基于golang分布式爬虫系统的架构体系v1.0
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了基于golang分布式爬虫系统的架构体系v1.0,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含2379字,纯文字阅读大概需要4分钟。
内容图文

基于golang分布式爬虫系统的架构体系v1.0
一、什么是分布式系统
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
从分布式系统的概念中我们知道,各个主机之间通信和协调主要通过网络进行,所以分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被放在不同的机柜上,也可能被部署在不同的机房中,还可能在不同的城市中,对于大型的网站甚至可能分布在不同的国家和地区。
二、分布式系统的特点
不同的资料介绍起分布式系统的特点,虽然说法不同,但都大同小异,此处我们针对于要实现的分布式爬虫,总结为以下3个特点:
多个节点
容错性
可扩展性(性能)
固有分布性
消息传递
节点具有私有存储
易于开发
可扩展性(功能)
对比:并行计算
完成特定需求
消息传递的方法:
REST
RPC
中间件
三、需求说明设计要点
在爬虫的开发过程中,有些业务场景须要同一时候抓取几百个甚至上千个站点,此时就须要一个支持多爬虫的框架。在设计时应该要注意下面几点:
代码复用。功能模块化。假设针对每一个站点都写一个完整的爬虫。那当中必然包括了很多反复的工作。不仅开发效率不高。并且到后期整个爬虫项目会变得臃肿、难以管理。
易扩展。多爬虫框架,这最直观的需求就是方便扩展。新增一个待爬的目标站点,我仅仅须要写少量 必要的内容(如抓取规则、解析规则、入库规则),这样最快 最好。
健壮性、可维护性。
这么多站点同一时候抓取,报错的概率更大。比如断网、中途被防爬、爬到“脏数据”等等。所以必须要做好日志监控,能实时监控爬虫系统的状态,能准确、具体地定位报错信息;另外要做好各种异常处理,假设你放假回来发现爬虫由于一个小问题已经挂掉了,那你会由于浪费了几天时间而可惜的(尽管其实我个人会不时地远程查看爬虫状态)。
分布式。多站点抓取。数据量一般也比較大,可分布式扩展。这也是必需的功能了。分布式。须要注意做好消息队列。做好多结点统一去重。
爬虫优化。
这就是大话题了,但最主要的。框架应该要基于异步,或者使用协程+多进程。
四、项目架构分析
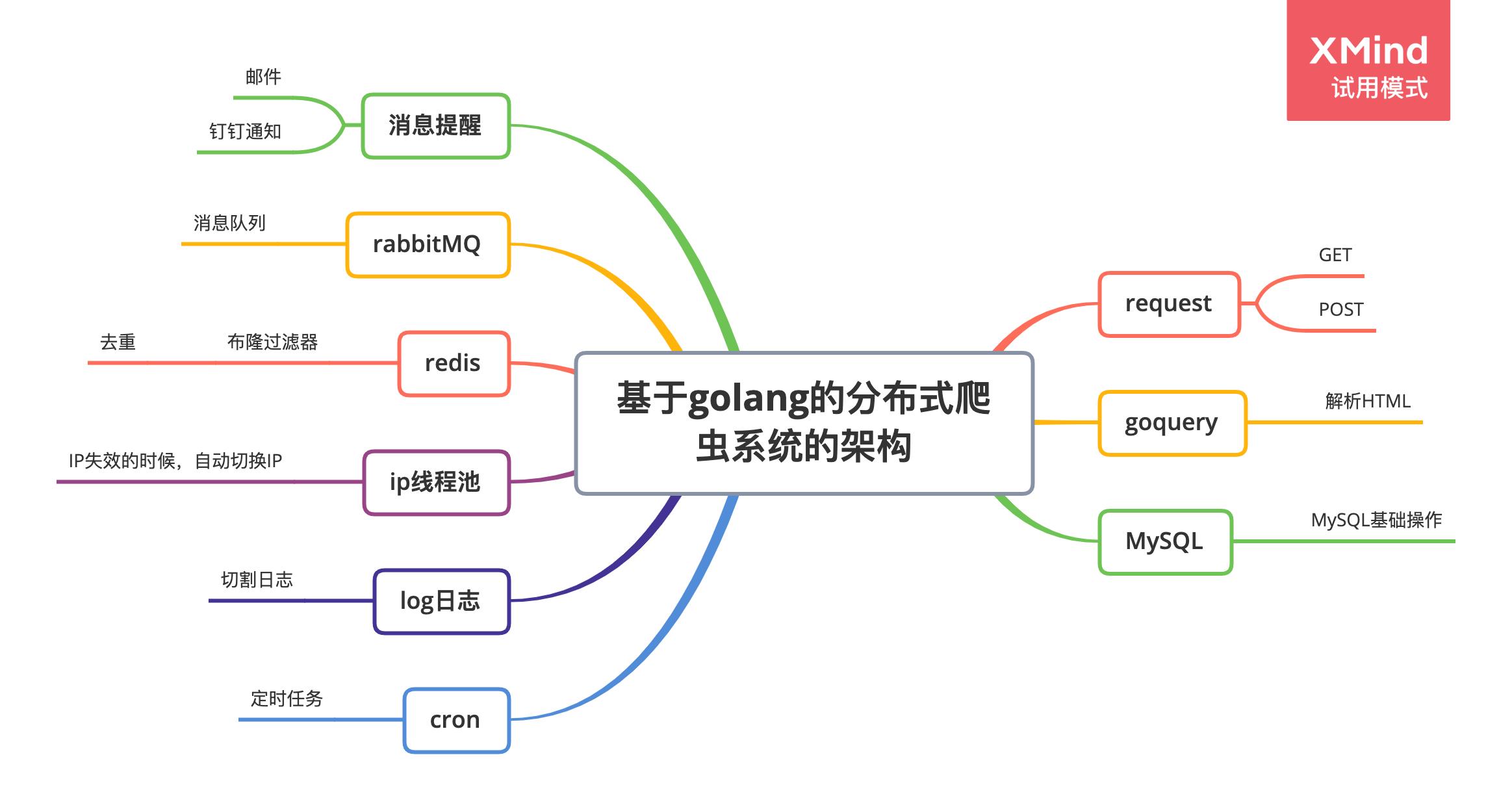
4.1 去重问题
可以尝试写布隆过滤器来更快的实现改需求
-
问题:
-
单节点承受的去重数据量有限
-
无法保存之前去重结果(因为是存入到内存(map))
-
解决:
-
基于Key-Value Stroe(如Redis)进行分布式去重
4.2 数据存储问题
问题:
-
存储部分的结构,技术栈和爬虫部分区别很大
-
进一步优化需要特殊的ElasticSearch技术背景
-
解决:
-
存储服务
复杂分布式爬虫系统的大框架,具体实现的时候,还有很多的细节需要处理,这时,之前做过爬虫系统,踩过坑的经验就很重要了。
内容总结
以上是互联网集市为您收集整理的基于golang分布式爬虫系统的架构体系v1.0全部内容,希望文章能够帮你解决基于golang分布式爬虫系统的架构体系v1.0所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。