首页 / 算法 / 机器学习之kNN算法
机器学习之kNN算法
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了机器学习之kNN算法,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含9102字,纯文字阅读大概需要14分钟。
内容图文

将系统更新机器学习部分教程
预计更新机器学习文章十几篇左右,篇篇原创。
参考
- 机器学习实战书籍(美国蜥蜴封面)
- sklearn官网
- 自己的学过的课程与经验
KNN算法介绍
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
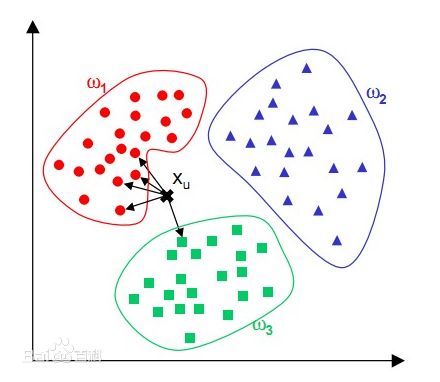
如图中的X,它离4个圆圈比较近,而离方形只有一个近,所以这个X就是圆圈这一类的
“近朱者赤,近墨者黑”可以说是 KNN 的工作原理。整个计算过程分为三步:
一、计算待分类物体与其他物体之间的距离;
二、统计距离最近的 K 个邻居;
三、对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪一类。
这样就出现了一个问题,就是距离怎么算
关于距离的计算方式有下面四种方式:
一、欧氏距离;
二、曼哈顿距离;
三、闵可夫斯基距离;
四、余弦距离。
欧氏距离:
是我们最常用的距离公式,也叫做欧几里得距离。在二维空间中,两点的欧式距离就是:
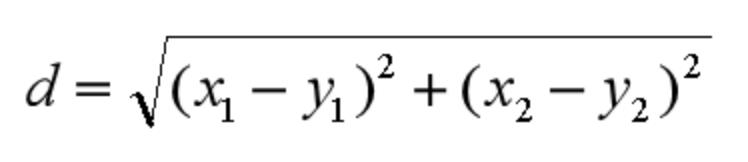 Image_text
Image_text注意: 因为我们以后可能涉及到N维的空间,所以为了方便我们将这里的两个点定义为(x1,x2,x3……,xn)和(y1,y2,y3……,yn) 所以这样我们两个点之间的距离就是按照上面这个式子来计算了。
同理,我们也可以求得两点在 n 维空间中的距离:
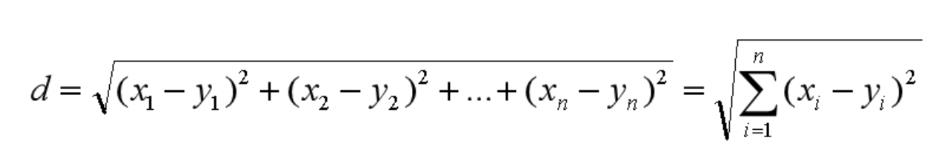 Image_text
Image_text曼哈顿距离
在几何空间中用的比较多。以下图为例,绿色的直线代表两点之间的欧式距离,而红色和黄色的线为两点的曼哈顿距离。所以曼哈顿距离等于两个点在坐标系上绝对轴距总和。用公式表示就是:
 在这里插入图片描述
在这里插入图片描述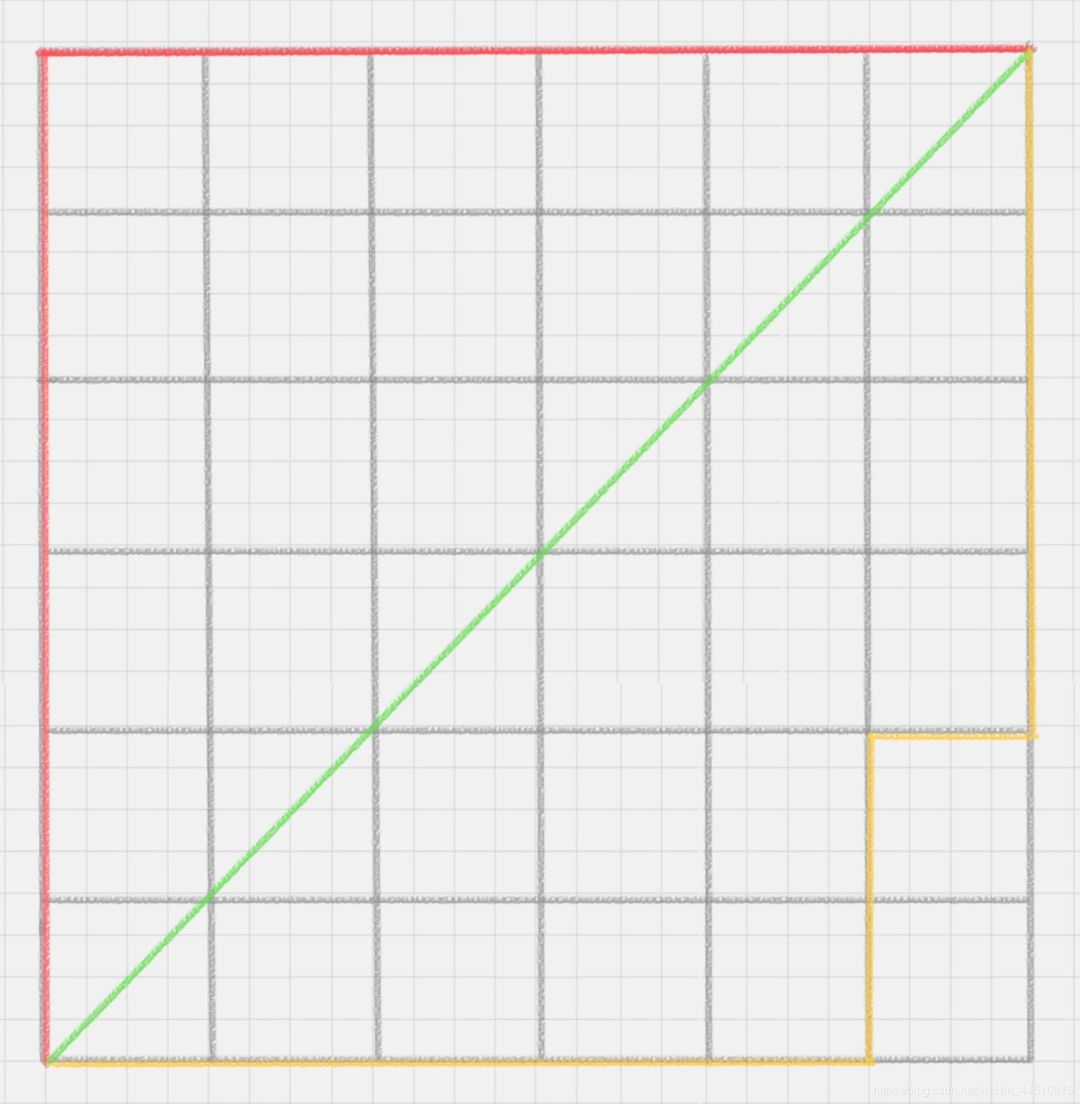 在这里插入图片描述
在这里插入图片描述闵可夫斯基距离:
闵可夫斯基距离不是一个距离,而是一组距离的定义。对于 n 维空间中的两个点 x(x1,x2,…,xn) 和 y(y1,y2,…,yn) , x 和 y 两点之间的闵可夫斯基距离为:
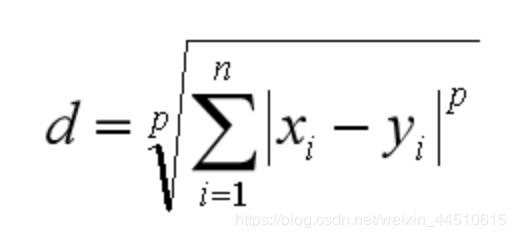 在这里插入图片描述
在这里插入图片描述其中 p 代表空间的维数,当 p=1 时,就是曼哈顿距离;当 p=2 时,就是欧氏距离;当 p→∞时,就是切比雪夫距离。
余弦距离:
余弦距离实际上计算的是两个向量的夹角,是在方向上计算两者之间的差异,对绝对数值不敏感。在兴趣相关性比较上,角度关系比距离的绝对值更重要,因此余弦距离可以用于衡量用户对内容兴趣的区分度。比如我们用搜索引擎搜索某个关键词,它还会给你推荐其他的相关搜索,这些推荐的关键词就是采用余弦距离计算得出的。
KD 树
KNN 的计算过程是大量计算样本点之间的距离。 为了减少计算距离次数,提升 KNN 的搜索效率,人们提出了 KD 树(K-Dimensional 的缩写)。KD 树是对数据点在 K 维空间中划分的一种数据结构。在 KD 树的构造中,每个节点都是 k 维数值点的二叉树。既然是二叉树,就可以采用二叉树的增删改查操作,这样就大大提升了搜索效率。
手写knn算法
主要写的是分类算法
from?collections?import?Counter??#?导入投票
import?numpy?as?np
def?euc_dis(instance1,?instance2):
????"""
????计算两个样本instance1和instance2之间的欧式距离
????instance1:?第一个样本,?array型
????instance2:?第二个样本,?array型
????"""
????#?距离平方公式
????dist?=?np.sqrt(sum((instance1?-?instance2)**2))
????return?dist
def?knn_classify(X,?y,?testInstance,?k):
????"""
????给定一个测试数据testInstance, 通过KNN算法来预测它的标签。?
????X:?训练数据的特征
????y:?训练数据的标签
????testInstance:?测试数据,这里假定一个测试数据?array型
????k:?选择多少个neighbors??
????"""
????#?返回testInstance的预测标签?=?{0,1,2}
????distances?=?[euc_dis(x,?testInstance)?for?x?in?X])
????#?排序
????kneighbors?=?np.argsort(distances)[:k]
????#?count是一个字典
????count?=?Counter(y[kneighbors])
????#?count.most_common()[0][0])是票数最多的
????return?count.most_common()[0][0]
KNN 可以用来做回归也可以用来做分类
一、使用sklearn做分类:
?from?sklearn.neighbors?import?KNeighborsClassifier
二、使用sklearn做回归:
from?sklearn.neighbors?import?KNeighborsRegressor
KNeighborsClassifier的分类方法参数
KNeighborsClassifier方法中有几个重要的参数:
KNeighborsClassifier(n_neighbors=5,?weights=‘uniform’,?algorithm=‘auto’,?leaf_size=30)
n_neighbors:即 KNN 中的 K 值,代表的是邻居的数量。K 值如果比较小,会造成过拟合。如果 K 值比较大,无法将未知物体分类出来。一般我们使用默认值 5。
weights:是用来确定邻居的权重,有三种方式:
一、weights=uniform,代表所有邻居的权重相同;
二、weights=distance,代表权重是距离的倒数,即与距离成反比;
algorithm:用来规定计算邻居的方法,它有四种方式:
一、algorithm=auto,根据数据的情况自动选择适合的算法,默认情况选择 auto;
二、algorithm=kd_tree,也叫作 KD 树,是多维空间的数据结构,方便对关键数据进行检索,不过 KD 树适用于维度少的情况,一般维数不超过 20,如果维数大于 20 之后,效率反而会下降;
三、algorithm=ball_tree,也叫作球树,它和 KD 树一样都是多维空间的数据结果,不同于 KD 树,球树更适用于维度大的情况;
四、algorithm=brute,也叫作暴力搜索,它和 KD 树不同的地方是在于采用的是线性扫描,而不是通过构造树结构进行快速检索。当训练集大的时候,效率很低。
leaf_size:代表构造 KD 树或球树时的叶子数,默认是 30,调整 leaf_size 会影响到树的构造和搜索速度。
实战
数据采用的是经典的iris数据,是三分类问题
#?读取相应的库
from?sklearn?import?datasets
from?sklearn.model_selection?import?train_test_split
from?sklearn.neighbors?import?KNeighborsClassifier
import?numpy?as?np
#?读取数据?X,?y
iris?=?datasets.load_iris()
X?=?iris.data
y?=?iris.target
print?(X,?y)
#?把数据分成训练数据和测试数据
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?random_state=2003)
#?构建KNN模型,?K值为3、?并做训练
clf?=?KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train,?y_train)
#?计算准确率
from?sklearn.metrics?import?accuracy_score
#?np.count_nonzero找出不是0的数
correct?=?np.count_nonzero((clf.predict(X_test)==y_test)==True)#?35
#accuracy_score(y_test,?clf.predict(X_test))
print?("Accuracy?is:?%.3f"?%(correct/len(X_test)))??#?35/38
上面手写了knn分类算法
predictions?=?[knn_classify(X_train,?y_train,?data,?3)?for?data?in?X_test]
correct?=?np.count_nonzero((predictions==y_test)==True)
#accuracy_score(y_test,?clf.predict(X_test))
print?("Accuracy?is:?%.3f"?%(correct/len(X_test))
#Accuracy?is:?0.921
knn算法解决回归
在我的学习笔记中找了一份二手车估计案例
百度网盘链接:https://pan.baidu.com/s/1TV4RQseo6bVd9xKJdmsNFw
提取码:8mm4
import?pandas?as?pd
import?matplotlib
import?matplotlib.pyplot?as?plt
import?numpy?as?np
import?seaborn?as?sns
df?=?pd.read_csv('data.csv')
df.head()??#?data?frame
df的head
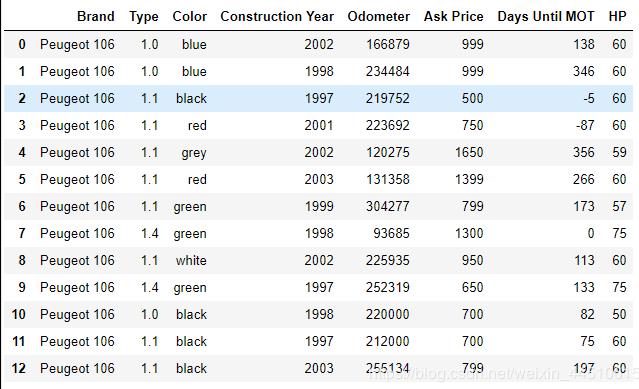
数据集说明:
ASk price 是预测目标,其他都是X
如何处理
Color中的数据是字符,onehot编码
Type 只有三个类型,onehot编码
Brand 数据没用
onehot编码解决方法get_dummies
#清洗数据
#?把颜色独热编码
df_colors?=?df['Color'].str.get_dummies().add_prefix('Color:?')
#?把类型独热编码
df_type?=?df['Type'].apply(str).str.get_dummies().add_prefix('Type:?')
#?添加独热编码数据列
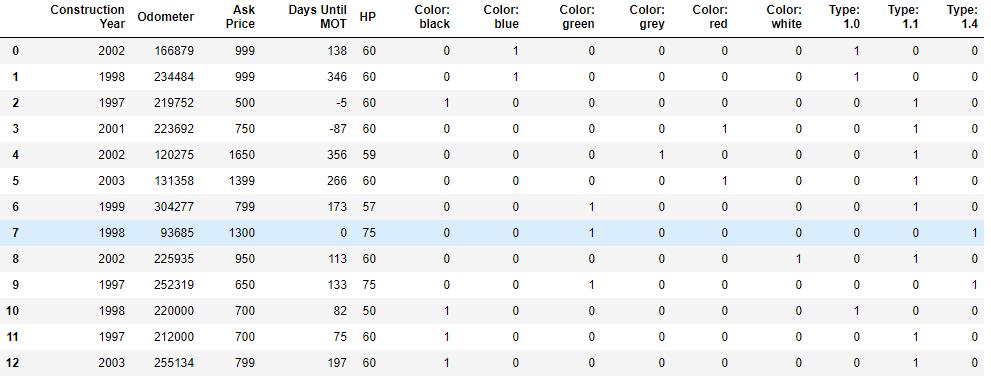
df?=?pd.concat([df,?df_colors,?df_type],?axis=1)
#?去除独热编码对应的原始列
df?=?df.drop(['Brand',?'Type',?'Color'],?axis=1)
df
df数据如图:
矩阵相关图
#?矩阵相关图
matrix?=?df.corr()
f,?ax?=?plt.subplots(figsize=(8,?6))
sns.heatmap(matrix,?square=True)
plt.title('Car?Price?Variables')
效果如图
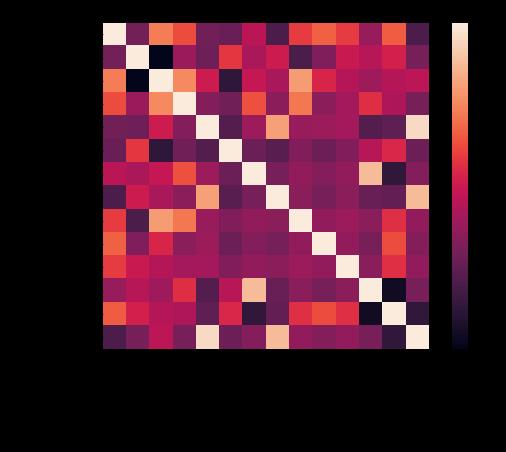
为什么要绘制矩阵相关图呢?
是因为要寻找最重要的数据

就是它们四个,其中一个是目标数据y,其余三个就是X
from?sklearn.neighbors?import?KNeighborsRegressor
from?sklearn.model_selection?import?train_test_split
from?sklearn?import?preprocessing
from?sklearn.preprocessing?import?StandardScaler
import?numpy?as?np
X?=?df[['Construction?Year',?'Days?Until?MOT',?'Odometer']]
#?reshape(-1,?1)?很关键?将pandas的Series?转化为numpy的array
y?=?df['Ask?Price'].values.reshape(-1,?1)
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?test_size=0.3,?random_state=41)
#?标准化
X_normalizer?=?StandardScaler()?#?N(0,1)
X_train?=?X_normalizer.fit_transform(X_train)
X_test?=?X_normalizer.transform(X_test)
y_normalizer?=?StandardScaler()
y_train?=?y_normalizer.fit_transform(y_train)
y_test?=?y_normalizer.transform(y_test)
knn?=?KNeighborsRegressor(n_neighbors=2)
knn.fit(X_train,?y_train)
y_pred?=?knn.predict(X_test)
#?inverse_transformjj将标准化的数据还原
y_pred_inv?=?y_normalizer.inverse_transform(y_pred)
y_test_inv?=?y_normalizer.inverse_transform(y_test)
from?sklearn.metrics?import?mean_absolute_error
#?平方相对误差
mean_absolute_error(y_pred_inv,?y_test_inv)
#?175.5
from?sklearn.metrics?import?mean_squared_error
#?均方误差
mean_squared_error(y_pred_inv,?y_test_inv)
#?56525.5
kNN扩展
探究K的影响
import?matplotlib.pyplot?as?plt
import?numpy?as?np
from?itertools?import?product
#?knn分类
from?sklearn.neighbors?import?KNeighborsClassifier
#?生成一些随机样本
n_points?=?100
#?multivariate_normal多元高斯
X1?=?np.random.multivariate_normal([1,50],?[[1,0],[0,10]],?n_points)
X2?=?np.random.multivariate_normal([2,50],?[[1,0],[0,10]],?n_points)
X?=?np.concatenate([X1,X2])
y?=?np.array([0]*n_points?+?[1]*n_points)
print?(X.shape,?y.shape)?
#?(200,?2)?(200,)
product方法的讲解
from?itertools?import?product
product('ab',?range(3))?-->?('a',0)?('a',1)?('a',2)?('b',0)?('b',1)?('b',2)
不断地改变k,探究KNN模型的训练过程
#?KNN模型的训练过程
clfs?=?[]
neighbors?=?[1,3,5,9,11,13,15,17,19]
for?i?in?range(len(neighbors)):
????clfs.append(KNeighborsClassifier(n_neighbors=neighbors[i]).fit(X,y))
#?可视化结果
x_min,?x_max?=?X[:,?0].min()?-?1,?X[:,?0].max()?+?1
y_min,?y_max?=?X[:,?1].min()?-?1,?X[:,?1].max()?+?1
xx,?yy?=?np.meshgrid(np.arange(x_min,?x_max,?0.1),
?????????????????????np.arange(y_min,?y_max,?0.1))
f,?axarr?=?plt.subplots(3,3,?sharex='col',?sharey='row',?figsize=(15,?12))
for?idx,?clf,?tt?in?zip(product([0,?1,?2],?[0,?1,?2]),
????????????????????????clfs,
????????????????????????['KNN?(k=%d)'%k?for?k?in?neighbors]):
????Z?=?clf.predict(np.c_[xx.ravel(),?yy.ravel()])
????Z?=?Z.reshape(xx.shape)
????axarr[idx[0],?idx[1]].contourf(xx,?yy,?Z,?alpha=0.4)
????axarr[idx[0],?idx[1]].scatter(X[:,?0],?X[:,?1],?c=y,
??????????????????????????????????s=20,?edgecolor='k')
????axarr[idx[0],?idx[1]].set_title(tt)
plt.show()
效果如图
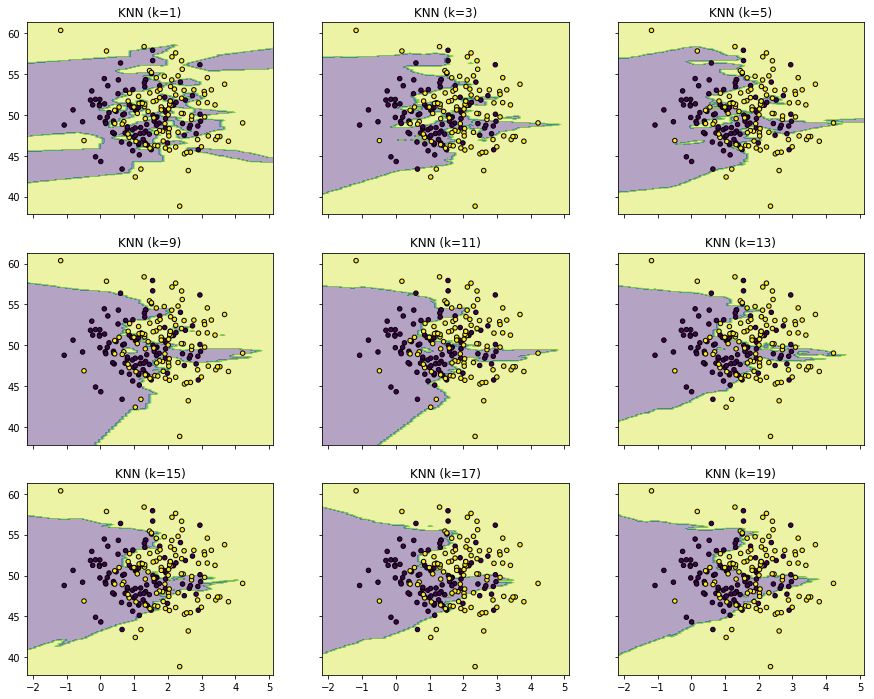

最后,祝有所学习,有所成长

转发,好看支持一下,感谢
你的转发,就是对我最大的支持
内容总结
以上是互联网集市为您收集整理的机器学习之kNN算法全部内容,希望文章能够帮你解决机器学习之kNN算法所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。