Redis初步学习整理——第六节缓存击穿、缓存穿透、缓存雪崩、数据预热以及缓存模式(终节)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Redis初步学习整理——第六节缓存击穿、缓存穿透、缓存雪崩、数据预热以及缓存模式(终节),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5728字,纯文字阅读大概需要9分钟。
内容图文
")
前言
学习Redis到这节对于我现阶段来说就差不多了,更加深入的内容,不是现在我时间精力可以轻易接触的,等我搭建一个完善的知识体系后,再回来完善!
这节主要是看一下Redis的做缓存过程中遇到的各种问题,当然这部分内容,目前还没有实践过,都是通过网上文章总结来的,如果哪里不对,请指教

一、缓存模式
三种常见的缓存模式,这些应该是工作中非常常见的了,都有优缺点,需要根据具体的业务场景去适应与优化
1.Cache Aside
应用在查询数据的时候,先从缓存Cache中读取数据,如果缓存中没有,则再从数据库中读取数据,得到数据库的数据之后,将这个数据也放到缓存Cache中
如果应用要更新某个数据,也是先去更新数据库中的数据,更新完成之后,则通过指令让缓存Cache中的数据失效
(1)这里为什么不让更新操作在写完数据库之后,紧接着去把缓存Cache中的数据也修改了呢?
主要是因为这样做的话,就有2个写操作的事件了,担心在并发的情况下会导致脏数据,举个例子:假如同时有2个请求,请求A和请求B,并发的执行。请求A是要去读数据,请求B是要去更新数据。初始状态缓存中是没有数据的,当请求A读到数据之后,准备往回写的时候,此刻,请求B正好要更新数据,更新完了数据库之后,又去把缓存更新了,那请求A再往缓存中写的就是旧数据了,属于脏数据
(2)那么Cache Aside模式就没有脏数据问题了吗?
在极端情况下也可能会产生脏数据。例如,同时有2个请求,请求A和请求B,并发的执行。请求A是要去读数据,请求B是要去写数据。假如初始状态缓存中没有这个数据,那请求A发现缓存中没有数据,就会去数据库中读数据,读到了数据准备写回缓存中,就在这个时候,请求B是要去写数据的,请求B在写完数据库的数据之后,又去设置了缓存失效。这个时候,请求A由于在数据库中读到了之前的旧数据,开始往缓存中写数据了,此时写进入的就也是旧数据。那么最终就会导致,缓存中的数据与数据库的数据不一致,造成了脏数据
2.Read/Write Through
应用要读数据和更新数据都直接访问缓存服务
缓存服务同步地将数据更新到数据库
出现脏数据的概率较低,但是就强依赖缓存,对缓存服务的稳定性有较大要求
3.Write Behind模式
应用要读数据和更新数据都直接访问缓存服务
缓存服务异步地将数据更新到数据库(通过异步任务)
速度快,效率会非常高,但是数据的一致性比较差,还可能会有数据的丢失情况,实现逻辑也较为复杂。
二、缓存穿透
缓存穿透是指用户请求的数据在缓存中不存在即没有命中,同时在数据库中也不存在,导致用户每次请求该数据都要去数据库中查询一遍,然后返回空。
如果有恶意攻击者不断请求系统中不存在的数据,会导致短时间大量请求落在数据库上,造成数据库压力过大,甚至击垮数据库系统。
1.布隆过滤器(推荐,有一定误判几率)
布隆过滤器(Bloom Filter,简称BF)由Burton Howard Bloom在1970年提出,是一种空间效率高的概率型数据结构。
布隆过滤器专门用来检测集合中是否存在特定的元素。
如果在平时我们要判断一个元素是否在一个集合中,通常会采用查找比较的方法,下面分析不同的数据结构查找效率:
采用线性表存储,查找时间复杂度为O(N)
采用平衡二叉排序树(AVL、红黑树)存储,查找时间复杂度为O(logN)
采用哈希表存储,考虑到哈希碰撞,整体时间复杂度也要O[log(n/m)]
当需要判断一个元素是否存在于海量数据集合中,不仅查找时间慢,还会占用大量存储空间。接下来看一下布隆过滤器如何解决这个问题。
2.返回空对象
当缓存未命中,查询持久层也为空,可以将返回的空对象写到缓存中,这样下次请求该key时直接从缓存中查询返回空对象,请求不会落到持久层数据库。为了避免存储过多空对象,通常会给空对象设置一个较短过期时间。
这种方法会存在问题:
- 如果有大量的key穿透,缓存空对象会占用宝贵的内存空间。
3.用户合法性校验
对用户的请求合法性进行校验,拦截恶意重复请求,这个就属于系统的拦截方面了,可以直接在网关的位置添加一个拦截
三、缓存击穿
试想如果所有请求对着一个 key 照死里搞,这是不是就是一种定点打击呢?
怎么理解呢?举个极端的例子:比如某某明星爆出一个惊天狠料,海量吃瓜群众同时访问微博去查看该八卦新闻,而微博 Redis 集群中数据在此刻正好过期了,那么无数的请求则直接打到了微博系统的物理 DB 上,DB 瞬间挂了。
1. 热点数据永远不过期
比如我们可以将某个 key 的缓存时间设置为 25 小时,然后后台有个 JOB 每隔 24 小时就去批量刷新一下热点数据。就可以解决这个问题了
2.使用互斥锁(mutex key)
这种思路比较简单,就是让一个线程回写缓存,其他线程等待回写缓存线程执行完,重新读缓存即可。
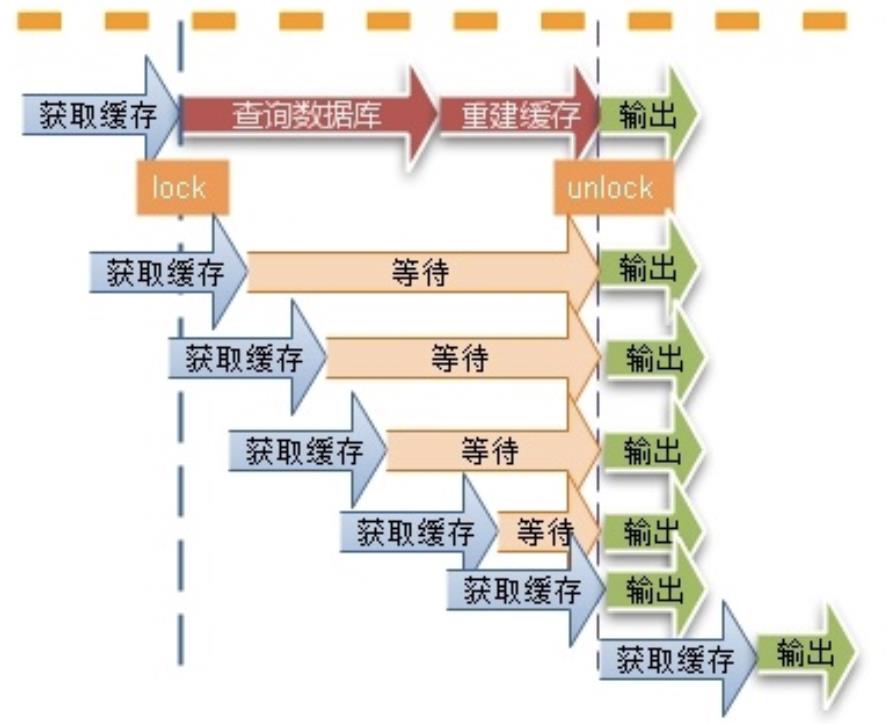
同一时间只有一个线程读数据库然后回写缓存,其他线程都处于阻塞状态。如果是高并发场景,大量线程阻塞势必会降低吞吐量。这种情况如何解决?大家可以在留言区讨论。
如果是分布式应用就需要使用分布式锁。
四、缓存雪崩
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,请求直接落到数据库上,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
缓存雪崩解决方案
1.均匀过期
设置不同的过期时间,让缓存失效的时间点尽量均匀。通常可以为有效期增加随机值或者统一规划有效期。
2.加互斥锁
跟缓存击穿解决思路一致,同一时间只让一个线程构建缓存,其他线程阻塞排队。
3.缓存永不过期
跟缓存击穿解决思路一致,缓存在物理上永远不过期,用一个异步的线程更新缓存。
4.双层缓存策略
使用主备两层缓存:
主缓存:有效期按照经验值设置,设置为主读取的缓存,主缓存失效后从数据库加载最新值。
备份缓存:有效期长,获取锁失败时读取的缓存,主缓存更新时需要同步更新备份缓存。
五、缓存预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统,这样就可以避免在用户请求的时候,先查询数据库,然后再将数据回写到缓存。
如果不进行预热, 那么 Redis 初始状态数据为空,系统上线初期,对于高并发的流量,都会访问到数据库中, 对数据库造成流量的压力。
缓存预热的操作方法
-
数据量不大的时候,工程启动的时候进行加载缓存动作;
-
数据量大的时候,设置一个定时任务脚本,进行缓存的刷新;
-
数据量太大的时候,优先保证热点数据进行提前加载到缓存。
六、缓存降级
缓存降级是指缓存失效或缓存服务器挂掉的情况下,不去访问数据库,直接返回默认数据或访问服务的内存数据。
在项目实战中通常会将部分热点数据缓存到服务的内存中,这样一旦缓存出现异常,可以直接使用服务的内存数据,从而避免数据库遭受巨大压力。
降级一般是有损的操作,所以尽量减少降级对于业务的影响程度。
结语
以上内容整理自多篇文章,等一下会给列出来,不过因为查看的都是微信公众号的文章,微信公众号文章链接有一定时效性,就在这里打出来对应的公众号名字吧,有需要的可以自行查看:爱笑的架构师、邋遢的流浪剑客、Linux云计算网络
自此我的Redis学习暂时告一段落了,学习的并不深,只是基础的使用,以后还会跟进学习。欧力给
内容总结
以上是互联网集市为您收集整理的Redis初步学习整理——第六节缓存击穿、缓存穿透、缓存雪崩、数据预热以及缓存模式(终节)全部内容,希望文章能够帮你解决Redis初步学习整理——第六节缓存击穿、缓存穿透、缓存雪崩、数据预热以及缓存模式(终节)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。