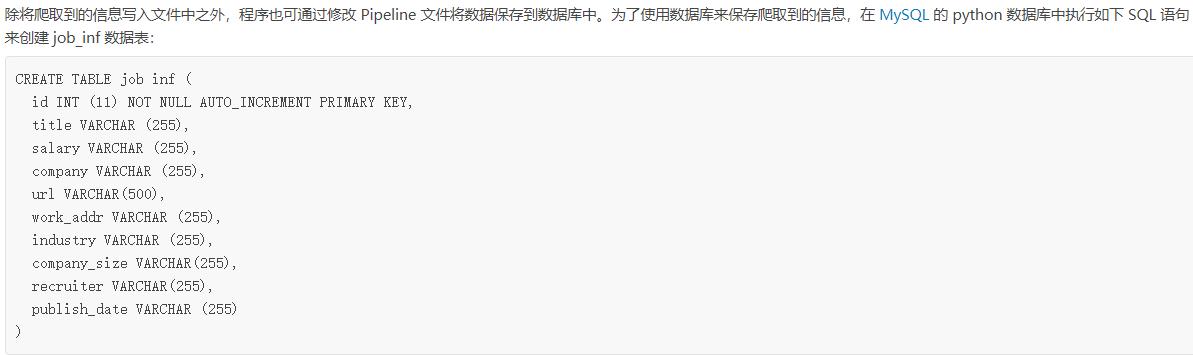
将 Pipeline 文件改为如下形式,即可将爬取到的信息保存到 MySQL 数据库中:
七、 Scrapy反爬虫常见解决方案(包含5种方法)
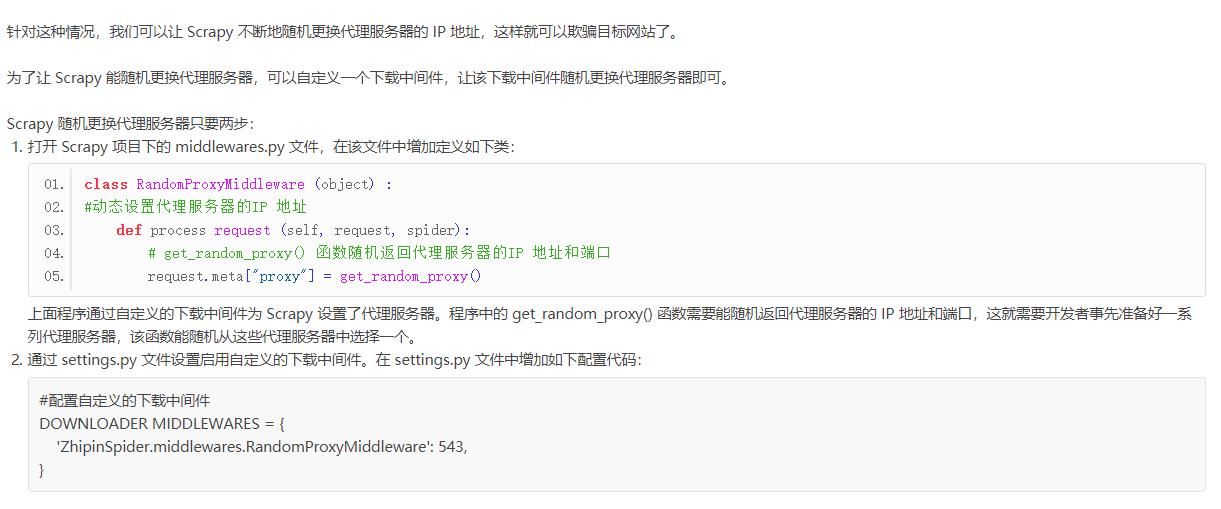
1.IP 地址验证
2.禁用Cookie

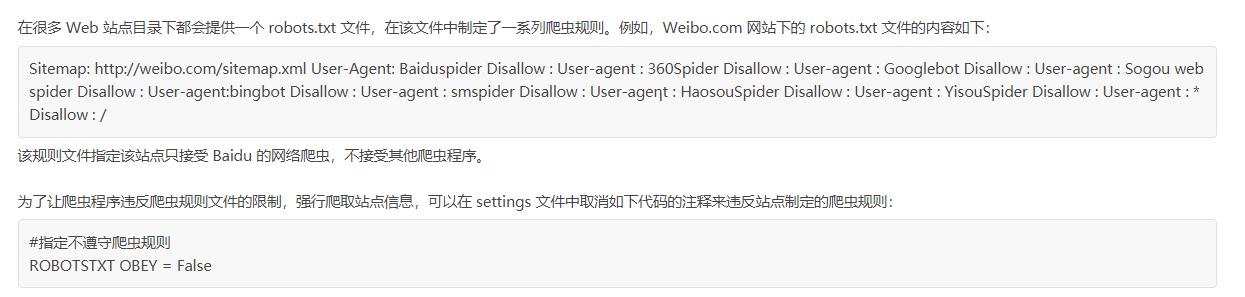
3.违反爬虫规则文件
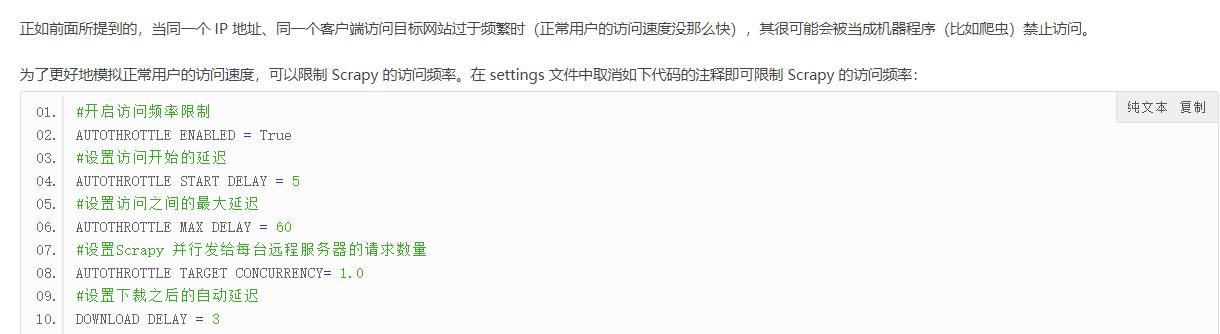
4.限制访问频率
5.图形验证码

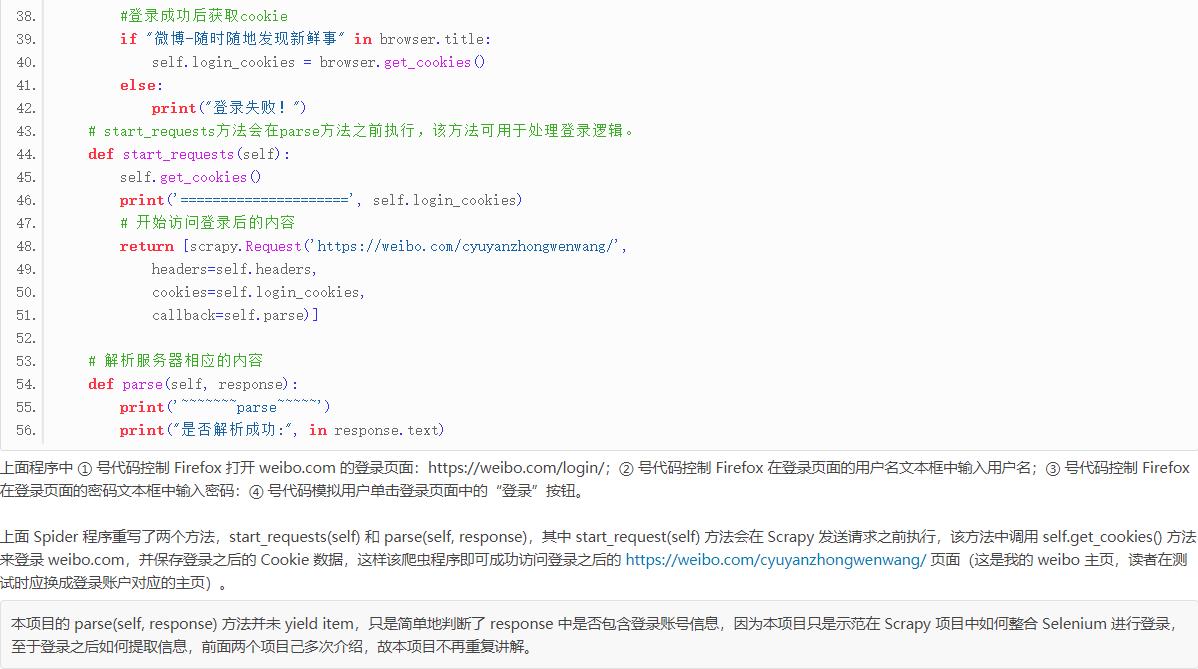
八、Selenium整合:启动浏览器并登陆
为了登录该网站,通常有两种做法:
1.直接用爬虫程序向网站的登录处理程序提交请求,将用户名、密码、验证码等作为请求参数,登录成功后记录登录后的 Cookie 数据。
2.使用真正的浏览器来模拟登录,然后记录浏览器登录之后的 Cookie 数据。



内容总结
以上是互联网集市为您收集整理的python15全部内容,希望文章能够帮你解决python15所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。