由于CentOS6.5系统自带的python版本为2.6.6,而很多情况下我们要求使用的python版本为2.7.*,手动升级python版本至2.7.13,安装完毕后,发现使用系统自带的python 2.6.6版本时,箭头和退格正常使用,但自定义安装的python 2.7.13退格键和箭头无法正常使用,如下:[root@M1 ~]# pythonPython 2.7.13 (default, Feb 26 2017, 22:50:38) [GCC 4.4.7 20120313 (Red Hat 4.4.7-3)] on linux2Type "help", "copyright", "credits" or "l...
#encoding:utf-8
#用命令行执行
s = ‘百度‘
print s # 输出环境为gbk,编码为utf-8,输出乱码
print s.decode(‘utf-8‘) # => 发现输出环境为gbk,自动转换
print s.decode(‘utf-8‘).encode(‘utf-8‘) # 输出环境为gbk,编码为utf-8,输出乱码
print s.decode(‘utf-8‘).encode(‘gbk‘) # 输出环境为gbk,编码为gbk,正常输出
# s = 0xF21938274ABDS... 二进制内存
# 把这些内存数据转化为可显示的字符串就是repr(s)的prin...
Windows,Python2环境下,当gVim配置了 set fileencoding=utf-8,则新建文件编码方式为utf-8。 ○ 如果代码不包含中文,或者仅包含中文注释,则utf-8编码方式可以用。只要在文件头加上 # -*- coding:utf-8 -*- 即可。可以在gVim中使用命令 :set fileencoding来查看文档编码方式,如果不是utf-8,则可以使用命令 :set fileencoding=utf-8来设置。 ○ 如果代码正文包含中文,则utf-8编码方式不可用,因为Windows默认的中文编码方...
系统是Windows7.在cmd或者powershell上使用Python2/3运行含有中文的Python源文件,都有中文乱码问题。目前找到的有效解决方法是先对中文按照指导的编码方式解码,然后按照指定的编码方式编码字符串,当然对于Python2要加上使用utf-8的注解,例如:(该解决方案来自于http://www.runoob.com/python/python-chinese-encoding.html 的笔记)#!/usr/bin/python# -*- coding:utf-8 -*-s = "你好,世界!"print s.decode("utf-8").encode...
最近忙完了一个比较大的 GIS 软件系统,于是闲暇之余想研究一下开源的技术,纵观当前开源桌面 GIS 软件领域,最牛叉的莫过于大名鼎鼎的 Quantum GIS,简称 QGIS。做过 GIS 的人都知道,ESRI ArcGIS 是 GIS 软件领域迄今为止世界上最牛叉的一个,但由于是商业软件,故而其价格普通大众望而却步。于是,寻找一款开源免费的且功能又能与之睥睨的GIS软件就在所难免了。本人经过大量比较得出,QGIS 当之无愧!可是对于我来说,由于我是搞...
前提:自己安装了code runner的插件快捷键Ctrl+Shift+P,打开设置Open Settings (JSON):原文:https://www.cnblogs.com/alice-cj/p/12036284.html
python+mongodb 在爬虫的过程中,抓到一个中文字段,encode和decode都无法正确显示注:以下print均是在mongodb中截图显示的,在pythonshell中可能会有所不同比如中文 “余年”,假设其为变量a1. print a 结果如下: 使用type查询之后,显示的确是unicode编码(正常情况下讲unicode编码内容直接存入mongodb中是可以正常显示的)2. print type(a) 结果如下:3. print a.encode(‘utf-8‘) 结果如下:然后查看a的unicode编码,是这种格...
1、pycharm控制台输出乱码如果cmd.exe输出是正常的,解决方案:设置pycharm 2、cmd.exe控制台输出乱码原文:https://www.cnblogs.com/andy9468/p/12766382.html
输出爬去的信息为乱码!解决办法
爬取下来的编码是ISO-8859-1格式,需要转化为utf-8格式,加一句response.encoding = "utf8"原文:https://www.cnblogs.com/amojury/p/9127570.html
son.dumps在默认情况下,对于非ascii字符生成的是相对应的字符编码,而非原始字符,例如:>>> import json>>> js = json.loads(‘{"haha": "哈哈"}‘)>>> print json.dumps(js){"name": "\u54c8\u54c8"}解决办法很简单:>>> print json.dumps(js, ensure_ascii=False) {"name": "哈哈"} 原文:https://www.cnblogs.com/robinunix/p/12896742.html
python cmd 窗口 中文乱码 解决方法前言在 python 开发中,有时候想通过cmd窗口来和用户交互,比如显示信息之类的,会比自己创建 GUI 来的方便,但是随之而来的就是编码乱码问题下面例子在 python2 和 python3 中都可以运行,也可以在其它 .py 中通过 import os;os.startfile(ur"xxx.bat") 来运行之前一直遇到一个问题,通过双击 bat 文件来运行,可以不用转码,只要 cmd 窗口的活动页编码是 936 就可以了,但是在其它 py 文件中运...
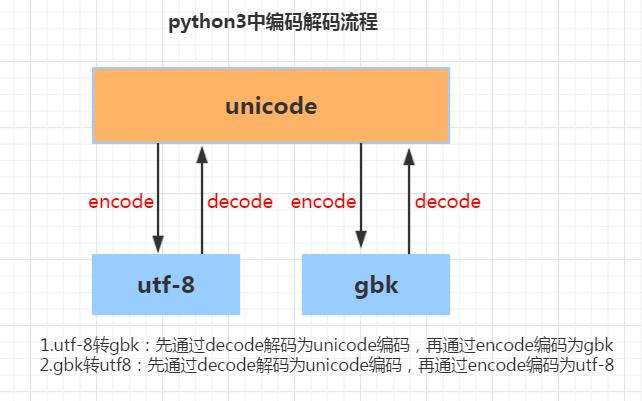
为什么会报错“UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 0-1: ordinal not in range(128)”?本文就来研究一下这个问题。字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。 decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312‘...
解决python写入中文乱码问题:添加encoding=‘utf-8-sig‘with open(‘result.csv‘, ‘w‘, encoding=‘utf-8-sig‘, newline=‘‘) as f:writer = csv.writer(f)writer.writerows(data)
原文:https://www.cnblogs.com/zongdeiqianxing/p/13617078.html
关于python连接sqlserver后获取的数据输出结果为乱码的解决方法之一方法来源:https://blog.csdn.net/cddchina/article/details/50731491
作者为后来防止犯错写下方便自己日后查看的小随笔
将字符串转换为nvarchar类型即可原文:https://www.cnblogs.com/tangji/p/14651445.html
之前用的黑莓手机,故障后换了iphone,后来还是想用上黑莓Q10。于是有了该文章。
问题:
如何将iphone上的通讯录导入黑莓?网上回答1:通过icloud将iphone中的通讯录导入黑莓手机。
结果:在黑莓Q10上登录icloud的服务器contacts.icloud.com时,报错。。。无果。网上回答2:通过qq或者微信同步助手。
结果:在iphone上没装这些软件,而且要做Q10上安装响应的软件才能同步。。。无果。网上回答3:将iphone上的通讯录存到sim卡中。
结...