Linux下安装Hadoop 详解及WordCount运行
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Linux下安装Hadoop 详解及WordCount运行,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3196字,纯文字阅读大概需要5分钟。
内容图文

-
单机配置环境如下:
Hadoop(3.1.1)安装包JDK1.8.0_231安装包
Centos -Linux系统环境 -
使用ssh进行本地免密登录
ssh-keygen -t rsa -P "" -f ~/.ssh/id_rsacat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keyschmod 755 ~/.ssh/authorized_key
登录成功:
-
安装并配置JDK
tar -zxvf jdk-8u231-linux-x64.tar.gzmkdir /usr/loca/javacp jdk1.8.0_231 /usr/local/java/vim /etc/profileexport JAVA_HOME=/usr/local/java/jdk1.8.0_231/export PATH=$JAVA_HOME/bin:$PATHjava -version
-
解压缩Hadoop安装包
tar -zxvf FusionInsight-Hadoop-3.1.1.tar.gz
解压缩后出现hadoop的文件夹 -
配置Hadoop环境变量
export HADOOP_HOME=/home/lhh/hive/hadoop/export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
-
创建机器名字
vim /etc/hostname
vim /etc/hosts
hostname hadoop-01
重启服务器,修改生效 -
配置Hadoop中的相应文件
./hadoop/etc/hadoop/hadoop-env.sh、core-site.xml、mapred-site.xml、hdfs-site.xml、yarn-site.xml
./hadoop/sbin/start-dfs.sh、stop-dfs.sh、start-yarn.sh、stop-yarn.sh
-
新建hadoop-env.sh配置如下:
export JAVA_HOME=/usr/local/java/jdk1.8.0_231/
注意:hadoop-3.1.1版本需要手动创建该文件 -
core-site.xml配置如下:
<configuration> <property> <name>hadoop.tmp.dir</name> <value>/home/lhh/hive/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-01:9000</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> </configuration> -
mapred-site.xml配置如下:
<configuration> <property> <name>mapred.job.tracker</name> <value>hadoop-1:9001</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
hdfs-site.xml配置如下:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/home/lhh/hive/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/lhh/hive/tmp/dfs/data</value> </property> </configuration> -
yarn-site.xml配置文件如下:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-01</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME,HADOOP_HOME,PATH,LANG,TZ</value> </property> </configuration>
8.运行Hadoop
-
在解压后的hadoop目录下使用如下命令:
./bin/hdfs namenode -format
-
开启NameNode、DataNode等守护进程
./sbin/start-all.sh./sbin/mr-jobhistory-daemon.sh start historyserver
-
查看进程信息
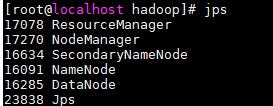
-
查看Web UI
lsof -i:9870
查看端口是否被监听,在网页输入如下网址:
http://10.71.232.64:9870
9.运行WordCount
1)本地创建test.txt文件
2)在HDFS新建一个文件夹,用于上传测试文件./bin/hdfs dfs -mkdir /test
3)将本地text.txt上传到test目录中./bin/hdfs dfs -put /home/lhh/hive/test.txt /test
4)运行WordCount./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1-hw-ei-302005.jar wordcount /test/test.txt /test/out
5)查看结果./bin/hadoop fs -cat /test/out/part-r-00000
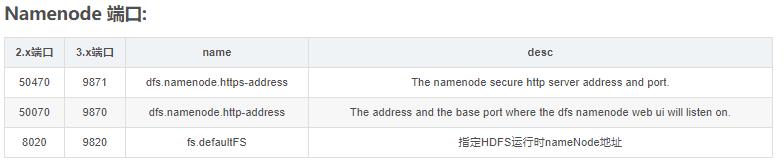
9.hadoop2.x/3.x常用端口号览表


内容总结
以上是互联网集市为您收集整理的Linux下安装Hadoop 详解及WordCount运行全部内容,希望文章能够帮你解决Linux下安装Hadoop 详解及WordCount运行所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。