Hadoop笔记(一):CentOS7 安装 Hadoop-2.6.4
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Hadoop笔记(一):CentOS7 安装 Hadoop-2.6.4,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含5601字,纯文字阅读大概需要9分钟。
内容图文
:CentOS7 安装 Hadoop-2.6.4")
Hadoop集群
Hadoop集群,具体来说包含两个集群:hdfs集群和yarn集群。两者逻辑上分离,但物理上常在一起。
hdfs集群:
负责海量数据的存储工作。集群中的角色主要有 NameNode、DataNode。
yarn集群:
负责海量数据运算时的资源调度。集群中的角色主要有ResourceManager、NodeManager。
安装Hadoop集群前提
- 已安装 JDK如需了解,请点击链接: CentOS 7 安装 JDK8】
- 关闭防火墙【
或者开放指定端口号(点击链接: Linux 开放制定端口)---- 线上环境不建议关闭防火墙】
Hadoop-2.6.4 安装
1.机器分布
| 机器名(hosts) | IP | 角色 |
|---|---|---|
| master | 192.168.204.210 | namenode |
| slave01 | 192.168.204.211 | datanode |
| slave02 | 192.168.204.212 | datanode |
2.hosts配置
在master、slave01、slave02 三台机器上,使用命令:vim /etc/hosts配置 hosts
192.168.204.210 master
192.168.204.211 slave01
192.168.204.212 slave02
3.开始安装
Hadoop安装路径:/usr/local/env 路径下
提示:除 source /etc/profile.d/hadoop.sh 等刷新操作,所有操作均在 master 节点完成!
3.1 下载 hadoop-2.6.4.tar.gz,到/usr/local/env 路径下
附:hadoop所有版本下载地址。下载比较慢。同时附:百度网盘下载地址(提取密码:a6li)
3.2 查看JAVA_HOME安装地址
命令:echo $JAVA_HOME 复制 JAVA_HOME 路径

3.3 解压缩 hadoop-2.6.4.tar.gz 到 /usr/local/env 路径下
命令:tar zxvf hadoop-2.6.4.tar.gz 解压缩

3.4 进入 hadoop-2.6.4/etc/hadoop 目录下,完成对相关文件的配置操作
3.4.1 配置hadoop-env.sh
配置JAVA_HOME
使用:set nu可查看行号,在25行配置 JAVA_HOME 路径

3.4.2 配置core-site.xml
配置内容如下:
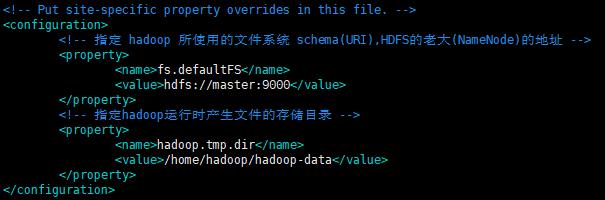
<configuration>
<!-- 指定 hadoop 所使用的文件系统 schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-data</value>
</property>
</configuration>
3.4.3 配置hdfs-site.xml
此项:可以不用配,每一个都已默认的配置
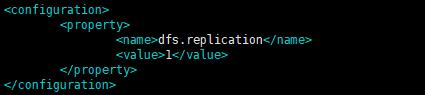
<!-- 指定HDFS副本的数量(默认是3) -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3.4.4 配置mapred-site.xml
将 mapred-site.xml.template重命名为mapred-site.xml
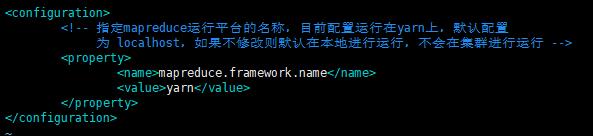
<configuration>
<!-- 指定mapreduce运行平台的名称,目前配置运行在yarn上,默认配置
为 localhost,如果不修改则默认在本地进行运行,不会在集群进行运行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.4.5 配置yarn-site.xml
配置内容如下:
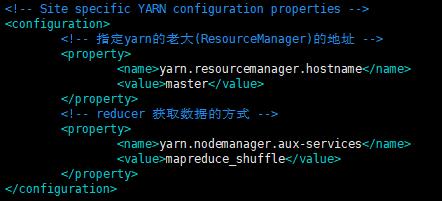
<configuration>
<!-- 指定yarn的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.5 master节点配置完毕后,目前不能启动hadoop集群。需要将已经配置好的 hadoop文件夹,分发到slave01 和 slave02其他机器
命令:scp -r /usr/local/env/hadoop-2.6.4 root@slave01:/usr/local/env/
scp -r /usr/local/env/hadoop-2.6.4 root@slave02:/usr/local/env/

如需了解 scp 命令的使用,请参考:scp 命令的使用
3.6 配置 hadoop环境变量
hadoop安装路径:/usr/local/env/hadoop-2.6.4
Linux设置全局变量 或者 用户级别变量,请点击链接查看:我是链接。
此处设置全局变量
命令: cd /etc/profile.d/ 进入 profile.d目录,通过vi hadoop.sh 创建文件,配置内容如下:

并使用scp命令,将环境变量配置分发到 slave01 和 slave02 机器上:
命令:scp -r /etc/profile.d/hadoop.sh root@slave01:/etc/profile.d、
scp -r /etc/profile.d/hadoop.sh root@slave02:/etc/profile.d
配置完成后,切记,使用命令:source /etc/profile.d/hadoop.sh使配置生效
# 配置 hadoop 环境变量
export HADOOP_HOME=/usr/local/env/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.7 对master节点,进行格式计划操作(即:hdfs要进行格式化)
命令:hdfs namenode -format
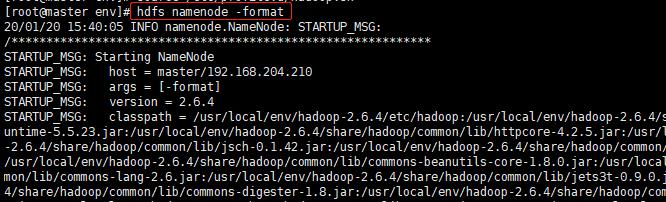
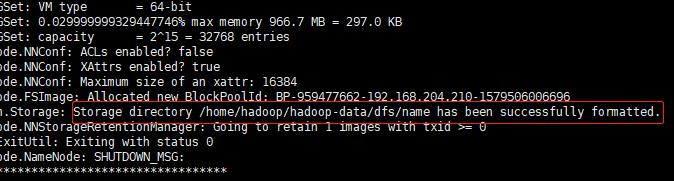
格式化成功,如下图所示:
3.8 在master节点,配置 master节点对 slave01、slave02节点的免密登录
第1步:ssh-keygen 【全部回车】
第2步:ssh-copy-id master
ssh-copy-id slave01
ssh-copy-id slave02 【全部免密登陆配置完毕】
第3步:在 master节点,通过命令ssh slave02,能登录到slave02及诶单,说明免密登录配置成功
3.9 集中管理hadoop集群配置
在 hadoop-2.6.4/etc/hadoop 目录下slaves文件中配置的是 hadoop 的 datanode。将两个 datanode 节点,配置在该文件下。【一行一个节点】,如下图所示

这样你就省去了,你在 master 节点启动 namenode,然后再去 slave01 和 slave02 节点分别取启动 datanode 的繁琐,方便你在 master 节点几种管理 hadoop集群
3.10 启动hadoop集群
第一种:
1.执行 hadoop-2.6.4/sbin目录下的 start-dfs.sh 将 hdfs 全部启动。【如果hadoop 环境变量配置成功的话,可以直接使用start-dfs.sh】

2.执行 hadoop-2.6.4/sbin目录下的 start-yarn.sh 将 yarn 全部启动。【如果hadoop 环境变量配置成功的话,可以直接使用start-yarn.sh】

附:使用 stop-dfs.sh和stop-yarn.sh,可以关闭 hdfs、yarn。
第二种:
执行 hadoop-2.6.4/sbin目录下的 start-all.sh 将 hdfs 和 yarn 全部启动。【如果hadoop 环境变量配置成功的话,可以直接使用start-all.sh】
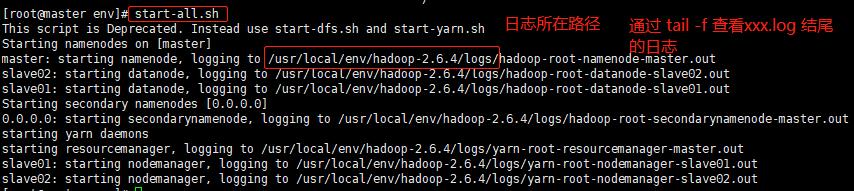
附:使用 stop-all.sh,可以全部关闭 hdfs、yarn。
建议使用:
start-dfs.sh加start-yarn.sh启动,方便查看是否有错误
至此hadoop集群便可以正常启动了
3.11 启动hadoop集群
hdfs管理界面:http://master:50070
MR(mapReduce)管理界面 http://master:8088
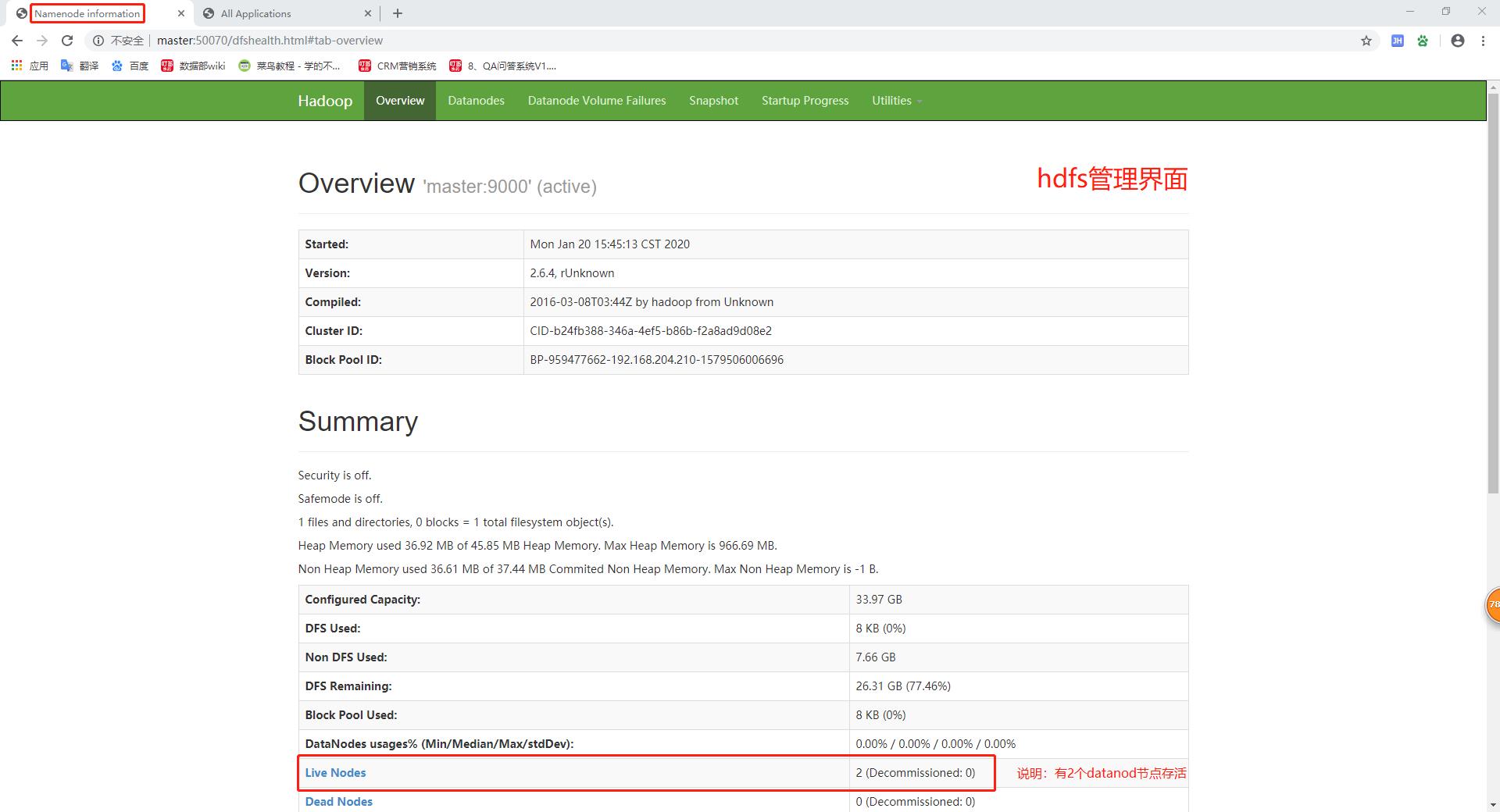

4.测试集群是否正常运行
测试:MapReducer PI运算
命令:hadoop jar /usr/local/env/hadoop-2.6.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar pi 5 10
执行过程:
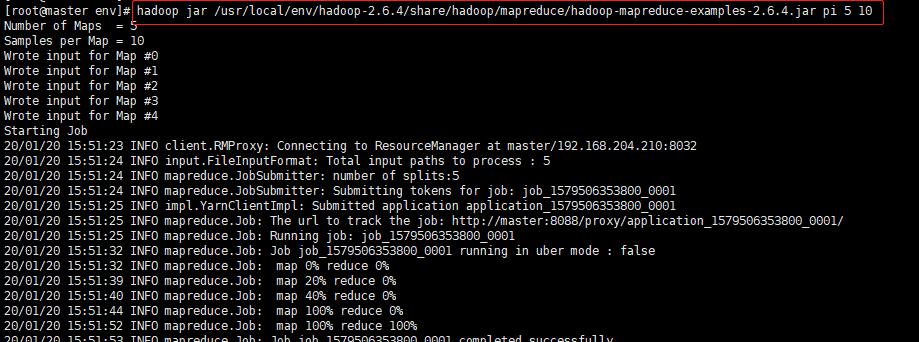
执行结果:
Estimated value of Pi is 3.28000000000000000000
MR管理界面:
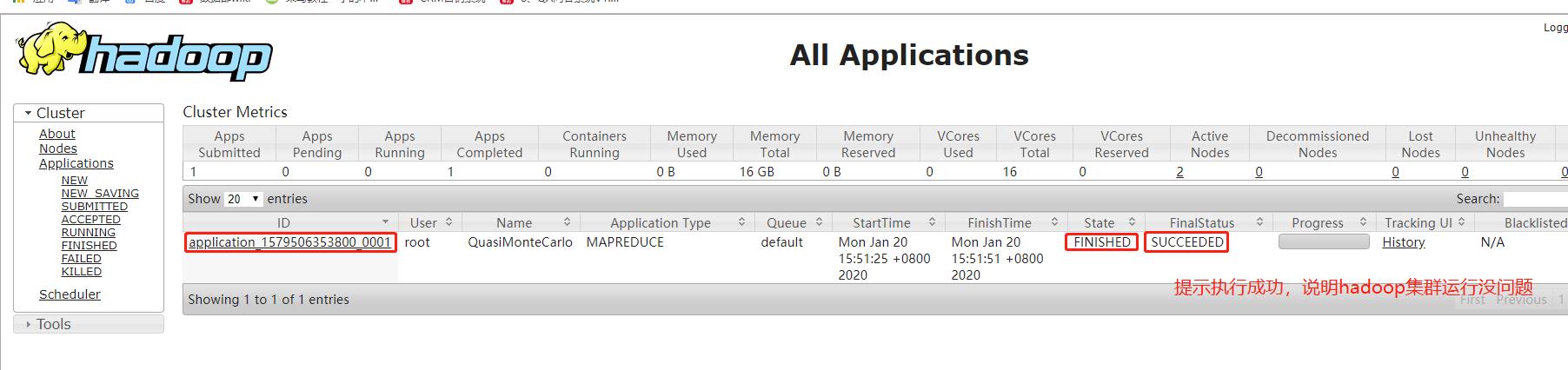
CentOS7 安装 Hadoop-2.6.4,介绍到此为止
如果本文对你有所帮助,那就给我点个赞呗 O(∩_∩)O
End
扛麻袋的少年 发布了239 篇原创文章 · 获赞 44 · 访问量 5万+ 私信 关注内容总结
以上是互联网集市为您收集整理的Hadoop笔记(一):CentOS7 安装 Hadoop-2.6.4全部内容,希望文章能够帮你解决Hadoop笔记(一):CentOS7 安装 Hadoop-2.6.4所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。