Python3 Selenium定位不到元素常见原因及解决办法
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python3 Selenium定位不到元素常见原因及解决办法,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含4437字,纯文字阅读大概需要7分钟。
内容图文

转自https://www.cnblogs.com/lizm166/p/9995612.html
一、问题描述
在做web应用的自动化测试时,定位元素是必不可少的,这个过程经常会碰到定位不到元素的情况:
报错信息: no such element: Unable to locate element: {"method":"xpath","selector":"xpath"}
二、分析以及解决方案
1,原因一以及解决方案
(1)原因:
Frame/Iframe原因定位不到元素:这个是最常见的原因,首先要理解下frame的实质,frame中实际上是嵌入了另一个页面,而webdriver每次只能在一个页面识别,因此需要先定位到相应的frame,对那个页面里的元素进行定位。
(2)解决方案:
如果iframe有name或id的话,直接使用switch_to_frame("name值")或switch_to_frame("id值")。如下:
driver=webdriver.Firefox()
driver.get(r'http://www.126.com/')
driver.switch_to_frame('x-URS-iframe') #需先跳转到iframe框架
username=driver.find_element_by_name('email')
username.clear()
如果iframe没有name或id的话,则可以通过下面的方式定位:
#先定位到iframe
elementi= driver.find_element_by_class_name('APP-editor-iframe')
#再将定位对象传给switch_to_frame()方法
driver.switch_to_frame(elementi)
如果完成操作后,可以通过switch_to.parent_content()方法跳出当前iframe,或者还可以通过switch_to.default_content()方法跳回最外层的页面。
2,原因二以及解决方案
(1)原因:
Xpath描述错误原因:由于Xpath层级太复杂,容易犯错。但是该定位方式能够有效定位绝大部分的元素,建议掌握。
(2)解决方案:
<1>.可以使用Firefox的firePath,复制xpath路径。该方式容易因为层级改变而需要重新编写过xpath路径,不建议使用,初学者可以先复制路径,然后尝试去修改它。
<2>.提高下写xpath的水平.
如何检验编写的Xpath是否正确?
编写好Xpath路径,可以直接复制到搜狐浏览器的firebug查看html源码,通过Xpath搜索:如下红色框,若无报错,则说明编写的Xpath路径没错。 例如:find_element_by_xpath("//input[@id='kw']")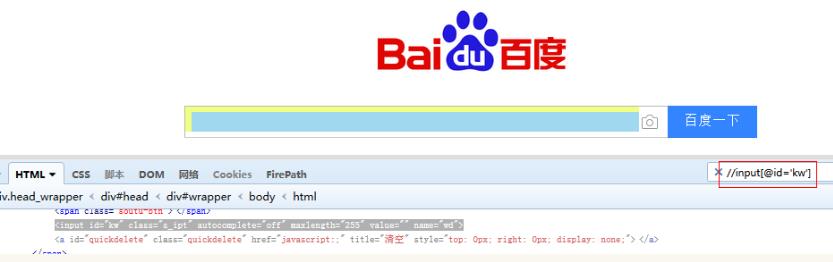
3,原因三以及解决方案
(1)原因
页面还没有加载出来,就对页面上的元素进行的操作:这种情况一般说来,可以设置等待,等待页面显示之后再操作,这与人手工操作的原理一样:
(2)解决方案
<1>.设置等待时间;缺点是需要设置较长的等待时间,案例多了测试就很慢; <2>.设置等待页面的某个元素出现,比如一个文本、一个输入框都可以,一旦指定的元素出现,就可以做操作。 <3>.在调试的过程中可以把页面的html代码打印出来,以便分析。导入时间模块。
import?timetime.sleep(3)
4,原因四以及解决方案
(1)原因
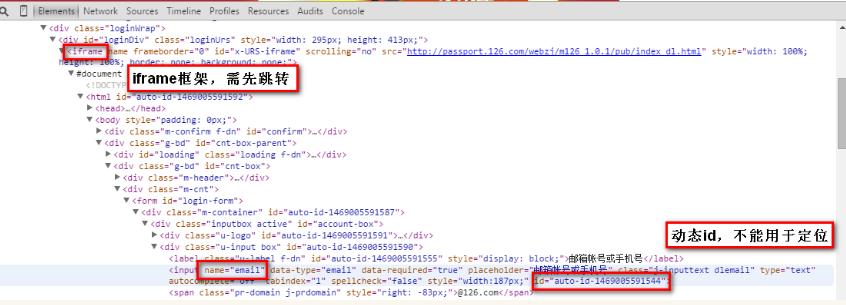
动态id定位不到元素:每次调用页面出现的元素的ID会动态随机分配。
(2)解决方案
如果发现是动态id,推荐使用xpath的相对路径方法查找到该元素。
5,原因五以及解决方案
(1)原因
二次定位,如弹出框登录:如百度登录弹出框登录百度账号,需先定位到百度弹出框,然后再定位到用户名密码登录。
(2)解决方案
'''
Project:登录百度账号
'''
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("http://www.baidu.com/")
time.sleep(3)
#点击登录:有些name为tj_login的元素为不可见的,点击可见的那个登录按钮即可。
#否则会报:ElementNotVisibleException
element0=driver.find_elements_by_name("tj_login")
for ele0 in element0:
if ele0.is_displayed():
ele0.click()
#在登录弹出框,需先定位到登录弹出框
#否则会报:NoSuchElementException
element1=driver.find_element_by_class_name("tang-content")
element11=element1.find_element_by_id("TANGRAM__PSP_8__userName")
element11.clear()
element11.send_keys("登录名")
element2=element1.find_element_by_id("TANGRAM__PSP_8__password")
element2.clear()
element2.send_keys("密码")
element3=element1.find_element_by_id("TANGRAM__PSP_8__submit")
element3.click()
element3.submit()
try:
assert "登录名" in driver.page_source
except AssertionError as e:
print "登录失败"
else:
print "登录成功"
time.sleep(3)
finally:
print "测试记录:已测试"
driver.close()
6,原因六以及解决方案
(1)原因
不可见元素定位:如上百度登录代码,通过名称为tj_login查找的登录元素,有些是不可见的。
(2)解决方案
加一个循环判断,找到可见元素(is_displayed())点击登录即可。
7,原因七以及解决方案
(1)原因
firefox安全性强,不允许跨域调用出现报错:因为firefox安全性强,不允许跨域调用。
(2)解决方案
Firefox 要取消XMLHttpRequest的跨域限制的话,
第一是从 about:config 里设置:signed.applets.codebase_principal_support = true; (地址栏输入about:config 即可进行firefox设置)
第二就是在open的代码函数前加入类似如下的代码:try{
netscape.security.PrivilegeManager.enablePrivilege("UniversalBrowserRead");
} catch (e) {
alert("Permission UniversalBrowserRead denied.");
}
8,原因八以及解决方案
(1)原因
窗口切换:窗口句柄还处在上一个窗口,导致无法定位新窗口的元素。
(2)解决方案
String currentWindow = driver.getWindowHandle();//获取当前窗口句柄
Set<String> handles = driver.getWindowHandles();//获取所有窗口句柄
for(String windowId : handles){
if(!windowId.equals(currentWindow)){
driver.switchTo().window(windowId);
System.out.println(driver.getCurrentUrl());
break;
}
}
内容总结
以上是互联网集市为您收集整理的Python3 Selenium定位不到元素常见原因及解决办法全部内容,希望文章能够帮你解决Python3 Selenium定位不到元素常见原因及解决办法所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。