常见排序算法及其对应的时间复杂度和空间复杂度
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了常见排序算法及其对应的时间复杂度和空间复杂度,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5840字,纯文字阅读大概需要9分钟。
内容图文

排序算法经过长时间演变,大体可以分为两类:内排序和外排序。在排序过程中,全部记录存放在内存,则成为内排序;如果排序过程中需要使用外存,则称为外排序,本文讲的都属于内排序。
内排序有可以分为以下几类:
(1)插入排序:直接插入排序、二分法插入排序、希尔排序
(2)选择排序:直接选择排序、堆排序
(3)交换排序:冒泡排序、快速排序
(4)归并排序
(5)基数排序
| 排序方法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 | 复杂性 |
| 直接插入排序 | O(n2) | O(n2) | O(n) | O(1) | 稳定 | 简单 |
| 希尔排序 | O(nlog2n) | O(n2) | O(n) | O(1) | 不稳定 | 较复杂 |
| 直接选择排序 | O(n2) | O(n2) | O(n2) | O(1) | 不稳定 | 简单 |
| 堆排序 | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(1) | 不稳定 | 较复杂 |
| 冒泡排序 | O(n2) | O(n2) | O(n) | O(1) |
稳定 |
简单 |
| 快速排序 | O(nlog2n) | O(n2) | O(nlog2n) | O(nlog2n) | 不稳定 | 较复杂 |
| 归并排序 | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(n) |
稳定 |
较复杂 |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O(n+r) |
稳定 |
较复杂 |
一、插入排序
?思想:每步将一个待排序的记录,按其顺序码大小插入到前面已经排序的字序列的合适位置,直到全部插入排序完为止。
?关键问题:在前面已经排好序的序列中找到合适的插入位置。
?方法:
直接插入排序
- 插入排序的最好情况是数组已经有序,此时只需要进行n-1次比较,时间复杂度为O(n)
- 最坏情况是数组逆序排序,此时需要进行n(n-1)/2次比较以及n-1次赋值操作(插入)
- 平均来说插入排序算法的复杂度为O(n^2)
- 空间复杂度上,直接插入法是就地排序,空间复杂度为(O(1))
二分插入排序
- 最坏情况:每次都在有序序列的起始位置插入,则整个有序序列的元素需要后移,时间复杂度为O(n^2)
- 最好情况:待排序数组本身就是正序的,每个元素所在位置即为它的插入位置,此时时间复杂度仅为比较时的时间复杂度,为O(log2n)
- 平均情况:O(n^2)
- 空间复杂度上,二分插入也是就地排序,空间复杂度为(O(1))。
希尔排序
1.直接插入排序
(1)基本思想:每步将一个待排序的记录,按其顺序码大小插入到前面已经排序的字序列的合适位置(从后向前找到合适位置后),直到全部插入排序完为止。(是一种最简单的排序方法,其基本操作是将一条记录插入到已排好的有序表中,从而得到一个新的、记录数量增1的有序表。)
(2)实例
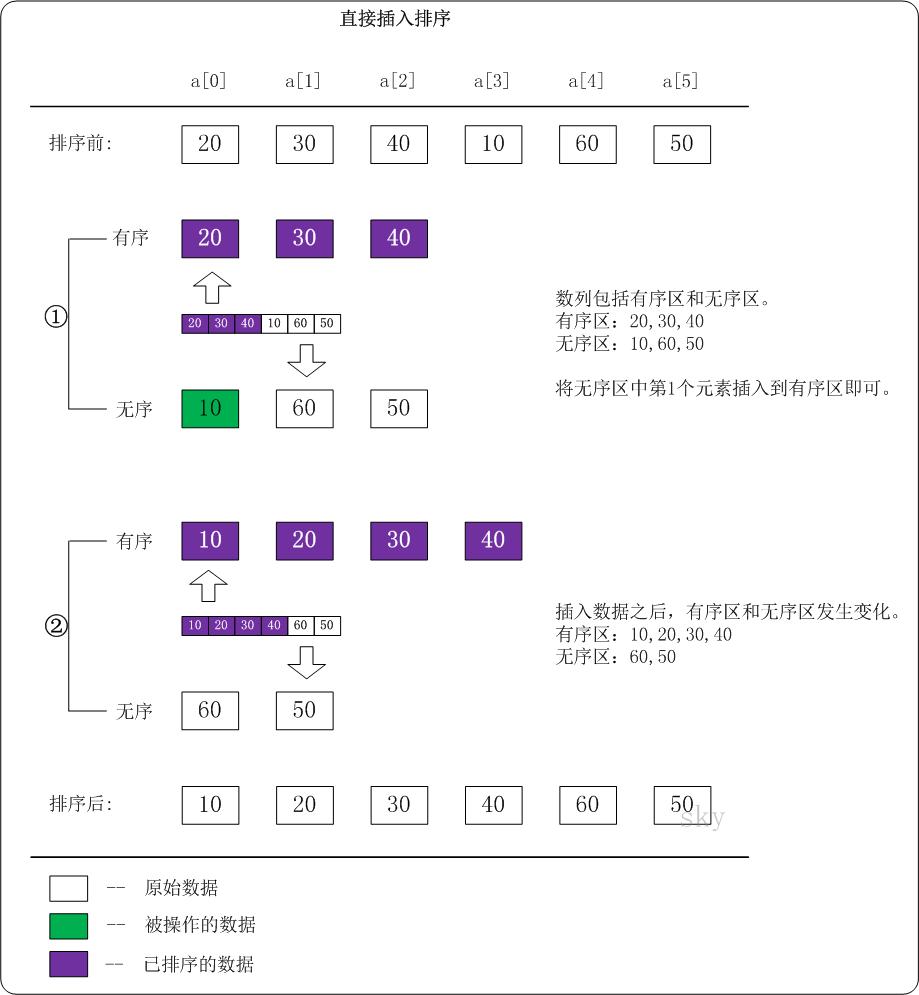
(3)python实现
def InsertSort(list_):
for i in range(1,len(list_)): #从列表的第二个元素开始找
j = i-1 #先定位第i个元素的前一个元素
if list_[j] > list_[i]: #如果前一个元素比第i个元素大
temp = list_[i] #前一个元素比i元素大,所以i元素需要往前插入,故先把list_[i]赋值给一个临时变量
list_[j+1] = list_[j] #i元素插入后,其前一个元素即j元素肯定向后位移一位
# 继续往前寻找,如果有比临时变量大的数字,则后移一位,直到找到比临时变量小的元素或者达到列表第一个元素
j -= 1
while j >= 0 and list_[j] > temp:
list_[j+1] = list_[j]
j -= 1
list_[j+1] = temp #只要找到比temp小的元素,就将temp插入到其后一位(原本其后面一位元素已经右移走掉了),
#或者i元素前面所有元素都比它大,则j循环到-1时,temp被赋值给了list_[0]即达到列表首位
return list_
2.二分插入排序
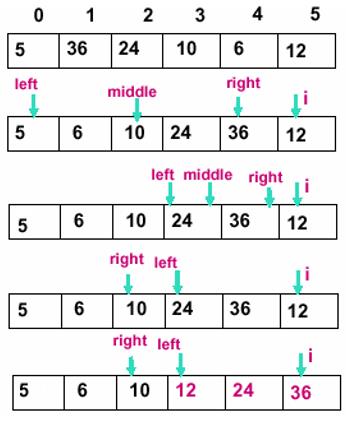
(1)基本思想:二分法插入排序的思想和直接插入一样,只是找合适的插入位置的方式不同,这里是按二分法找到合适的位置,可以减少比较的次数。
(2)实例
(3)python实现
二分排序算法只对于事先排好序的算法有效故在使用二分排序算法之前要对样本序列进行排序,具体可描述为以下步骤:
1.从第一个元素开始,该元素可以被认为已经被排序
2.取出下一个元素,在已经排序好的元素序列中(即该被取出元素之前的所有元素)二分查找到第一个比它小的元素的位置
3.将被取出元素插入到该元素的位置后
4.重复
3.希尔排序
(1)基本思想:希尔排序又叫“缩小增量排序”,先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序,然后取第二个增量d2。其是插入排序改良的算法,希尔排序步长从大到小调整,第一次循环后面元素逐个和前面元素按间隔步长进行比较并交换,直至步长为1,步长选择是关键。
(2)实例
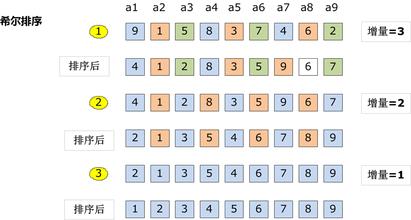
(3)python实现
二、选择排序
?思想:每趟从待排序的记录序列中选择关键字最小的记录放置到已排序表的最前位置,直到全部排完。
?关键问题:在剩余的待排序记录序列中找到最小关键码记录。
?方法:
直接选择排序
堆排序
1.直接选择排序
(1)基本思想:在要排序的一组数中,选出最小的一个数与第一个位置的数交换;然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环到倒数第二个数和最后一个数比较为止。
(2)实例
(3)python实现
2.堆排序
(1)基本思想:
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
堆的定义下:具有n个元素的序列 (h1,h2,…,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1) (i=1,2,…,n/2)时称之为堆。在这里只讨论满足前者条件的堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项(大顶堆)。完全二叉树可以很直观地表示堆的结构。堆顶为根,其它为左子树、右子树。
思想:初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储序,使之成为一个堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点的堆,并对它们作交换,最后得到有n个节点的有序序列。从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
(2)实例
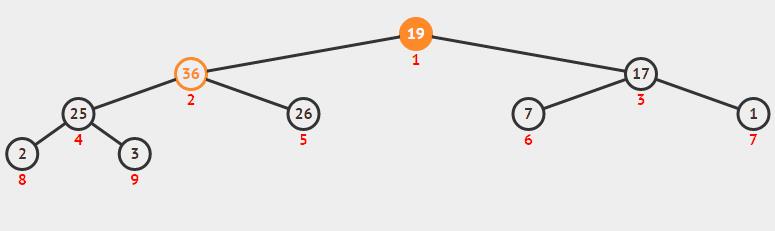

(3)python实现
三、交换排序
?思想:利用交换元素的位置进行排序,每次两两比较待排序的元素,直到全部排完。
?关键问题:排序时要厘清需要进行几轮排序。
?方法:
冒泡排序
快速排序
1.冒泡排序
(1)基本思想:在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。
(2)实例
(3)python实现
2.快速排序
(1)基本思想:选择一个基准元素,通常选择第一个元素或者最后一个元素,通过一趟扫描,将待排序列分成两部分,一部分比基准元素小,一部分大于等于基准元素,此时基准元素在其排好序后的正确位置,然后再用同样的方法递归地排序划分的两部分。
(2)实例

(3)python实现
四、归并排序
(1)基本思想:归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
(2)实例
(3)python实现
五、基数排序
(1)基本思想:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
(2)实例
(3)python实现
内容总结
以上是互联网集市为您收集整理的常见排序算法及其对应的时间复杂度和空间复杂度全部内容,希望文章能够帮你解决常见排序算法及其对应的时间复杂度和空间复杂度所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。