机器学习入门-概念、线性回归、损失函数、Tensorflow及Numpy、泛化及数据集划分
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了机器学习入门-概念、线性回归、损失函数、Tensorflow及Numpy、泛化及数据集划分,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含11041字,纯文字阅读大概需要16分钟。
内容图文

文章目录
机器学习基本概念和术语和术语第一部分内容整理,简要介绍机器学习、线性回归及损失函数、Tensorflow及numpy、泛化及数据集划分相关内容。
一、机器学习入门概念
一、基本概念
参考https://zhuanlan.zhihu.com/p/86794447
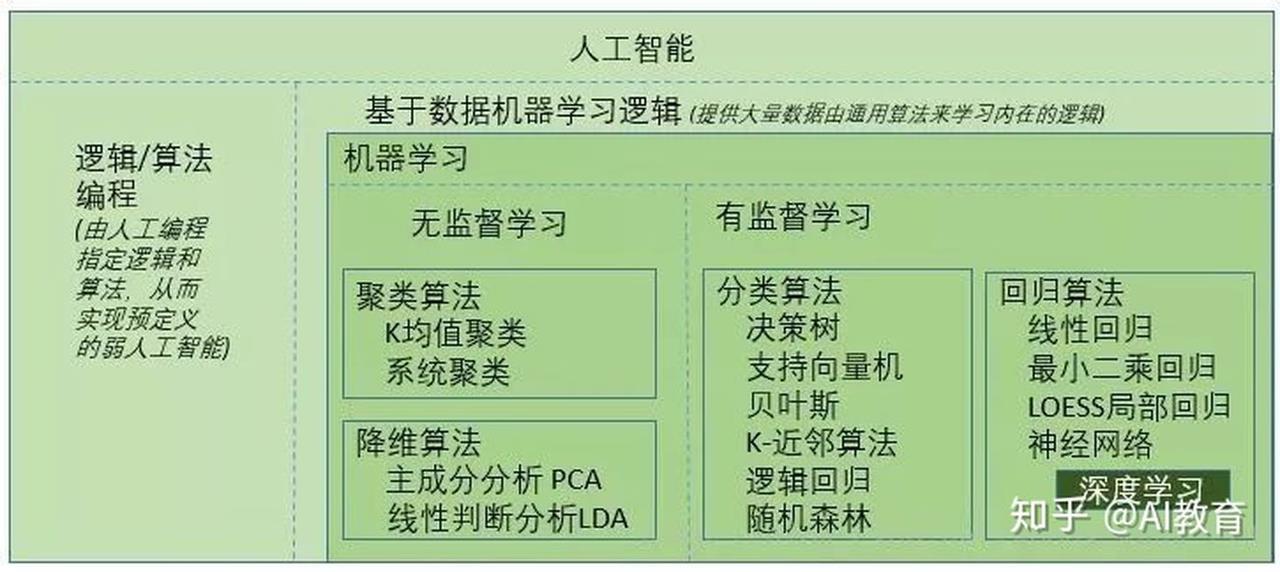
机器学习:让机器进行学习和决策
机器学习与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”模型,通过各种算法从数据中学习如何完成任务,最后使用模型对数据进行预测。
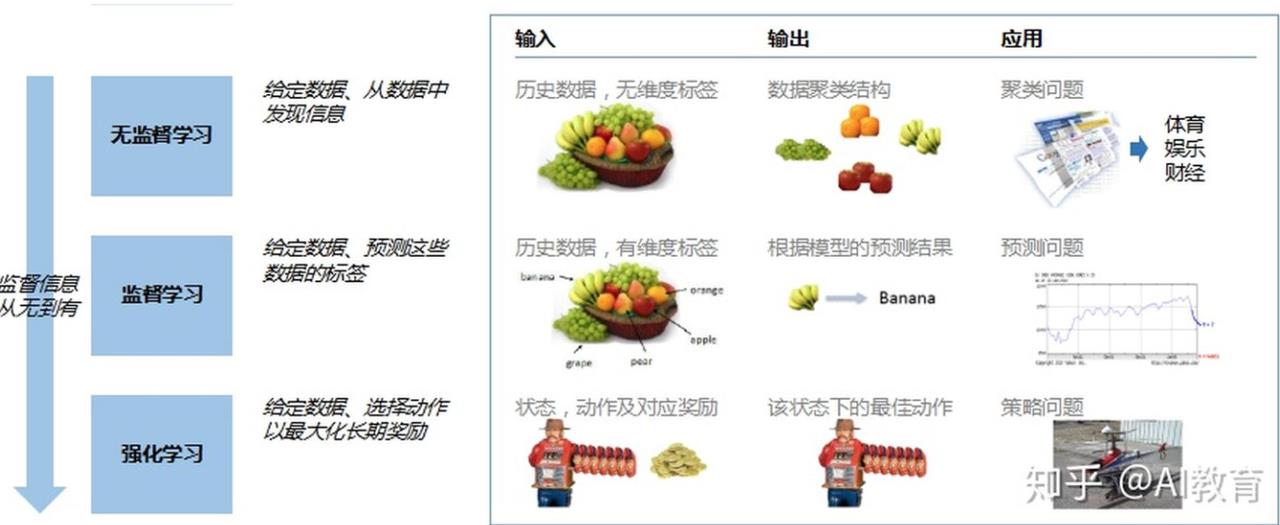
机器学习分类:无监督学习、监督学习、强化学习
- 第一类是无监督学习,指的是从信息出发自动寻找规律,并将其分成各种类别,有时也称"聚类问题"。
- 第二类是监督学习,监督学习指的是给历史一个标签,运用模型预测结果。如有一个水果,我们根据水果的形状和颜色去判断到底是香蕉还是苹果,这就是一个监督学习的例子。
- 第三类为强化学习,是指可以用来支持人们去做决策和规划的一个学习方式,它是对人的一些动作、行为产生奖励的回馈机制,通过这个回馈机制促进学习,这与人类的学习相似,所以强化学习是目前研究的重要方向之一。
深度学习:模拟人脑,自动提取输入特征,是实现机器学习的方式之一
传统的ML最大的问题就是特征提取。比如让机器识别照片中的动物是猫还是狗,如何设计特征?深度学习(以下简称为DL)正是为了解决特征提取的问题,我们不再需要人工设计特征,而是让算法从数据中自动学习特征,将简单的特征组合形成复杂的特征来解决这些问题,所以DL可以说是实现ML的一种技术。
机器学习同深度学习之间是有区别的,机器学习是指计算机的算法能够像人一样,从数据中找到信息,从而学习一些规律。虽然深度学习是机器学习的一种,但深度学习是利用深度的神经网络,将模型处理得更为复杂,从而使模型对数据的理解更加深入。
深度学习是机器学习中一种基于对数据进行表征学习的方法。深度学习是机器学习研究中的一个新的领域,其动机在于建立、模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本。
神经网络:一种机器学习的方式
神经网络在设计的时候就是模仿人脑的处理方式,希望其可以按人类大脑的逻辑运行,神经网络的原理是受我们大脑的生理结构——互相交叉相连的神经元启发。但与大脑中一个神经元可以连接一定距离内的任意神经元不同,人工神经网络具有离散的层、连接和数据传播的方向。
例如,我们可以把一幅图像切分成图像块,输入到神经网络的第一层。在第一层的每一个神经元都把数据传递到第二层。第二层的神经元也是完成类似的工作,把数据传递到第三层,以此类推,直到最后一层,然后生成结果。
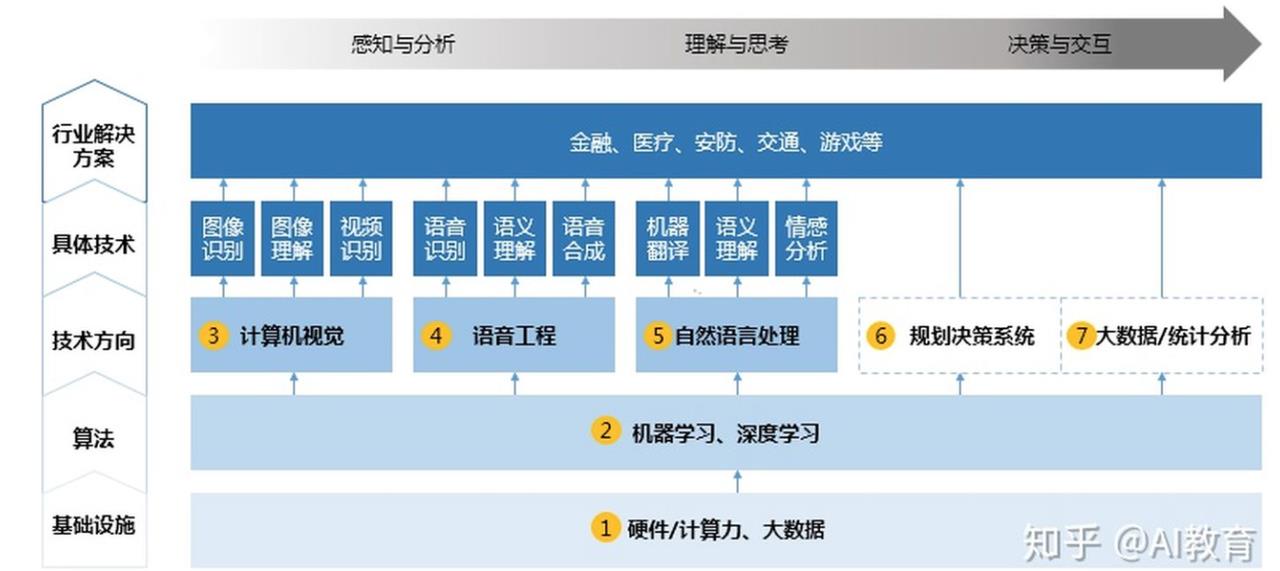
人工智能的几大方向:从基础到应用层面分为基础设施、算法、技术方向、具体技术、行业解决方案。
二、基本术语
- 监督式学习:机器学习系统通过组合输入信息来对未见过的数据进行预测。
- 标签:标签指的是预测的数值结果,是线性回归中的y变量,比如可以是物品的识别可以得到一个标签y,y=1表示是水果,y=2表示是动物等等。
- 特征:特征指的是线性回归中的输入x变量,简单的模型可能使用很少的特征,复杂的模型可能使用上百万的特征。
- 在垃圾邮件检测器示例中,特征可能包括:
- 电子邮件文本中的字词
- 发件人的地址
- 发送电子邮件的时段
- 电子邮件中包含“一种奇怪的把戏”这样的短语。
- 样本:样本指的是数据的特定实例x向量,样本可以分为有标签样本和无标签样本:
- 有标签样本:(features, label) = (x, y),同时存在特征与标签
- 无标签样本:(features, label) = (x, ?),只存在特征而标签未知
机器学习使用有标签样本来训练模型。在我们的垃圾邮件检测器示例中,有标签样本是用户明确标记为“垃圾邮件”或“非垃圾邮件”的各个电子邮件。在使用有标签样本训练模型之后,我们会使用该模型预测无标签样本的标签。 - 模型:模型定义了特征与标签之间的关系。例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”紧密联系起来。我们来重点介绍一下模型生命周期的两个阶段:
- 训练是指创建或学习模型。也就是说,向模型展示有标签样本,让模型逐渐学习特征与标签之间的关系。
- 推断是指将训练后的模型应用于无标签样本。也就是说,使用经过训练的模型做出有用的预测 (y’)。
- 模型分类:
- 回归模型:回归模型可以得到连续的预测结果,用于获得定量的输出,比如预测明天气温多少度。
- 分类模型:分类模型可以得到离散的预测结果,用于获得定型的输出,比如预测明天天气热不热。
二、线性回归与损失函数
一、什么是线性回归
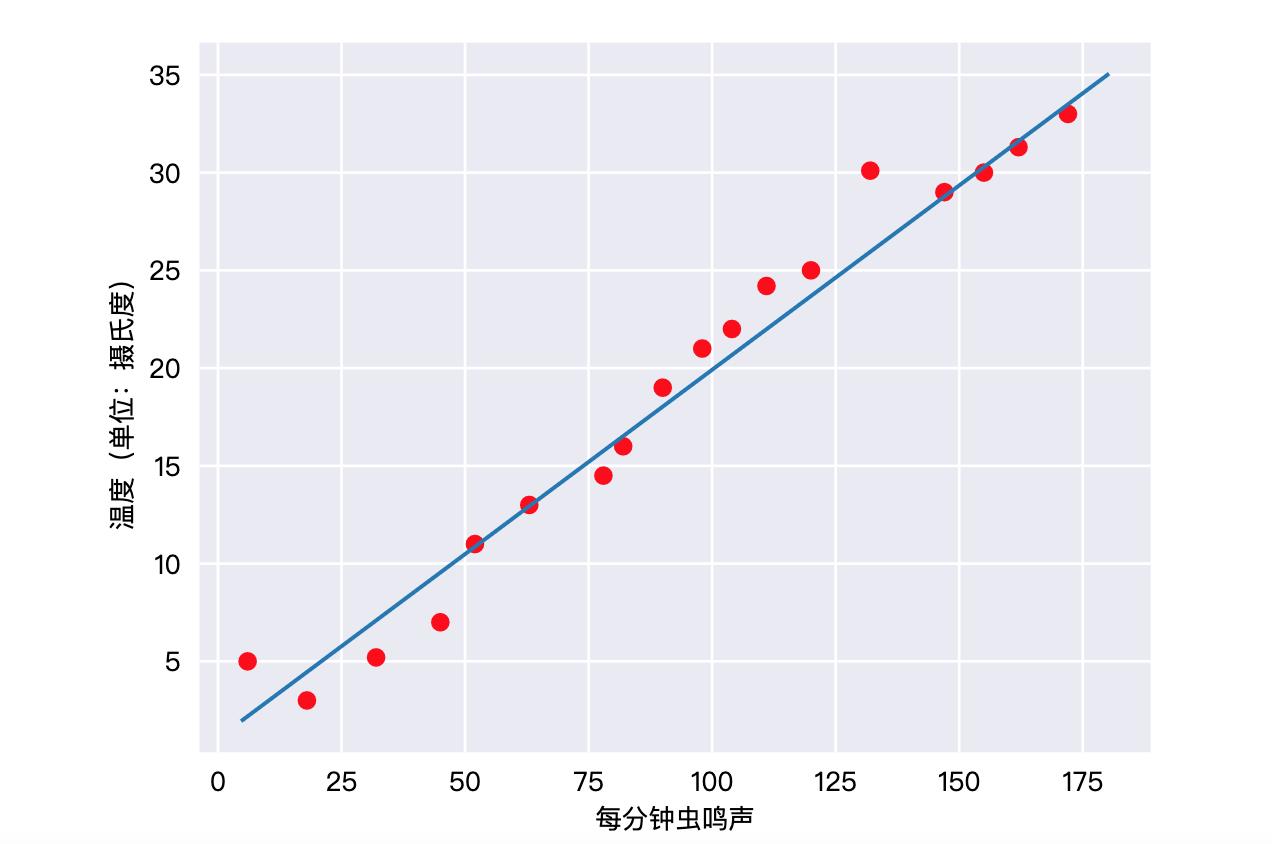
线性回归指的是一类输出结果和输入特征呈现线性关系的回归。比如在炎热的夏天,蟋蟀的叫声越大表明天气越热,那么蟋蟀的叫声和天气温度就可以组成一个线性回归的关系:
二、方程表达

三、多特征线性回归
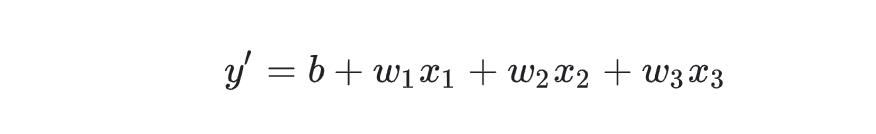
四、损失函数
模型训练过程是对有标签样本的检查过程,已找到一个损失最小的模型。
通过损失的大小来评价模型的好坏,损失过大则拟合不够,损失越小说明模型效果越好。
一般使用均方误差来作为损失函数:
预测的结果y(x)(线性回归直线)于真实结果y0之间的误差可用方差 y(x)^2 - y0^2来表示,为了获取整体的误差,一般使用均方误差来表达线性回归整体的误差情况,假如有N个数据:
均方误差MSE :
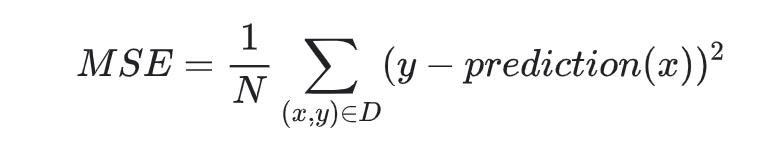
五、降低损失方法
降低损失的方法,也就是找到损失函数的损失最低点:
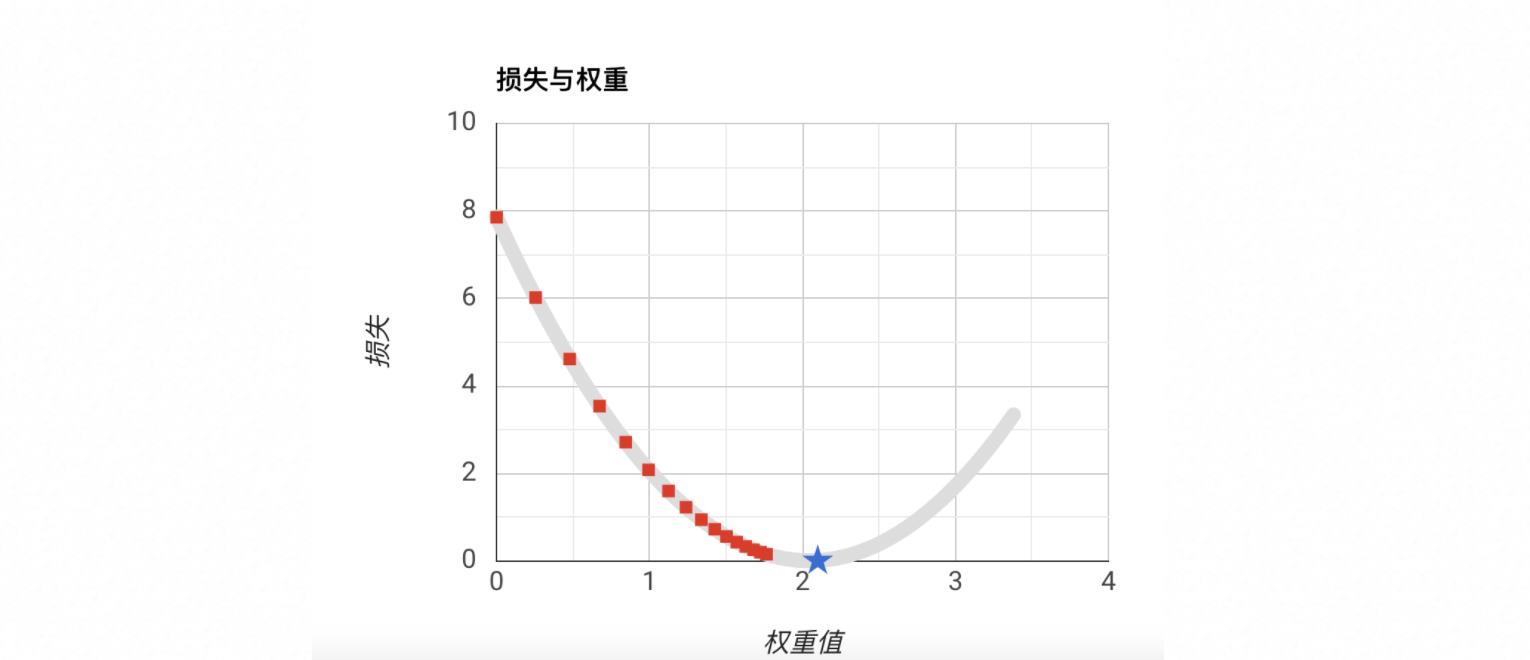
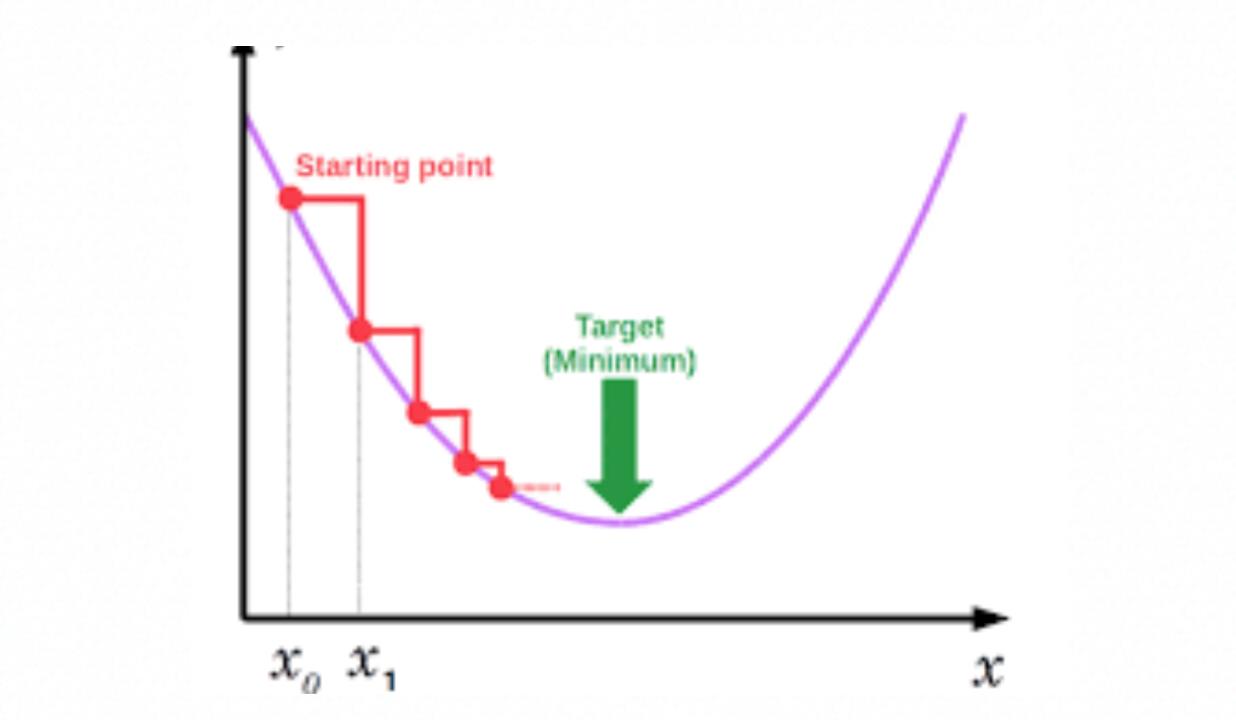
损失函数并不是一个基本的规则函数,所以不能用常规的方式直接求得,而是采用迭代的方式去获取,一般采用梯度下降法去获取该损失函数最低损失点,以便获得对应的模型调参参数。
梯度下降法的原理是,给定一个步长L,在曲线中一点开始,获取该点的导数Y,如果Y<0则说明曲线下降,继续按步长往右走,如果Y>0则说明曲线上升,继续按步长往左走,直到Y=0,找到最低点。
六、随机梯度下降和小批量梯度下降
- 全批量梯度下降法
采用所有样本来计算梯度,耗时很久,效率低。 - 随机梯度下降法
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数。到目前为止,我们一直假定批量是指整个数据集。就 Google 的规模而言,数据集通常包含数十亿甚至数千亿个样本。此外,Google 数据集通常包含海量特征。因此,一个批量可能相当巨大。如果是超大批量,则单次迭代就可能要花费很长时间进行计算。
包含随机抽样样本的大型数据集可能包含冗余数据。实际上,批量大小越大,出现冗余的可能性就越高。一些冗余可能有助于消除杂乱的梯度,但超大批量所具备的预测价值往往并不比大型批量高。
如果我们可以通过更少的计算量得出正确的平均梯度,会怎么样?通过从我们的数据集中随机选择样本,我们可以通过小得多的数据集估算(尽管过程非常杂乱)出较大的平均值。 随机梯度下降法 (SGD) 将这种想法运用到极致,它每次迭代只使用一个样本(批量大小为 1)。如果进行足够的迭代,SGD 也可以发挥作用,但过程会非常杂乱。“随机”这一术语表示构成各个批量的一个样本都是随机选择的。 - 小批量梯度下降法
该方法是介于全批量迭代与 SGD 之间的折衷方案。小批量通常包含 10-1000 个随机选择的样本。小批量 SGD 可以减少 SGD 中的杂乱样本数量,但仍然比全批量更高效。
三、Tensorflow和Numpy
- TensorFlow官网:https://www.tensorflow.org/about
一、什么是TensorFlow
参考:https://blog.csdn.net/qq_38361726/article/details/87717447
https://blog.csdn.net/geyunfei_/article/details/78782804
Tensorflow是一个Google开发的第二代机器学习系统,克服了第一代系统DistBelief仅能开发神经网络算法、难以配置、依赖Google内部硬件等局限性,应用更加广泛,并且提高了灵活性和可移植性,速度和扩展性也有了大幅提高。字面上理解,TensorFlow就是以张量(Tensor)在计算图(Graph)上流动(Flow)的方式的实现和执行机器学习算法的框架。具有以下特点:
- 灵活性。TensorFlow不是一个严格的“神经网络”库。只要可以将计算表示成数据流图,就可以使用TensorFlow,比如科学计算中的偏微分求解等。(实际上其官网的介绍中对TF的定位就是基于数据流图的科学计算库,而非仅仅是机器学习库)
- 可移植性。同一份代码几乎不经过修改既可以部署到有任意数量CPU、GPU或TPU(Tensor Processing Unit,Google专门为机器学习开发的处理器)的PC、服务器或移动设备上。
- 自动求微分。同Theano一样,TensorFlow也支持自动求微分,用户不需要再通过反向传播求解梯度。
- 多语言支持。TensorFlow官方支持Python、C++、Go和Java接口,用户可以在硬件配置较好的机器中用Python进行实验,在资源较紧张或需要低延迟的环境中用C++进行部署。
- 性能。虽然TensorFlow最开始发布时仅支持单机,在性能评测上并不出色,但是凭借Google强大的开发实力,TensorFlow性能已经追上了其他框架。
- 多平台多环境运行
TensorFlow可以便捷地实现: - 模型训练
- 图像、语音处理
- 深度学习
- 神经网络
二、基本概念
要使用TensorFlow,我们必须理解TensorFlow:
- 使用图(Graph)表示计算流程
- 在会话(Session)中执行图
- 使用张量(Tensor)表示数据
- 使用变量(Variable)维护状态
- 使用feed和fetch为任意的操作赋值或从中获取数据
TF使用graph表示计算流程。图中的节点称为操作(Operation,以下简称OP)。每个OP接受0到多个Tensor,执行计算,输出0到多个Tensor。图是对计算流程的描述,需要在Session中运行。Session将计算图的OP分配到CPU或GPU等计算单元,并提供相关的计算方法,并且会返回OP的结果。
-
张量(Tensor)
TF使用Tensor表示所有数据,相当于Numpy中的ndarray,0维的数值、一维的矢量、二维的矩阵到n维数组都是Tensor。 -
变量(Variable)
在训练模型时,Variable被用来存储和更新参数。Variable包含张量储存在内存的缓冲区中,必须显式地进行初始化,在训练后可以写入磁盘。 -
Feed
TensorFlow除了可以使用Variable和Constant引入数据外,还提供了Feed机制实现从外部导入数据。一般Feed总是与占位符placeholder一起使用。 -
Graph图和Session会话
由于TF采用符号式编程模式,所以TF程序通常可以分为两部分:图的构建和图的执行。
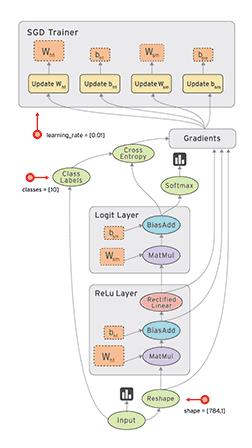
-
图的构建
构建图的第一步,是创建源OP(source op),源操作不需要任何输入,例如常量(constant),源操作的输出被传递给其它操作做运算。
Python库中,OP构造器的返回值代表被构造出的OP的输出,这些返回值可以传递给其它OP构造器作为输入。
TensorFlow Python库有一个默认图 (default graph),OP构造器可以为其增加节点。这个默认图对许多程序来说已经足够用了。
三、使用步骤(结合numpy)
在线练习:https://colab.research.google.com/notebooks/mlcc/first_steps_with_tensor_flow.ipynb?utm_source=mlcc&utm_campaign=colab-external&utm_medium=referral&utm_content=firststeps-colab&hl=zh-cn#scrollTo=gzb10yoVrydW
四、什么是Numpy
NumPy是Python的一个用于科学计算的基础包。它提供了多维数组对象,多种衍生的对象(例如隐藏数组和矩阵)和一个用于数组快速运算的混合的程序,包括数学,逻辑,排序,选择,I/O,离散傅立叶变换,基础线性代数,基础统计操作,随机模拟等等。
NumPy包的核心是ndarray对象。它封装了n维同类数组。很多运算是由编译过的C代码来执行的,以此来提高效率。在计算矢量和多维矩阵相乘时十分方便,所以可以用于数据分析和科学计算。
在线练习:
https://colab.research.google.com/notebooks/mlcc/intro_to_pandas.ipynb?utm_source=mlcc&utm_campaign=colab-external&utm_medium=referral&utm_content=pandas-colab&hl=zh-cn#scrollTo=Fc1DvPAbstjI
四、泛化与数据集划分
一、泛化和过拟合
泛化指的是模型对未知数据的预测能力或拟合能力。
机器学习的整体目标是通过对少数样本的学习,从而达到对样本整体的正确预测。如果一个模型在少数样本中表现得很少,损失很小,但在样本整体上表现得不好,损失很大,那么称该模型过拟合。
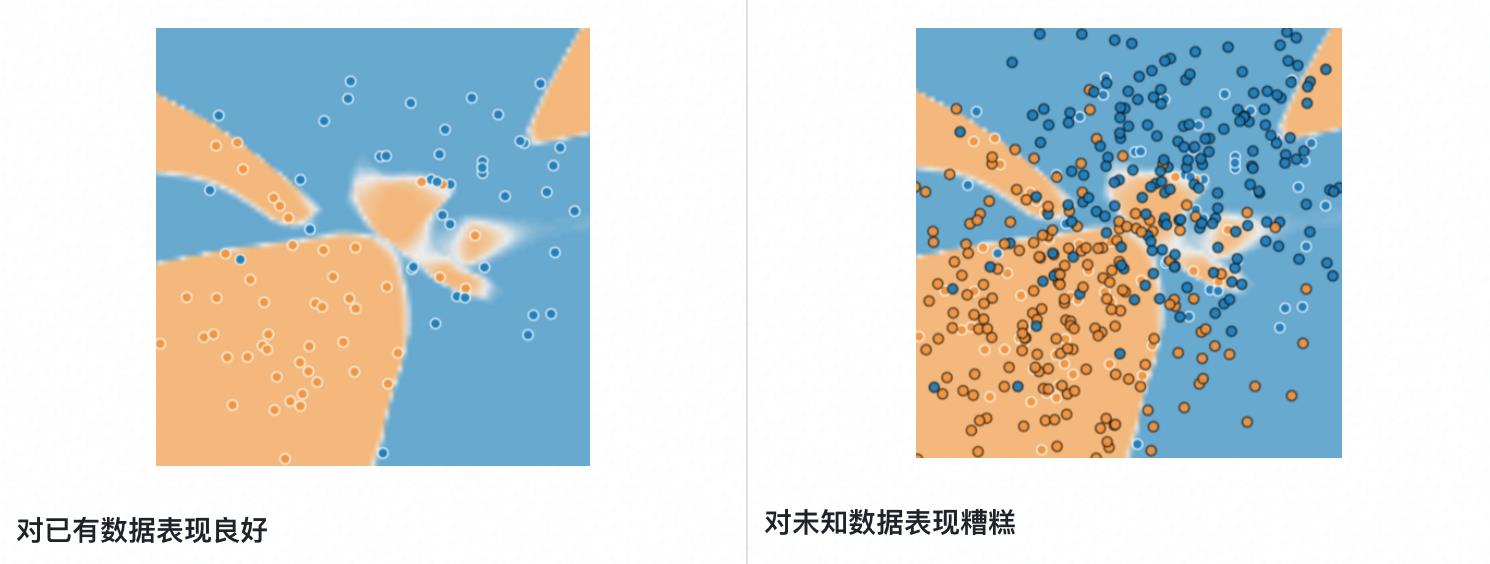
二、解决过拟合的方法:划分出测试集
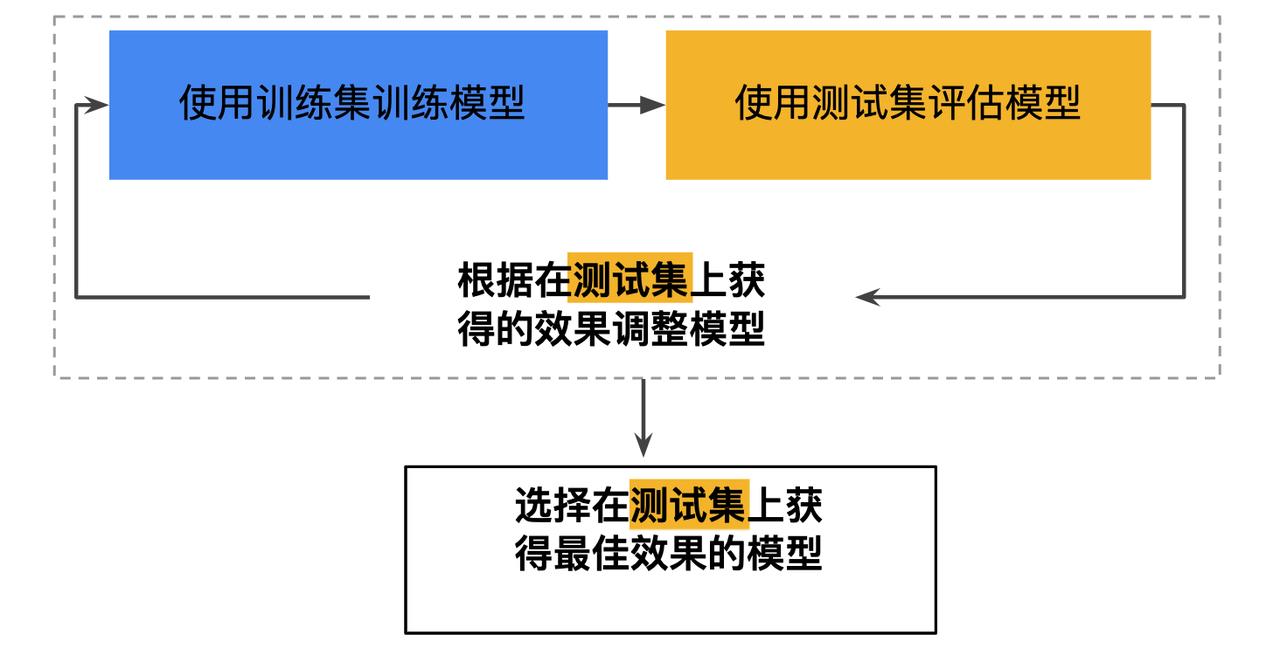
为了解决过拟合的问题,需要在在数据集中划分出训练集和测试集,当使用训练集对模型进行训练和基本的测试之后,需要再通过测试集对其训练结果测试,以测试集的拟合程度来判断训练的好坏,而不是原有的那份数据。
将数据集划分为训练集和测试集后,每次模型迭代完都需要使用测试集来测试最终的效果,看测试集的损失是否和训练集损失大致一致,当两者一致时认为这次迭代是有效的,该模型可以和训练时一样的泛化性能。
一般来说,一份数据集中划分出来的训练集和测试集数据量越大越好,当测试集数据量过小时,可以采用交叉验证的方式去进行测试。
一般测试集占整体数据集的10%~20%。
·只使用测试集的训练流程
三、进一步避免过拟合:划分验证集
如果只是在一份数据集中划分出训练集和测试集,基于给定测试集执行评估的次数越多,不知不觉地过拟合该测试集的风险就越高,所以不能循环基于测试集进行效果评估,而是再数据集中再划分出一个验证集,使用验证集来对训练好的模型进行效果评估,当达到最优时,在最终使用测试集进行最终的测试。

·使用验证集和测试集的训练流程
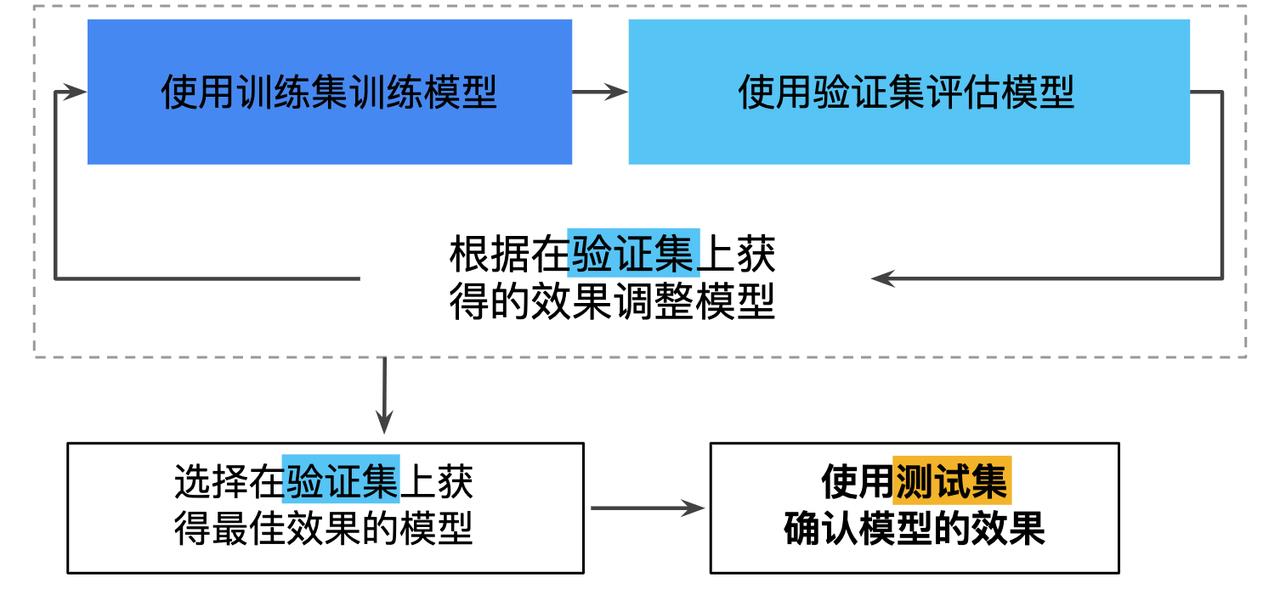
TIPS:不断使用测试集和验证集会使其逐渐失去效果,建议收集更多数据来“刷新”测试集和验证集。
内容总结
以上是互联网集市为您收集整理的机器学习入门-概念、线性回归、损失函数、Tensorflow及Numpy、泛化及数据集划分全部内容,希望文章能够帮你解决机器学习入门-概念、线性回归、损失函数、Tensorflow及Numpy、泛化及数据集划分所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。