深度学习算法(第6期)----深度学习之学习率的命运
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了深度学习算法(第6期)----深度学习之学习率的命运,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2741字,纯文字阅读大概需要4分钟。
内容图文
----深度学习之学习率的命运")
欢迎关注微信公众号“智能算法” – 原文链接(阅读体验更佳):
深度学习算法(第6期)----深度学习之学习率的命运
上一期,我们一起学习了深度学习中的优化器的进化,
今天我们一起看下学习率有着一个什么样的命运,我们多多交流,共同进步。本期主要内容如下:
- 学习率的影响
- 学习率的优化策略
- 学习率优化调节的实现
- 命运的安排
一. 学习率的影响
在深度学习中,寻找一个合适的学习率是比较困难的。在训练深度网络的过程中,如果学习率设置的过高,training学习曲线将会比较发散;如果学习率设置的过低,虽然训练最终会收敛到收敛到最优值,但是将会消耗很长的时间;如果学习率设置的稍微高,但是没那么高的话,training初期的将会下降很快,但是可能会在最优值附近一直震荡(除非用一个自适应学习率的优化器,但是仍需要花时间稳定到最优点);如果计算资源受限的话,可能会不得不中断学习,而得到一个次优点。如下图:
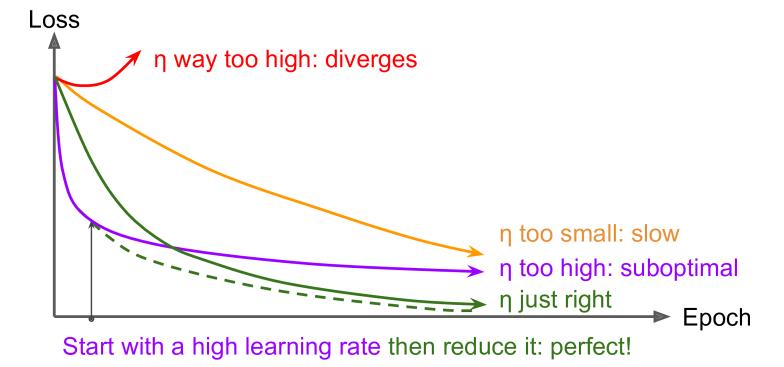
有时候,我们可以通过分别用几个不同的学习率来training几个epochs,通过比较这几个不同学习率的学习曲线来找到一个相对好一点的学习率。理想的学习率将会使学习过程很快,并很快收敛一个好的解。那么有哪些好的策略来优化学习率呢?
二. 学习率的优化策略
通常,如果我们一开始用一个高的学习率,而当学习进度没那么快的时候,降低学习率的话,会比用一个固定的学习率更快的得到一个最优解。在学习过程中调整学习率有以下几种常见的调整策略:
- 阶梯调节
在阶梯调节中,比方说可以在一开始设置一个学习率0.1,然后在50个epochs后降到0.01,到100个epochs后将到0.001等。
- 性能调节
性能调节是根据网络在验证集上的表现性能进行调节,在训练的过程中,不断的根据性能对学习率乘以一个衰减因子,来达到降低学习率的目的。
- 指数调节
指数调节是将学习率的衰减设计成迭代次数的函数,如下:

这样就能够根据迭代次数的增加而逐步的衰减学习率,但是需要去调整初始学习率η0和超参数r。
- 幂指调节
幂指调节跟指数调节有些类似,不同的是幂指调节将学习率衰减函数设计成幂指函数,如下:
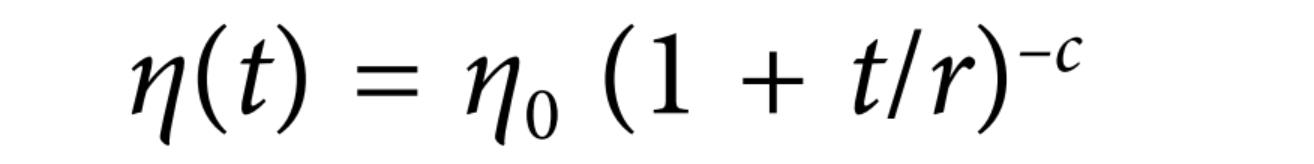
超参数c一般设置为1,幂指调节衰减的速度要比指数调节衰减的慢。
Andrew Senior在2013年的时候,用Momentum Optimization去优化一个语音识别的网络中对常见的调节学习率的方法进行了对比,得出一个结论:性能调节和指数调节都能够表现的非常好,但是由于指数调节比较好实施,并且收敛稍微快一点,所以倾向于指数调节。
三. 学习率优化调节的实现
在TensorFlow中学习率调节还是比较好实现的,如下是一个指数调节衰减的实现代码:

如上,在设置完超参数之后,创建一个nontrainable的全局变量(初始化为0)用来记录当前的迭代次数。然后根据超参数用exponential_decay定义一个指数衰减学习率。接下来创建一个动力优化的优化器,最后让优化器去最小化损失函数即可,非常简单。然而……
四. 命运的安排
在我们上节讲AdaGrad, RMSProp和Adam优化器出现之前,上面学到的调节学习率的方法还是很有用的,由于AdaGrad, RMSProp和Adam这三种优化器能够天生的自带调节学习率,而且效果还非常的不错,所以一般在用这三种优化器的时候,往往不再去人为调节学习率,也许这就是命运,这就是安排!
(如需更好的了解相关知识,欢迎加入智能算法社区,在“智能算法”公众号发送“社区”,即可加入算法微信群和QQ群)

内容总结
以上是互联网集市为您收集整理的深度学习算法(第6期)----深度学习之学习率的命运全部内容,希望文章能够帮你解决深度学习算法(第6期)----深度学习之学习率的命运所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。