knn算法详解
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了knn算法详解,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含6878字,纯文字阅读大概需要10分钟。
内容图文

邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。判断邻居就是用向量距离大小来刻画。
? ? ? ? ?kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 下图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?一张必不可少的图? ? ? ? K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。 ? ? ? ?KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的权值(weight),如权值与距离成反比。 ?
算法流程
1. 准备数据,对数据进行预处理 2. 选用合适的数据结构存储训练数据和测试元组 3. 设定参数,如k 4.维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列 5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax 6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。 7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。 8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。?[1优点 1.简单,易于理解,易于实现,无需估计参数,无需训练; 2. 适合对稀有事件进行分类; 3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好?
缺点
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。 该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。 可理解性差,无法给出像决策树那样的规则。 ? ? ? 好了前面的分析讲解千篇一律下面开始上代码 本文以Iris数据集(不知道可以百度)为例,用python实现knn算法(实际上就是调用几个库,底层的实现看一看算法流程想明白干啥就可以,一个库函数就搞定了手动滑稽) 下面给出相关代码: 1.Import dataset 导入数据集 ? ? ? ?先导入必要的库import numpy as np import matplotlib.pyplot as plt #绘图 import pandas as pd
再导入数据集
以excel格式为例,我的iris目标文件存储在
"D://test_knn"中
url = "D://test_knn./iris.csv" #url path # Assign column names to the dataset names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class'] # Read dataset to pandas dataframe dataset = pd.read_csv(url, names=names)
可以用下面函数检验导入是否成功
dataset.head() #默认读取前五行
输出结果如下:
sepal-length sepal-width petal-length petal-width Class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa
2.Preprocessing the dataset 数据预处理
x= dataset.iloc[:, :-1].values #x 属性 #第一个冒号是所有列,第二个是所有行,除了最后一个(Purchased) y = dataset.iloc[:, 4].values #y 标签 # 只取最后一个作为依赖变量。
3.Train Test Split
把数据划分成训练集和测试集
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
80%的数据划分到训练集,20%的数据划分到测试集
4.Feature scaling
normalization规范化处理(简单讲就是一组数据按照一定比例缩小或扩大至范数为1) 距离——采用简单直观的欧式距离(反正又不用你算) ?from sklearn.preprocessing import StandardScaler #导入库 这个不知道可以去查查用法 scaler = StandardScaler() scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test)
5.Training and Predictions 训练预测
from sklearn.neighbors import KNeighborsClassifier classifier = KNeighborsClassifier(n_neighbors=5) # k=5 classifier.fit(X_train, y_train)
y_pred=classifier.predict(X_test)
6.Evaluating the algorithm
from sklearn.metrics import classification_report, confusion_matrix print(confusion_matrix(y_test, y_pred)) print(classification_report(y_test, y_pred))
预期输出结果如下:
The output of the above script looks like this:
[[11 0 0]
0 13 0]
0 1 6]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 11
Iris-versicolor 1.00 1.00 1.00 13
Iris-virginica 1.00 1.00 1.00 6
avg/total 1.00 1.00 1.00 30
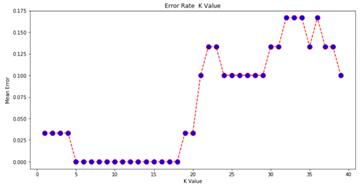
7.Comparing Error Rate with the K Value
把各种可能的k的取值,及其对应的分类误差率(error rate)绘制在一张图上。
error = []
# Calculating error for K values between 1 and 40
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
输出结果预期如下:
至此, 这套knn算法就实现了,现在体会到python工具包的强大了,好多底层的算法都不需要自己写函数实现。
搜了一下用C实现knn,代码很繁琐,但是很直观,每一步干什么很清楚。python写的话呢,如果对这些库不熟悉,那就很头秃了,需要一个一个函数查它的用法,不过,如果真的掌握了可以更快更轻松地实现。就是这样子了!
刚开始做的时候看到一堆代码,一脸懵逼,感觉在看文言文一样。其实只要耐心看,真的只是了解一点库函数用法,算法本身思想很简单!
第一个机器学习算法笔记,开心!
? ? ?内容总结
以上是互联网集市为您收集整理的knn算法详解全部内容,希望文章能够帮你解决knn算法详解所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。