Spark连接MySQL,Hive,Hbase
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Spark连接MySQL,Hive,Hbase,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2360字,纯文字阅读大概需要4分钟。
内容图文

Spark连接MySQL
object ConnectMysql {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[4]").appName(this.getClass.getName).getOrCreate()
//设置要访问的mysql的url,表名
val url = "jdbc:mysql://singer:3306/kb10"
val tableName ="hive_shop"
val props=new Properties()
//设置要访问的mysql的用户名,密码,Drive
props.setProperty("user","root")
props.setProperty("password","kb10")
props.setProperty("driver","com.mysql.jdbc.Driver")
//通过spark. read.jdbc方法读取mysql中数据
val df: DataFrame = spark.read.jdbc(url,tableName,props)
df.show()
//将DataFrame数据写入到MySQL中,追加方式
// df.write.mode("append").jdbc(url,tableName,props)
spark和MySQL中运行结果一致:
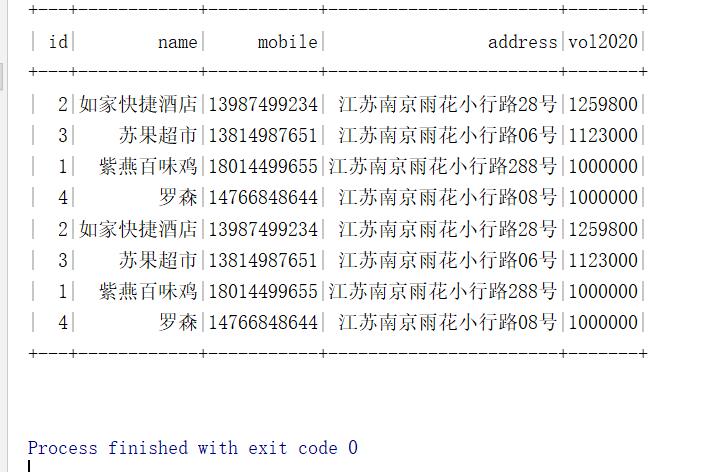
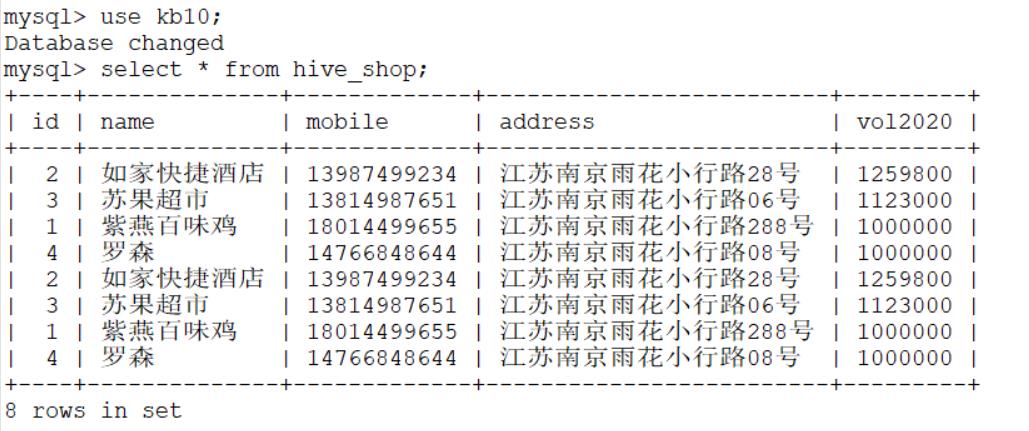
Spark连接Hive
object ConnectHive {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local[2]")
.enableHiveSupport()
.config("hive.metastore.uris", "thrift://192.168.181.129:9083")
.appName(this.getClass.getName).getOrCreate()
val df: DataFrame = spark.sql("show databases")
df.show()
}
}
spark和Hive的运行结构截图一致:
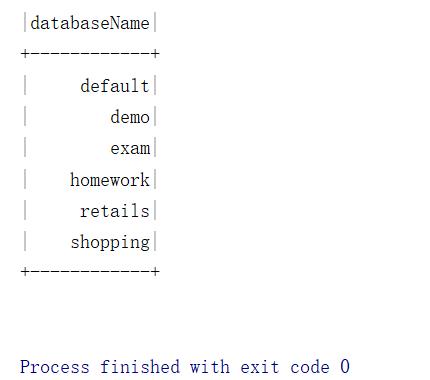
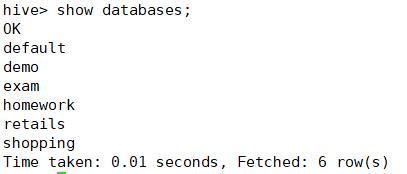
Spark连接Hbase
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.sql.SparkSession
object ConnectHbase {
def main(args: Array[String]): Unit = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum","192.168.181.129")
conf.set("hbase.zookeeper.property.clientPort","2181")
conf.set(TableInputFormat.INPUT_TABLE,"kb10:customer")
val spark = SparkSession.builder().appName("HBaseTest")
.master("local[2]")
.getOrCreate()
val sc= spark.sparkContext
val rdd1= sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result]
).cache()
println("count="+rdd1.count())
import spark.implicits._
//遍历输出
rdd1.foreach({case (_,result) =>
//通过result.getRow来获取行键
val key = Bytes.toString(result.getRow)
//通过result.getValue("列簇","列名")来获取值
//需要使用getBytes将字符流转化为字节流
val city = Bytes.toString(result.getValue("addr".getBytes,"city".getBytes))
val country = Bytes.toString(result.getValue("addr".getBytes,"country".getBytes))
val age = Bytes.toString(result.getValue("order".getBytes,"age".getBytes))
println("Row key:"+key+" city:"+city+" country:"+country+" age:"+age)
})
}
}

内容总结
以上是互联网集市为您收集整理的Spark连接MySQL,Hive,Hbase全部内容,希望文章能够帮你解决Spark连接MySQL,Hive,Hbase所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。
来源:【匿名】