Python——Django框架(三)配置数据库,ORM对单表的增删改查,ORM查询API,模糊查询(单表)之双下划线
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python——Django框架(三)配置数据库,ORM对单表的增删改查,ORM查询API,模糊查询(单表)之双下划线,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含6795字,纯文字阅读大概需要10分钟。
内容图文
配置数据库,ORM对单表的增删改查,ORM查询API,模糊查询(单表)之双下划线")
Python——Django框架(三)
参考博文:https://www.cnblogs.com/yuanchenqi/articles/6083427.html
注意:从这里开始博主pycharm从社区版换成了专业版,需要的朋友自行去百度安装专业破解版。
一、Model(数据库模型)——ORM——通过python的类来操纵数据库
ORM——Object Relational Mapping,翻译过来就是对象关系映射表
表与表之间的关系(两张表)
一对多(用的最多,比如一个部门可以对应多个员工,就是一对多 )。
多对多(比如一本书可以有多个作者共同编写,一个作者写多本书,就是多对多。但是没有多对多的函数,一般是通过一对多实现多对多;此时两张表已经不够用了,需要一个中间表,也就是第三张表来实现)。
一对一(个人身份,一个身份id对应一个人)。
1、默认数据库
django默认支持sqlite,mysql, oracle,postgresql数据库。(这里只用mysql当例子)
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
mysql驱动程序:
(1)MySQLdb(mysql python,python3不用db了,python2才用)
(2)mysqlclient
(3)PyMySQL(纯python的mysql驱动程序)
一个新的表就是一个新的对象,一个实例就是一条记录,

2、在pycharm里配置数据库
在setting.py里配置数据库:
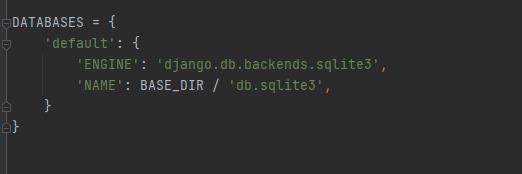
可以看到这里默认是sqlite,如果我们创建表,默认就是用sqlite,
创建表是在model.py里面创建。
首先,我们创建表必须继承一个类:
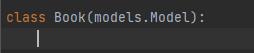
接着我们继续创建字段:
 简单的创建好后,需要在控制台输入命令语句生成通过数据库生成一个表(以后第一步都是这个,之后才是启动Django),这里用的是sqlite数据库举例子:
简单的创建好后,需要在控制台输入命令语句生成通过数据库生成一个表(以后第一步都是这个,之后才是启动Django),这里用的是sqlite数据库举例子:

成功:
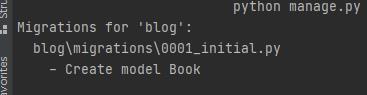
之后可以发现,多了些东西:
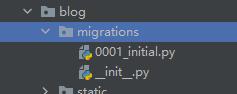
默认帮你加了东西:
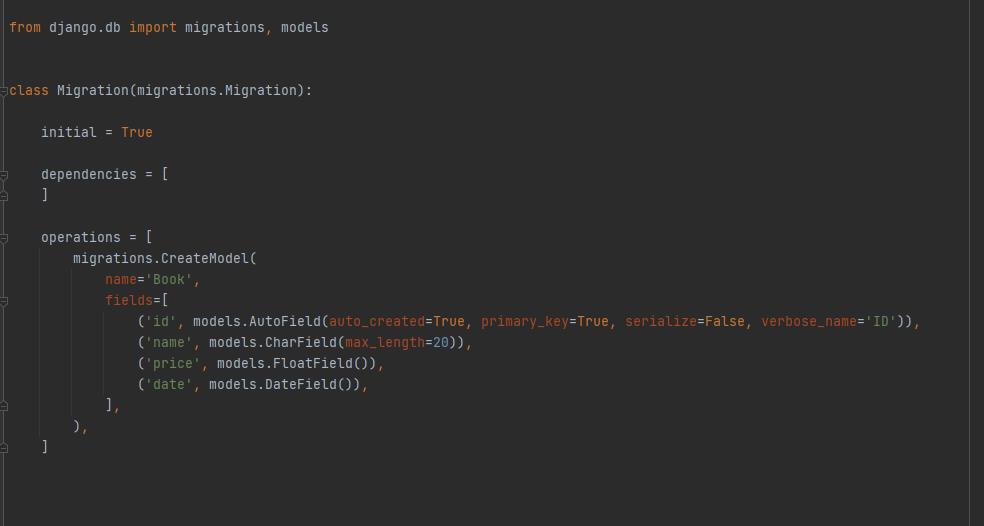 id是自动加的,如果你没有设置主键,会自动帮你加 id 并设置主键。
id是自动加的,如果你没有设置主键,会自动帮你加 id 并设置主键。
但是到这里并没有完成,还要再输入个命令行代码:

成功:
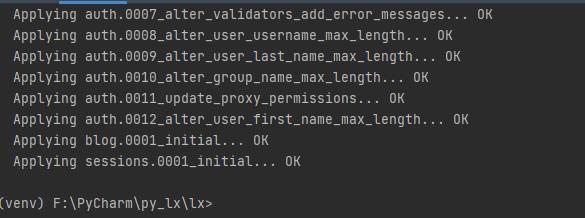
这里会默认帮你创建了很多张表。
接着就是安装及打开数据库sqlite(再次提醒,我用的是专业版,pycharm右边这里会有个database,社区版听说可以安装,但我懒得搞了,直接安装专业版一步到位):
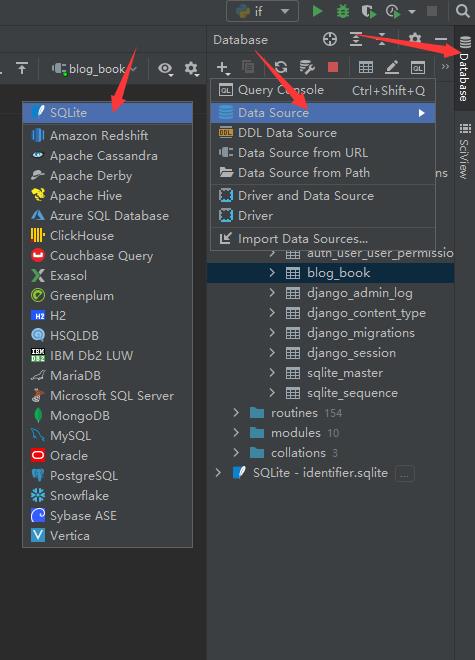
第一次安装的朋友,sqlite会在下面(mysql同理),点击之后:
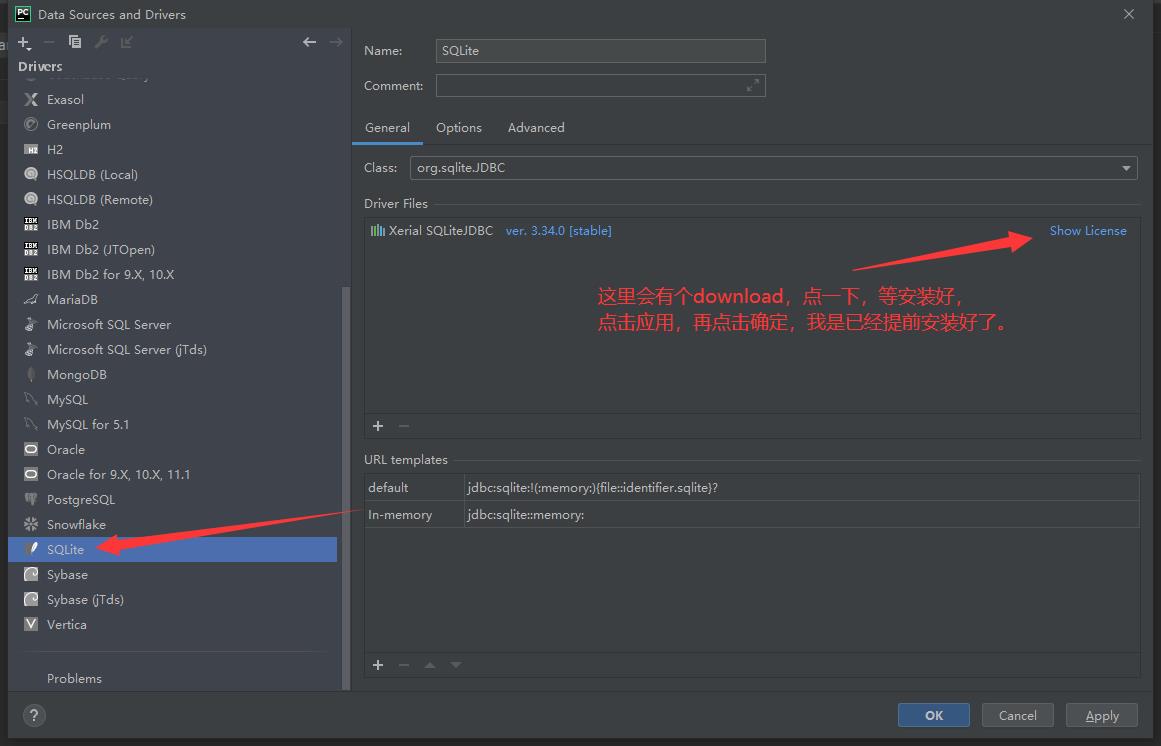
然后把左边的sqlite拖到右边这里:
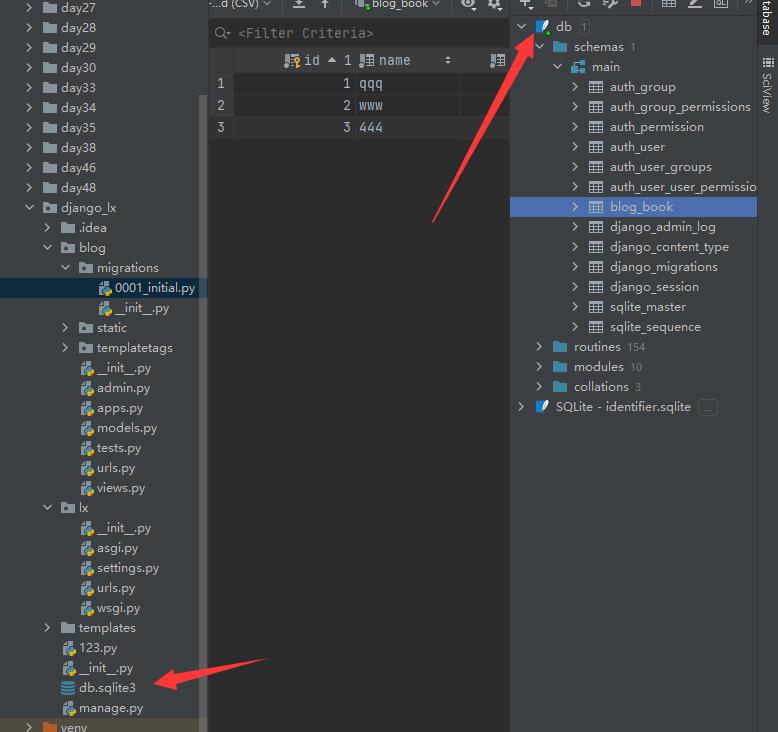
可以看到有很多个表,这里默认是项目名+表名:
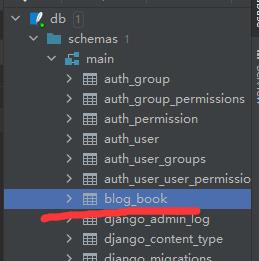
接着双击就可以来到这个页面:

这个页面就是方便操作数据库的页面,直接图形化操作,不用打命令行这么麻烦。从左到右依次为:刷新,增加记录,删减记录,以及提交。特别注意:如果操作完数据库,要点击提交!
由于最终要用的是mysql,所以这里换成mysql,需要在database里修改:

注意:mysql创建需要数据库名称,注意自己是否已经有数据库
这里我们创建一个数据库名为 orm
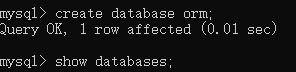
这里搞好之后,步骤跟前面基本一致。
在pycharm里面的database有个测试按钮,可以测试链接是否有问题。
说下链接mysql博主遇到的问题:
时区问题:
参考博文:https://www.cnblogs.com/fengxiaoqi/p/12897982.html
在mysql里面
设置全局时区 mysql> set global time_zone = '+8:00';
刷新权限使设置立即生效 mysql> flush privileges;
这样基本没有问题了。
能看到这里就是成功了:
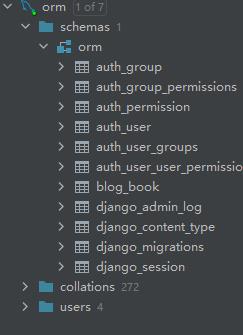
如果还想创建表,打完代码后,在控制台输入:
python manage.py migrate
然后手动刷新:
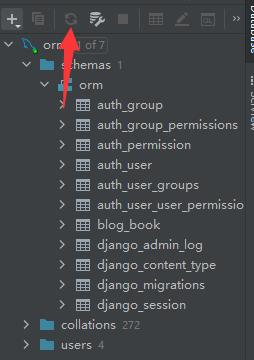
就可以看到新建的表了。
3、ORM的优缺点

4、ORM对单表的增删改查
如果我们已经创建好了表,设置了数据,又创建了新的字段,那么先前的数据对于新出的字段该怎么设置?你这时新建会出现以下提示:

要么设置默认值为false,输入1
要么新建一个文件,输入2
a、增加记录(方式一)
先来写一个页面:
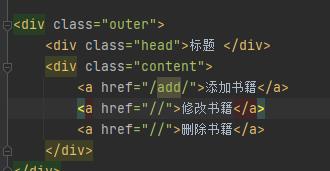

然后是views视图:

注意:这里引入models的文件,前面要加个 点
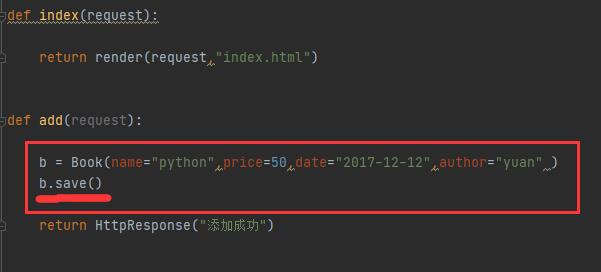
由于数据库数据是通过一个类来创建对象,所以这里要实例化b来接收,实例化之后还不行,要 实例化.save()。
a、增加记录(方式二)
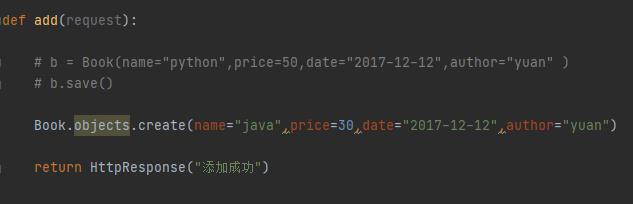
这种方式,就不需要save了。
如果我们日期写成其它格式,会报这个错误:
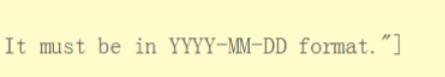
日期必须按这个格式写。
写到这里发现,这个方式的object没有代码自动补全,请参考这个博文:
https://blog.csdn.net/ch_improve/article/details/110182289
实际情况当然不可能这样一个一个加,而是用户输入,后端接收前端的数据再添加到数据库中,也不需要重新赋值,只需要设置好,再 **dic 接收字典,就可以:

两种方式都可以用。
b、修改记录(两种方式)以及实例化出来的数据类型
首先,先来看下 Book 实例化出来的对象是什么数据类型:
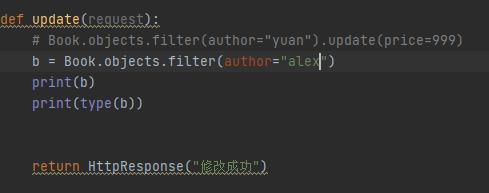

可以看到,b的数据类型是 QuerySet
虽然外面有个中括号 [ ] ,跟列表很像,但不是列表,是Django自己加的一个数据类型。
它不是一个对象,而是一个对象集合!
但是这里用get:
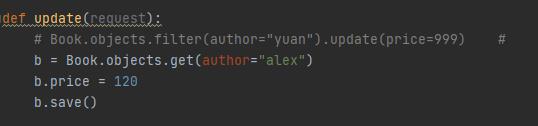
可以看到数据库成功修改记录
特别注意:
1、只要是通过类的对象操作的,最后都要 save()方法
2、有时候只想取一条,这时候要用 get(),比如:get(id=5),get只能取一个,取0个或者多个都会报错。而filter筛选出来的是一个QuerySet集合,同时取多个就用filter。
3、get方法取得的是实例化对象,所以可以进行重新赋值以及save方法调用。
4、update方法只能QuerySet对象调用!
5、注意:这两个用QuerySet,用update方法。save方法有问题,不用!!!
一般来说我们修改只是某个字段,而save方法会全部重新赋值一遍,哪怕你没有修改,它也会给你重新赋值。效率非常低。而update是单对单。
b(α)、orm语句翻译原生mysql
如果我们想要查看orm每一条语句翻译成mysql是什么样,在setting里面加这么一段:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}

运行之后,每一条orm执行的语句都能在控制台看到翻译成的mysql语句
c、删除记录
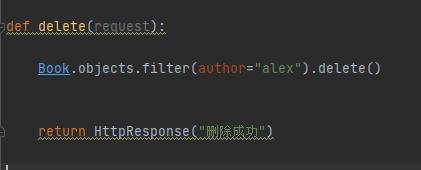
执行成功之后就可以发现成功删除!
5、ORM查询API
# 查询相关API:
# <1>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
# <2>all(): 查询所有结果
# <3>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
#-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()--------
# <4>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列
# <5>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
# <6>order_by(*field): 对查询结果排序
# <7>reverse(): 对查询结果反向排序
# <8>distinct(): 从返回结果中剔除重复纪录
# <9>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
# <10>count(): 返回数据库中匹配查询(QuerySet)的对象数量。
# <11>first(): 返回第一条记录
# <12>last(): 返回最后一条记录
# <13>exists(): 如果QuerySet包含数据,就返回True,否则返回False。
为了查询,先向数据库多添加点内容:

a、 all()方法:
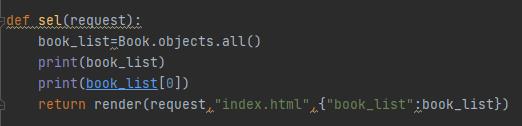
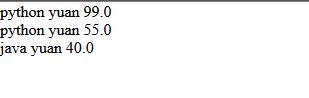
可以看到,显示成功!

还可以在 all()后面切片进行操作:

查看前面三条:
隔一个取:


倒序:


b、多条件查询
比如现在想要查询yuan作者出过的书的名字:


我们在models里加这么一个东西,方便我们查看:
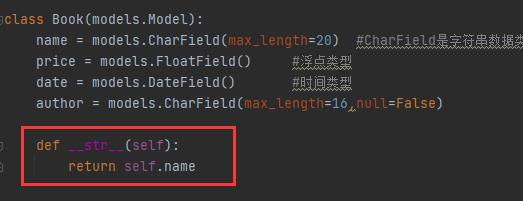

查看一下输出什么:

可以看到,里面的内容不一样了,是字典了。values是具体拿某一个字段,而不是对象了。
如果我们既想看书名,又想看到价格:

如果我们不想拿出来的是字典,而要列表:
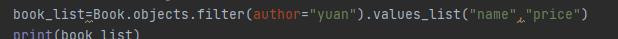

可以看到,已经不是字典了,而是列表了。
c、exclude(**kwargs)——筛选与条件不匹配的对象
取,除了作者:yuan 以外的人出版的书的名字、价格、作者

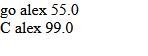
d、distinct()——从返回结果中剔除重复纪录
如果直接调用这个方法,没有任何效果,因为id是主键,id不会重复,所以要进行筛选:
这里筛选的是作者名字:

e、模糊查询之万能的双下划线 “__”——单表查询
比如现在我们想要查询价格大于50的书籍:
__gt = 50 意思就是 大于50

新增一条数据:
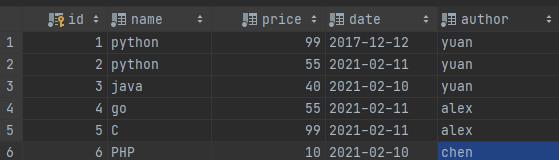
这时候我们来查找,名字开头带p的,且不区分大小写:

区分则是:contains
看结果:

关于双下划线的用法非常多,可以自行百度查找相关的用法。
内容总结
以上是互联网集市为您收集整理的Python——Django框架(三)配置数据库,ORM对单表的增删改查,ORM查询API,模糊查询(单表)之双下划线全部内容,希望文章能够帮你解决Python——Django框架(三)配置数据库,ORM对单表的增删改查,ORM查询API,模糊查询(单表)之双下划线所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。