python 爬取36kr 7x24h快讯
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了python 爬取36kr 7x24h快讯,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3034字,纯文字阅读大概需要5分钟。
内容图文

url为https://36kr.com/newsflashes,抓包后发现第一次的新闻内容就是包含在<script>var props={}></script>标签中,具体的是在props中的key为newsflashList|newsflash的列表中紧着我又让页面多加载了一些,发现此时请求地址有了些变化,此时返回的内容是json字符串了
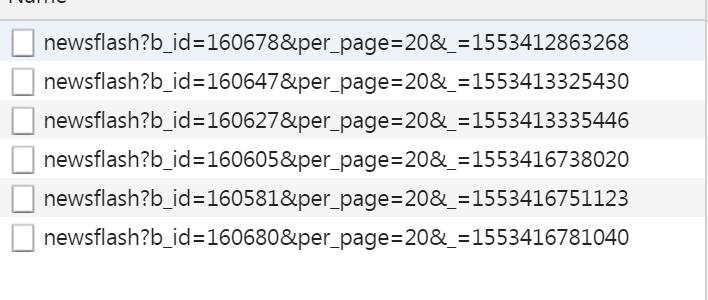
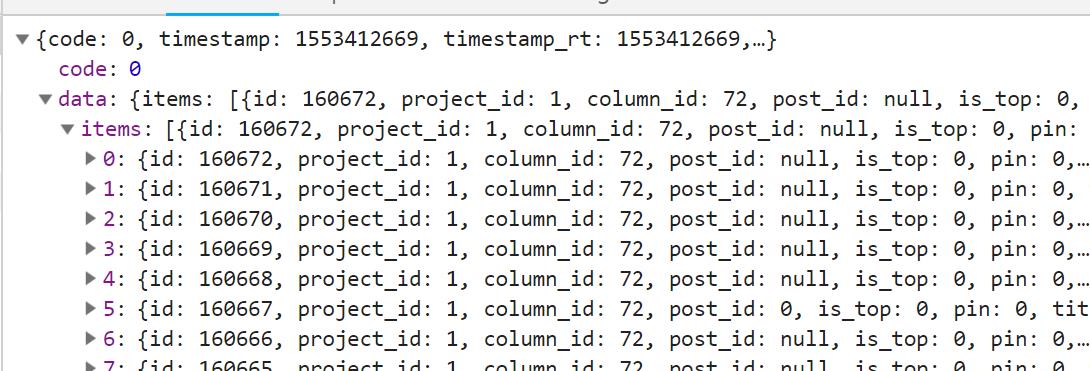
仔细研究下请求中的bid其实和返回的items中的最后一个id是相同的,这意味着我们可以第一次请求https://36kr.com/newsflashes,解析其中的props标签,然后获得最后一个id,接下来构造新的url时就可以采用形如https://36kr.com/api/newsflash?b_id=160678&per_page=20&_=1553412863268格式的地址了,测试发现只需要https://36kr.com/api/newsflash?b_id=160678&per_page=20就可以了,这个地址其实是多了层"api",测试时发现构造这种https://36kr.com/newsflashes?b_id=160680&per_page=20这个地址没有那层"api",所以返回的也是html,解析props标签同样可以获得数据
好了,综上我们有了两种思路,第一种是请求https://36kr.com/newsflashes,正则解析props.然后获得id,构造返回值为json字符串的url,第二种也是请求https://36kr.com/newsflashes,解析props.然后获得id,
构造返回html内容的url,之后也是使用正则解析props标签,但实际测试时这种效率有点低,因为大规模的使用了正则匹配,
所以我使用了第一种方式,此外使用第一种方式我们可以指定per_page,虽然过大容易被封IP
1 # -*- coding: utf-8 -*-
2 # @author: Tele
3 # @Time : 2019/3/24 0024 下午 12:56
4 import re
5 import json
6 import requests
7 import os
8 from pprint import pprint
9
10
11 class NewsFlashesSplider:
12 def __init__(self):
13 # "https://36kr.com/newsflashes?b_id={}&per_page=20"
14 self.url = "https://36kr.com/newsflashes"
15 self.headers = {
16 "User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
17 }
18 self.file_dir = "./newsflashes.txt"
19
20 def parse_url(self):
21 response = requests.get(self.url, headers=self.headers)
22 ret = json.loads(response.content.decode())["data"]["items"]
23
24 print(ret)
25
26 size = len(ret)
27 last_id = int(ret[size - 1]["id"])
28 with open(self.file_dir, "a", encoding="utf-8") as file:
29 file.write(json.dumps(ret, ensure_ascii=False))
30 file.write("\r\n")
31 return size, last_id
32
33 def run(self):
34 if os.path.exists(self.file_dir):
35 os.remove(self.file_dir)
36 print("文件已清空")
37
38 # 第一次请求获得当前最新的新闻
39 response = requests.get(self.url, headers=self.headers)
40 result = re.compile("<script>var props=(.*),locationnal=").findall(response.content.decode())
41 ret = json.loads(result[0])["newsflashList|newsflash"]
42
43 # 新闻个数,最后一个id
44 tuple_result = len(ret), int(ret[len(ret) - 1]["id"])
45
46 while True:
47 self.url = "https://36kr.com/api/newsflash?b_id={}&per_page=20".format(tuple_result[1])
48 tuple_result = self.parse_url()
49 if tuple_result[0] < 20:
50 break
51
52
53 def main():
54 splider = NewsFlashesSplider()
55 splider.run()
56
57
58 if __name__ == '__main__':
59 main()
内容总结
以上是互联网集市为您收集整理的python 爬取36kr 7x24h快讯全部内容,希望文章能够帮你解决python 爬取36kr 7x24h快讯所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。