Python Web从入门到精通(一) Scrapy框架爬取天气网并将数据存入数据库
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python Web从入门到精通(一) Scrapy框架爬取天气网并将数据存入数据库,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3511字,纯文字阅读大概需要6分钟。
内容图文
 Scrapy框架爬取天气网并将数据存入数据库")
-
创建项目
scrapy startproject 项目名 -
个人习惯使用vscode进行编码,相较于pycharm而言,vscode属于轻量级编译器,打开终端,输入以下命令
1. scrapy genspider spider名 爬取的网站 2. 例如:scrapy genspider weather https://www.tianqi.com/fuan/ -
此时会在项目的spider文件夹下生成weather.py.
-
由于爬取的天气网站https://www.tianqi.com/fuan/右键无法查看网页源代码,我自己就先ctrl+s将html页面保存到桌面端,然后再打开,此时便可以右键查看到网页源代码.
-
以上工作都做完后,我们便可以开始编写核心代码了.
-
首先书写items.py, 定义我们需要封装的字段名字
class FuanweatherItem(scrapy.Item): city = scrapy.Field() # 城市 date = scrapy.Field() # 日期 week = scrapy.Field() # 星期几 Weather = scrapy.Field() # 天气 minTempeture = scrapy.Field() # 最低温度 maxTempeture = scrapy.Field() # 最高温度 wind = scrapy.Field() # 风向 -
编写weather.py,目的是从相应网站抓取数据,并保存入item中
import scrapy from fuanWeather.items import FuanweatherItem class WeatherSpider(scrapy.Spider): name = 'weather' allowed_domains = ['tianqi.com'] start_urls = ['https://www.tianqi.com/fuan/'] def parse(self, response): items = [] # 获取到7天内福安天气所要信息,分别存入每一个数组中 citys = response.xpath('//dd[@class="name"]/h2/text()').extract() container = response.xpath('//div[@class="day7"]') dates = container.xpath('ul[@class="week"]/li/b/text()').extract() weeks = container.xpath('ul[@class="week"]/li/span/text()').extract() weathers = container.xpath('ul[@class="txt txt2"]/li/text()').extract() minTempetures = container.xpath('div[@class="zxt_shuju"]/ul/li/b/text()').extract() maxTempetures = container.xpath('div[@class="zxt_shuju"]/ul/li/span/text()').extract() winds = container.xpath('ul[@class="txt"]/li/text()').extract() # for循环加入items for t in range(7): try: item = FuanweatherItem() item['city'] = citys[0] item['date'] = dates[t] item['week'] = weeks[t] item['Weather'] = weathers[t] item['minTempeture'] = minTempetures[t] item['maxTempeture'] = maxTempetures[t] item['wind'] = winds[t] items.append(item) except IndexError as e: exit() return items -
接下来我们编写pipelines.py文件,目的是处理已经存好的数据,并将其存入数据库中
from itemadapter import ItemAdapter import pymysql class FuanweatherPipeline: def process_item(self, item, spider): city = item['city'] date = item['date'] week = item['week'] Weather = item['Weather'] minTempeture = item['minTempeture'] maxTempeture = item['maxTempeture'] wind = item['wind'] # 连接本地数据库 connection = pymysql.connect( host='localhost', user='root', passwd='123', db='scrapy', charset='utf8mb4', cursorclass=pymysql.cursors.DictCursor ) # 插库 try: with connection.cursor() as cursor: # 创建更新数据库的sql sql = """INSERT INTO WEATHER(city,date,week,Weather,minTempeture,maxTempeture,wind) VALUES (%s, %s, %s, %s, %s, %s, %s)""" # 执行sql cursor.execute(sql, (city, date, week, Weather, minTempeture, maxTempeture, wind)) # 提交插入数据 connection.commit() finally: connection.close() return item -
在setting中配置pipelines:
ITEM_PIPELINES = { 'fuanWeather.pipelines.FuanweatherPipeline': 300 } -
执行项目
scrapy crawl weather -
执行完项目后,查看数据库表格信息,如下图所示:
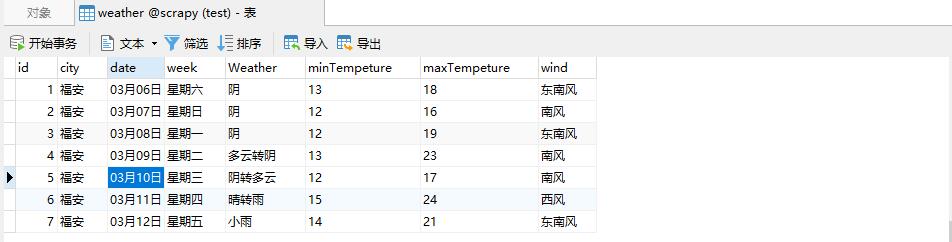
-
爬取天气网站过程中所可能遇到的问题
(1) 爬取过程中报如下403错误:
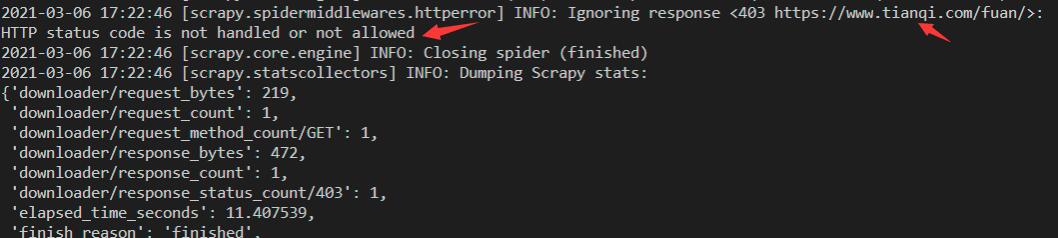
解决办法:在setting中配置:# settings.py 文件 # Chrome版 USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36" # Firefox版 USER_AGENT = "Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/21.0.1"(2) 数据存入mysql中,中文转变为unicode.
解决方法:在setting.py中配置:FEED_EXPORT_ENCODING = 'utf-8'欢迎大家留言评论
内容总结
以上是互联网集市为您收集整理的Python Web从入门到精通(一) Scrapy框架爬取天气网并将数据存入数据库全部内容,希望文章能够帮你解决Python Web从入门到精通(一) Scrapy框架爬取天气网并将数据存入数据库所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。