POJ1811给一个大数,判断是否是素数,如果不是素数,打印出它的最小质因数随机素数测试(Miller_Rabin算法)求整数素因子(Pollard_rho算法)科技题 1 #include<cstdlib>2 #include<cstdio>3constint maxn=10005;4constint S=20;5int tot;6longlong n;7longlong factor[maxn]; 8longlong muti_mod(longlong a,longlong b,longlong c)9{10//(a*b) mod c a,b,c<2^63 11 a%=c;12 b%=c;13longlong ret=0;14while(b)15 {16i...
今天上班的时候网上看到题目很简单,题目是这样的:给定一个正整数n,需要输出一个长度为n的数组,数组元素是随机数,范围为0 – n-1,且元素不能重复。比如 n = 3 时,需要获取一个长度为3的数组,元素范围为0-2;简单的理解就是生成一个无序的随机数组,在路上想了一下回来用三种方式方式实现了一下;OC实现了一下,文章最末尾顺便有C#的是实现方法;永远的Whilewhile基本上学过语言的最开始的流程分支语句都会涉及到while,如果...
场上数据很水,比较暴力的做法都可以过90分以上,下面说几个做法。1. 暴力枚举所有最大独立集,对每个独立集分别DP。复杂度玄学,但是由于最大独立集并不多,所以可以拿90.2. dp[S][k]表示考虑到排列的第k位,当前独立集为S的方案数,枚举第k+1位,根据是否与S相连转移到dp[S][k+1]或dp[S | a[k+1]][k+1]。$O(n^22^n)$3. dp[S]表示排列的状态为S时的正确率,mx[S]表示排列状态为S时能得到的最大独立集大小,考虑转移,枚举排列里最...
45%的概率友好致敬25%的概率转身离开20%的概率攻击10%的概率送礼int choose(){float[] propArray = {45%,25%,20%,10%}float total = 0.0f;for(int i = 0 ; i < propArray.length;i++){total += propArray[i];}float propValue = Random.value*total;for(int i = 0 ; i< propArray.length; i++){if(propValue < propArray[i]){ return i;}else{ propValue -= propArray[i];}}return propArray.length - 1;}原文:http://56846...
随机数,也就是在不同的时刻产生不同的数值。在UNIX操作系统和window的操作系统上,我们知道有一个函数rand,它就是用来产生随机数的函数API接口,那么它的原理如何实现?如果约定a1=f(seed),an+1=f(an),那么可以得到一个序列a1,a2,a3..an,那么要制作一个伪随机函数rand,只需要让它每调用一次就返回序列的下一个元素就行。其实就是相当于第1次调用rand返回a1,第2次返回a2,…,第n次返回an,这样每次返回的数值都不一样,也就是...
抽奖算法 参考Return random `list` item by its `weight`原文:http://www.cnblogs.com/HQFZ/p/5945219.html
看到\(n\leq 20\),马上想到状压\(dp\).
考虑用\(f[S][i]\)表示集合\(S\)已经被考虑过了,独立集大小为\(i\)的方案数.
显然,这个集合\(S\)的最外层显然都没有被选.
考虑如何转移.
枚举一个\(j\notin S\),那么独立集大小显然\(+1\),然后所有和\(j\)相连的点都不能选了.
那么用\(w[j]\)记录与\(j\)相邻的集合,然后就可以转移了.\(f[S\cup j][i+1]\leftarrow f[S\cup j][i+1]+f[S][i]*A_{n-|S|-1}^{|w[j]|-|w[j]\cap S|-1}\)
时间复杂度...
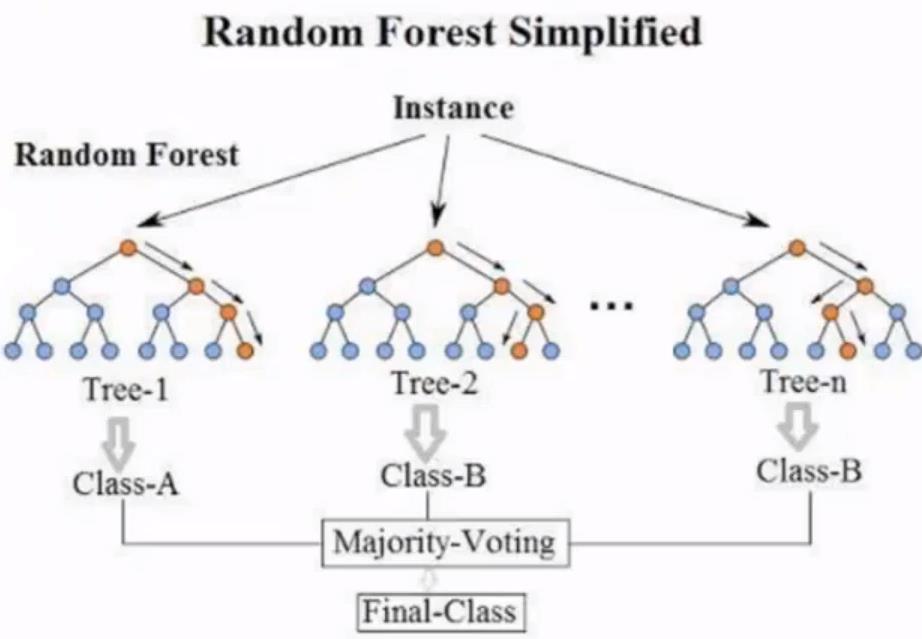
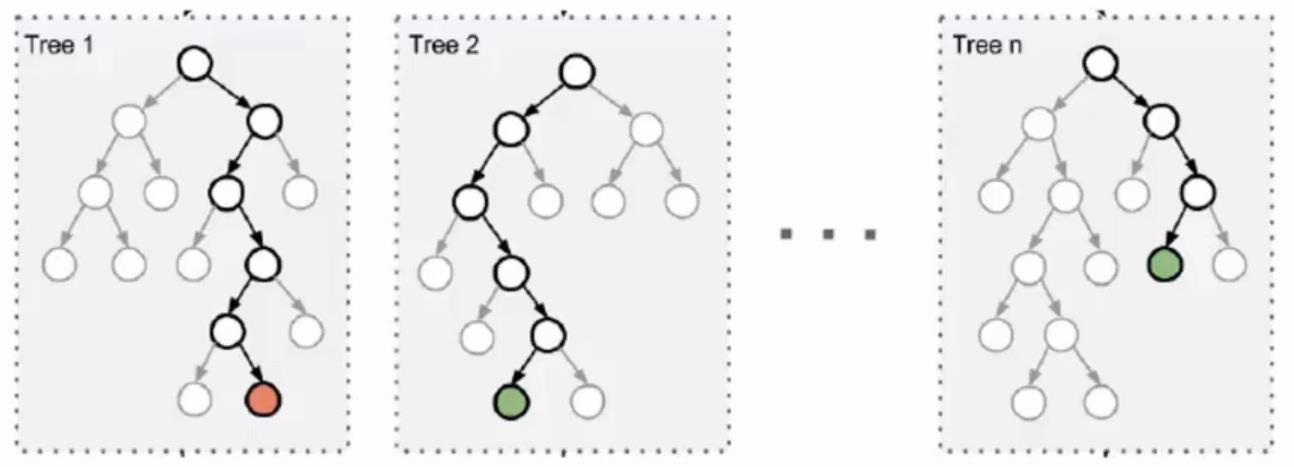
在随机森林中的随机性体现在:1.训练数据的随机性 2. 选择分割属性的随机性能解决分类与回归问题,并且都有很好的估计表现1.生成数据说明文件mahout describe -p input.csv -f input.info-d2 I 3 N I 5 N I 3 C L(执行describe生成数据的说明文件)2.训练模型mahout buildforest -d input.csv -ds input.info -sl 5 -p -t 5 -o forest_result(生成随机森林模型结果)3.测试Mahout testforest -i input.csv -ds input.info -m fore...
今天学习了一下随机函数rand的算法。这个算法叫做线性同余算法(linear congruential generator (LCG))。不同的编译器取的常数不同,可以参考wiki:http://en.wikipedia.org/wiki/Linear_congruential_generator以下程序可以输出和系统一样的随机数。 1 #include <stdio.h>2 #include <stdlib.h>3 4 5#define _A 214013LL6#define _B 2531011LL7 8 9int a;
101112void mysrand(int x)
13{
14 a = x;
15}
161718int myrand()
19{...
1package com.zuidaima.core.util;2 3import java.util.Random;4 5publicclass RandomUtil {6publicstaticfinal String ALLCHAR = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";7publicstaticfinal String LETTERCHAR = "abcdefghijkllmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ";8publicstaticfinal String NUMBERCHAR = "0123456789";9 10/** 11 * 返回一个定长的随机字符串(只包含大小写字母、数字...
Random转载内容,有更改,感谢原作者()Java中的Random类生成的是伪随机数,使用的是48-bit的种子,然后调用一个linear congruential formula线性同余方程(Donald Knuth的编程艺术的3.2.1节)如果两个Random实例使用相同的种子,并且调用同样的函数,那么生成的sequence是相同的也可以调用Math.random()生成随机数Random实例是线程安全的,但是并发使用Random实例会影响效率,可以考虑使用ThreadLocalRandom变量。Random实例不是...
func (this *LoadBalance) SelectByWeightBetter(ip string) *HttpServer {rand.Seed(time.Now().UnixNano())sumList := make([]int, len(this.Servers)) //this.servers是服务器列表sum := 0for i := 0; i < len(this.Servers); i++ {sum += this.Servers[i].Weight //如果是5,7,9权重之和为5 12 21,分三个区间[0:5) [5:12) [12,21) 0-20的随机数落在哪个区间就代表当前随机是哪个权重sumList[i] = sum //生成权重区间列表}_...
* 红包算法,给定一个红包总金额和分红包的人数,输出每个人随机抢到的红包数量。* 要求:* 每个人都要抢到红包,并且金额随机* 每个人抢到的金额数不小于1* 每个人抢到的金额数不超过总金额的30%* 例如总金额100,人数10,输出【19 20 15 1 25 14 2 2 1 1】//最少分得红包数privatestaticfinaldouble min = 1;//最多分得红包数占比privatestaticfinaldouble percentMax = 0.3;publicvoid allocateMoney(double money, int peopleN...
staticvoid Test7(){var strs = new List<string>{"192.168.100.125","192.168.100.126","192.168.100.127","192.168.100.128","192.168.100.130","192.168.100.131"};var d = GetRandom(strs);}publicstatic T GetRandom<T>(List<T> list){System.Random ran = new System.Random(GetRandomSeed());var t = ran.Next(0, list.Count);return list[t];} 原文:https://www.cnblogs.com/liuxiaoji/p/10319781.html
权重下随机,就是给定各个值不同的权重,再根据权重的比例随机选出一个值 1/** 2 * Created by Jungle on 2020/2/23.3 *4 * @author JungleZhang5 * @version 1.0.06 * @Description 权重下随机的算法7*/ 8publicclass WeightRandom<K, V extends Number> {9private TreeMap<Double, K> weightMap = new TreeMap<>();
1011public WeightRandom(@NotNull List<Pair<K, V>> list) {
12// 先排除权重为0的项13 Iterator<Pair<...
【知识整理】")