Hadoop MapReduce例子(单词计数)-Java
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop MapReduce例子(单词计数)-Java,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3414字,纯文字阅读大概需要5分钟。
内容图文
-Java")
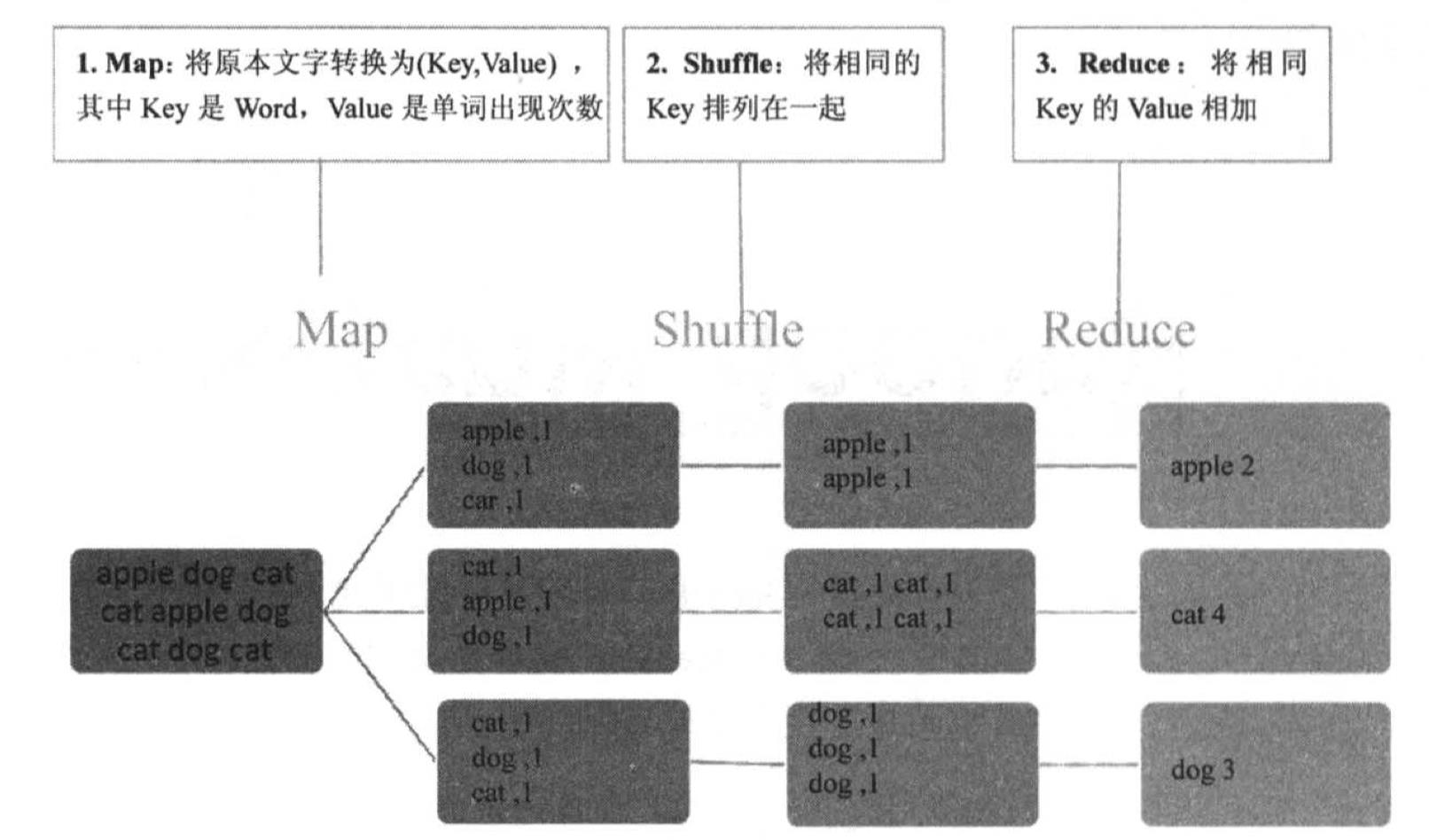
1.编写java代码
(1)创建wordcount测试目录
mkdir -p ~/wordcount/input
(2)切换至wordcount测试目录
cd ~/wordcount
(3)复制java代码
sudo gedit WordCount.java
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
2.编译java代码
(1)修改~/.bashrc
sudo gedit ~/.bashrc
export PATH=${JAVA_HOME}/bin:${PATH}
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
(2)~/.bashrc生效
source ~/.bashrc
(3)编译
hadoop com.sun.tools.javac.Main WordCount.java
(4)打包
jar cf wc.jar WordCount*.class
3.编写测试文本
(1)以LICENSE.txt为例
cp /usr/local/hadoop/LICENSE.txt ~/wordcount/input
ll ~/wordcount/input
4.上传测试文件至HDFS
(1)在HDFS创建目录
hadoop fs -mkdir -p /user/hduser/wordcount/input
(2)切换至~/wordcount/input目录
cd ~/wordcount/input
(3)上传文件到HDFS
hadoop fs -copyFromLocal LICENSE.txt /user/hduser/wordcount/input
(4)列出HDFS文件
hadoop fs -ls /user/hduser/wordcount/input
5.运行
(1)切换目录
cd ~/wordcount
(2)运行程序
hadoop jar wc.jar WordCount /user/hduser/wordcount/input/LICENSE.txt /user/hduser/wordcount/output
6.查看运行结果
(1)查看HDFS目录
hadoop fs -ls /user/hduser/wordcount/output
(2)查看运行结果
hadoop fs -cat /user/hduser/wordcount/output/part-r-00000|more
或
hadoop fs -get /user/hduser/wordcount/output/part-r-00000
内容总结
以上是互联网集市为您收集整理的Hadoop MapReduce例子(单词计数)-Java全部内容,希望文章能够帮你解决Hadoop MapReduce例子(单词计数)-Java所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。