首页 / PYTHON / 用python爬取猫眼电影排行
用python爬取猫眼电影排行
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了用python爬取猫眼电影排行,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3123字,纯文字阅读大概需要5分钟。
内容图文

利用requests库和正则表达式来爬取猫眼电影TOP100的相关内容
网页分析
首先进入猫眼电影TOP100榜单页面,网址:https://maoyan.com/board/4
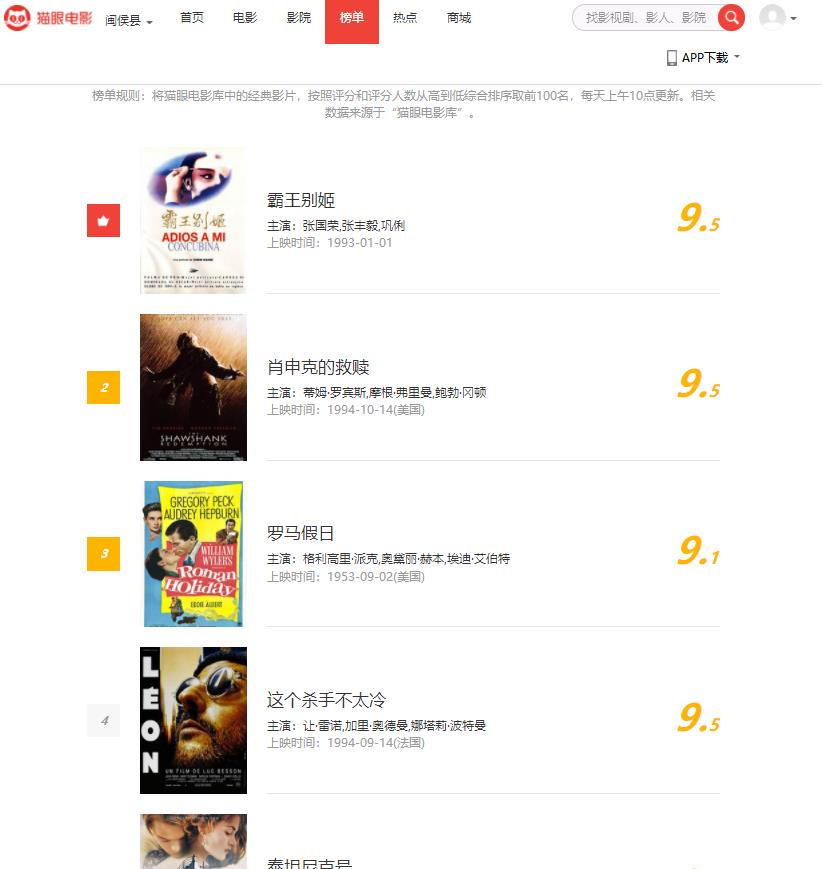
滑动到页面底部,发现有多个页面选择,进入第二个页面后观察网址变化,https://maoyan.com/board/4?offset=10,发现网址后多了一个参数offset=10,继续进入后边的页面,发现每进一页offset的值增加10.这个10代表每页有十部电影。由此我们可以知道,爬取这个TOP100榜单 一共需要爬取10个页面,需要分开请求10次,页面网址中offset的值从0变化到90。所以我们可以设计一个循环爬取的程序,设置offset为变量,即可依次爬取10个页面得到TOP100电影的信息。
爬取网页
首先爬取第一页的内容(后边每一页与第一页爬取方法相同),利用requests库实现页面的爬取。具体代码如下:
def getPage(url):
try:
headers = {'User-Agent': 'Mozilla/5.0'}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取失败"
运行结果如下:
解析页面
获取到的页面信息看起来十分冗杂,电影的各项信息都隐藏在一个个html标签的包裹之下,接下来我们要做的就是从这些复杂的页面信息中提取我们需要的电影信息。页面信息提取有多种方法,可以选择BeautifulSoup,pyquery,正则表达式等等,这里我们选择正则表达式来进行解析。
再次进入榜单页面,用浏览器自带的审查元素,随意点击一部电影,可以看到下图的场景:
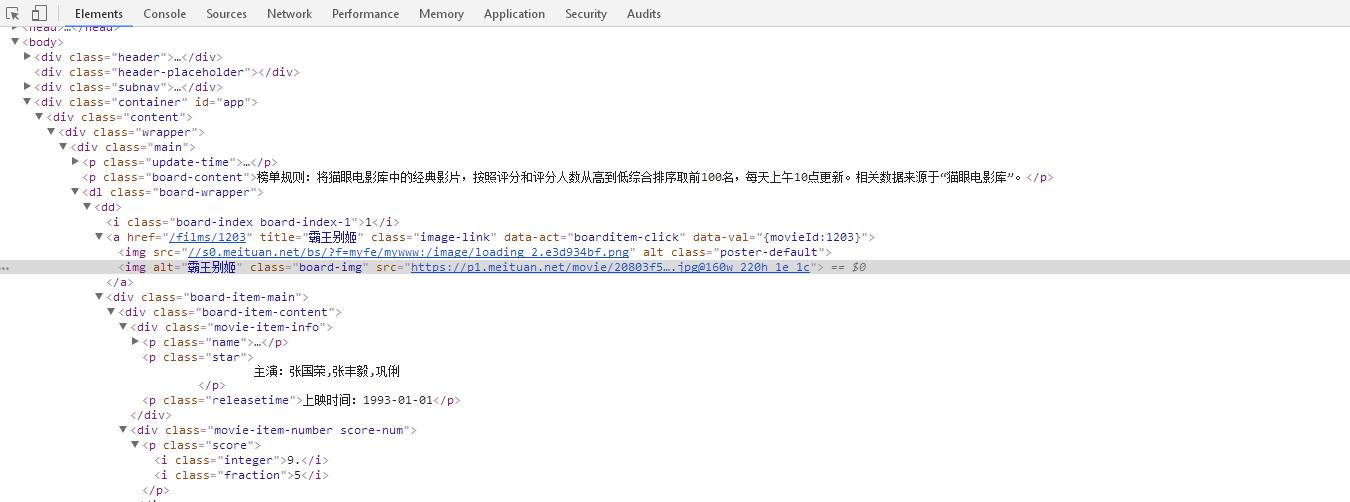
观察发现,每部电影的基本信息包括:排名,电影名称,主演,上映时间,得分,他们分别包含在不同的标签下。审查其余电影可以发现,每一部电影的基本信息都包含在相同名称的标签下,这对我们使用正则表达式的提取提供了很大的方便。下边我们来进行元素提取。
电影序号:class="board-index board-index-1" ;正则表达式:<dd>.*?board-index.*?>(.*?)</i>
电影名称:href="/films/1203" title="霸王别姬" ;正则表达式:.*?title="(.*?)
主演:<p class="star">主演:张国荣,张丰毅,巩俐</p> ;正则表达式:"star">(.*?)</p>
上映时间:<p class="releasetime">上映时间:1993-01-01</p> ;正则表达式:"releasetime">(.*?)</p>
代码实现如下:
def parse_one_page(html):
pattern=re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?"star">(.*?)</p>.*?"releasetime">(.*?)</p>.*?',re.S)
items=re.findall(pattern,html)
for item in items:
print(item)
运行结果如下:

分页爬取
为了爬取所有信息,我们需要遍历十次页面爬取。由前文分析可知,每个页面网址基本相同,只用最后的offset参数值不相同,所有我们设计函数,将offset作为参数传进去。实现代码如下:
def main(offset):
url="https://maoyan.com/board/4?offset="+str(offset)
html=getPage(url)
parse_one_page(html)
if __name__=='__main__':
for i in range(10):
main(offset=i*10)
time.sleep(1)
运行结果如下:

完整代码
import requests
import re
import time
def getPage(url):
try:
headers = {'User-Agent': 'Mozilla/5.0'}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取失败"
def parse_one_page(html):
pattern=re.compile('<dd>.*?board-index.*?>(.*?)</i>.*?title="(.*?)".*?"star">(.*?)</p>.*?"releasetime">(.*?)</p>.*?',re.S)
items=re.findall(pattern,html)
for item in items:
print(item)
#print('\n')
def main(offset):
url="https://maoyan.com/board/4?offset="+str(offset)
html=getPage(url)
parse_one_page(html)
if __name__=='__main__':
for i in range(10):
main(offset=i*10)
time.sleep(1)
参考书目《Python3网络爬虫开发实践》崔庆才
内容总结
以上是互联网集市为您收集整理的用python爬取猫眼电影排行全部内容,希望文章能够帮你解决用python爬取猫眼电影排行所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。