Hbase介绍
1 Hbase是什么2 Hbase特点2.1 优点2.2 缺点
3 Hbase架构3.1 架构图3.2 基础组件说明3.2.1 Client3.2.2 Zookeeper3.2.3 Master:(是所有 Region Server 的管理者)3.2.4 RegionServer:(为 Region 的管理者)3.2.5 Region3.2.6 Store3.2.7 MemStore3.2.8 StoreFile3.2.9 HFile3.2.10 HLog4 Data Model数据模型4.1 逻辑结构图
5 Hbase工作流程5.1 Region 寻址5.2 读请求过程5.3 写请求过程
6 使用Hbase注意点6.1 Hbase的...
HBase对于非Java语言提供了Thrift接口支持,这里结合对HBase Thrift接口(HBase版本为0.92.1)的使用经验,总结其中遇到的一些问题及其相关注意事项。1. 字节的存放顺序HBase中,由于row(row key和column family、column qualifier、time stamp)是按照字典序进行排序的,因此,对于short、int、long等类型的数据,通过Bytes.toBytes(…)转换成byte数组后,必须按照大端模式(高字节在低地址,低字节在高地址)存放。对于value,也...
HBase对于非Java语言提供了Thrift接口支持,这里结合对HBase Thrift接口(HBase版本为0.92.1)的使用经验,总结其中遇到的一些问题及其相关注意事项。1. 字节的存放顺序HBase中,由于row(row key和column family、column qualifier、time stamp)是按照字典序进行排序的,因此,对于short、int、long等类型的数据,通过Bytes.toBytes(…)转换成byte数组后,必须按照大端模式(高字节在低地址,低字节在高地址)存放。对于value,也...
HBase对于非Java语言提供了Thrift接口支持,这里结合对HBase Thrift接口(HBase版本为0.92.1)的使用经验,总结其中遇到的一些问题及其相关注意事项。1. 字节的存放顺序HBase中,由于row(row key和column family、column qualifier、time stamp)是按照字典序进行排序的,因此,对于short、int、long等类型的数据,通过Bytes.toBytes(…)转换成byte数组后,必须按照大端模式(高字节在低地址,低字节在高地址)存放。对于value,也...
HBase对于非Java语言提供了Thrift接口支持,这里结合对HBase Thrift接口(HBase版本为0.92.1)的使用经验,总结其中遇到的一些问题及其相关注意事项。1. 字节的存放顺序HBase中,由于row(row key和column family、column qualifier、time stamp)是按照字典序进行排序的,因此,对于short、int、long等类型的数据,通过Bytes.toBytes(…)转换成byte数组后,必须按照大端模式(高字节在低地址,低字节在高地址)存放。对于value,也...
配置 thriftpython使用的包 thrift个人使用的python 编译器是pycharm community edition. 在工程中设置中,找到project interpreter, 在相应的工程下,找到package,然后选择 “+” 添加, 搜索 hbase-thrift (Python client for HBase Thrift interface),然后安装包。安装服务器端thrift。参考官网,同时也可以在本机上安装以终端使用。thrift Getting Started也可以参考安装方法 python 调用HBase 范例首先,安装thrift下载thri...
新来的一个工程师不懂HBase,java不熟,python还行,我建议他那可以考虑用HBase的thrift调用,完成目前的工作。首先,安装thrift下载thrift,这里,我用的是thrift-0.7.0-dev.tar.gz 这个版本tar xzf thrift-0.7.0-dev.tar.gz
cd thrift-0.7.0-dev
sudo ./configure --with-cpp=no --with-ruby=no
sudo make
sudo make install然后,到HBase的源码包里,找到src/main/resources/org/apache/hadoop/hbase/thrift/执行thrift --gen p...
新霸哥注意到了在人类随着计算机技术的发展,数据的存储量发生了很大的变化,可以用海量来形容,同时,存储的数据类型也是有多种多样的,网页,图片,视频,音频,电子邮件等等,所以在这中情况下以谷歌旗下的BigTable为代表的新型数据库产生并且迅速发展。Hbase就是BigTable的开源实现,下面新霸哥将详细的为你揭晓HBase相关知识以及相关应用。互联网时代对数据库的要求和传统的还是有区别的其中比较突出的一点就是数据量的问题,...
HBase是Hadoop的数据库,能够对大数据提供随机、实时读写访问。他是开源的,分布式的,多版本的,面向列的,存储模型。在讲解的时
HBase是Hadoop的数据库,能够对大数据提供随机、实时读写访问。他是开源的,分布式的,多版本的,面向列的,存储模型。
在讲解的时候我首先给大家讲解一下HBase的整体结构,如下图:HBase Master是服务器负责管理所有的HRegion服务器,HBase Master并不存储HBase服务器的任何数据,HBase逻辑上的表可...
[HBase]完全分布式安装过程详解 HBase版本:0.90.5 Hadoop版本:0.20.2 OS版本:CentOS 安装方式:完全分布式(1个master,3个regionserver) 1)解压缩HBase安装文件 [hadoop@node01 ~]$ tar -zxvf hbase-0.90.5.tar.gz 解压缩成功后的HBase主目录结构如下[HBase]完全分布式安装过程详解HBase版本:0.90.5
Hadoop版本:0.20.2
OS版本:CentOS
安装方式:完全分布式(1个master,3个regionserver)
1)解压缩HBase安装文件
[hadoo...
1、什么是HBase?
HBase 是一个分布式,可扩展,面向列的适合存储海量数据的NoSQL数据库,其最主要的功能是解决海量数据下的实时随机读写的问题。 HBase 依赖 HDFS 做为底层分布式文件系统。
1、特性
强读写一致,但是不是最终一致性的数据存储,这使得它非常适合高速的计算聚合自动分片,通过Region分散在集群中,当行数增长的时候,Region也会自动的切分和再分配自动的故障转移Hadoop/HDFS集成,和HDFS开箱即用丰富、简洁、高效的...
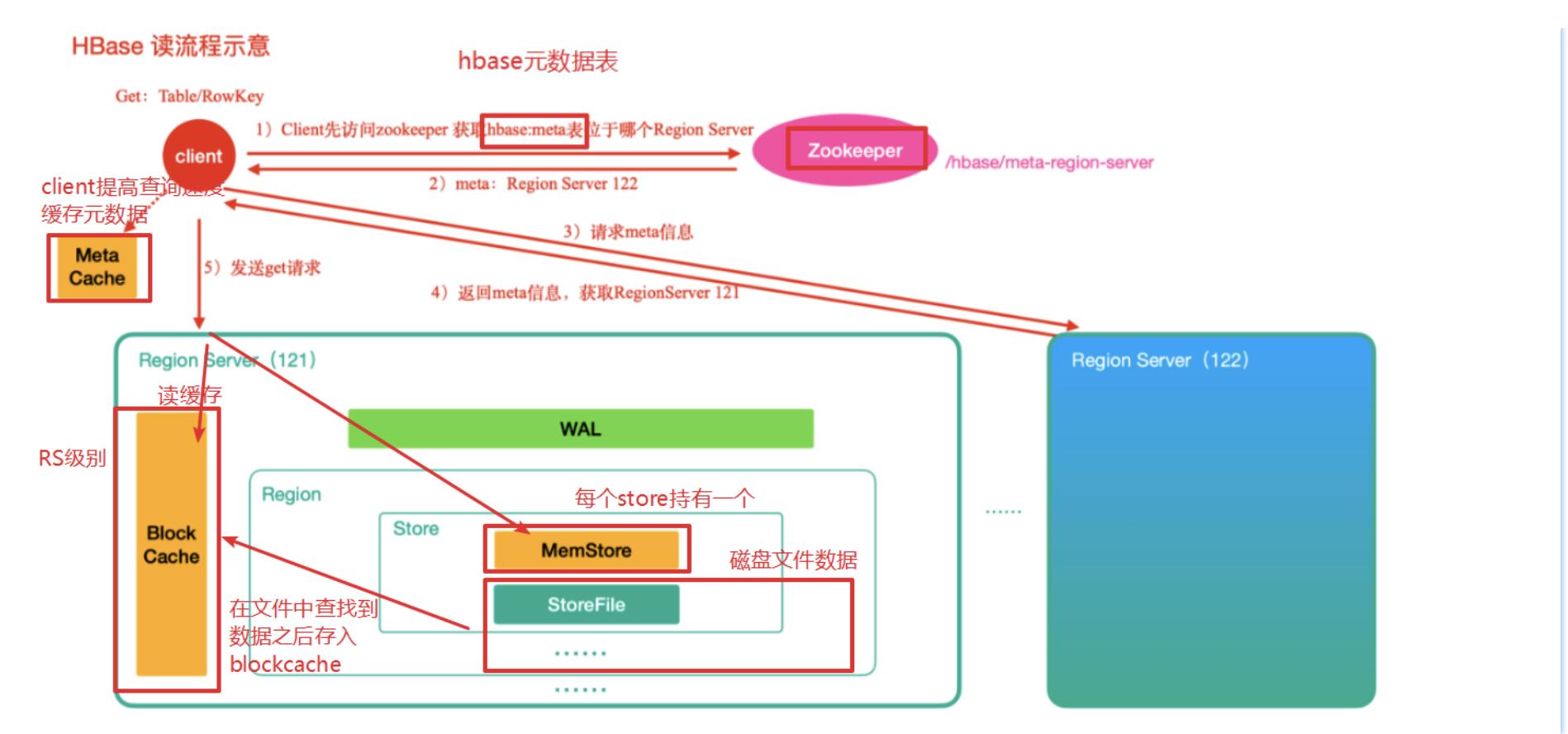
HBase读数据流程
HBase读数据流程
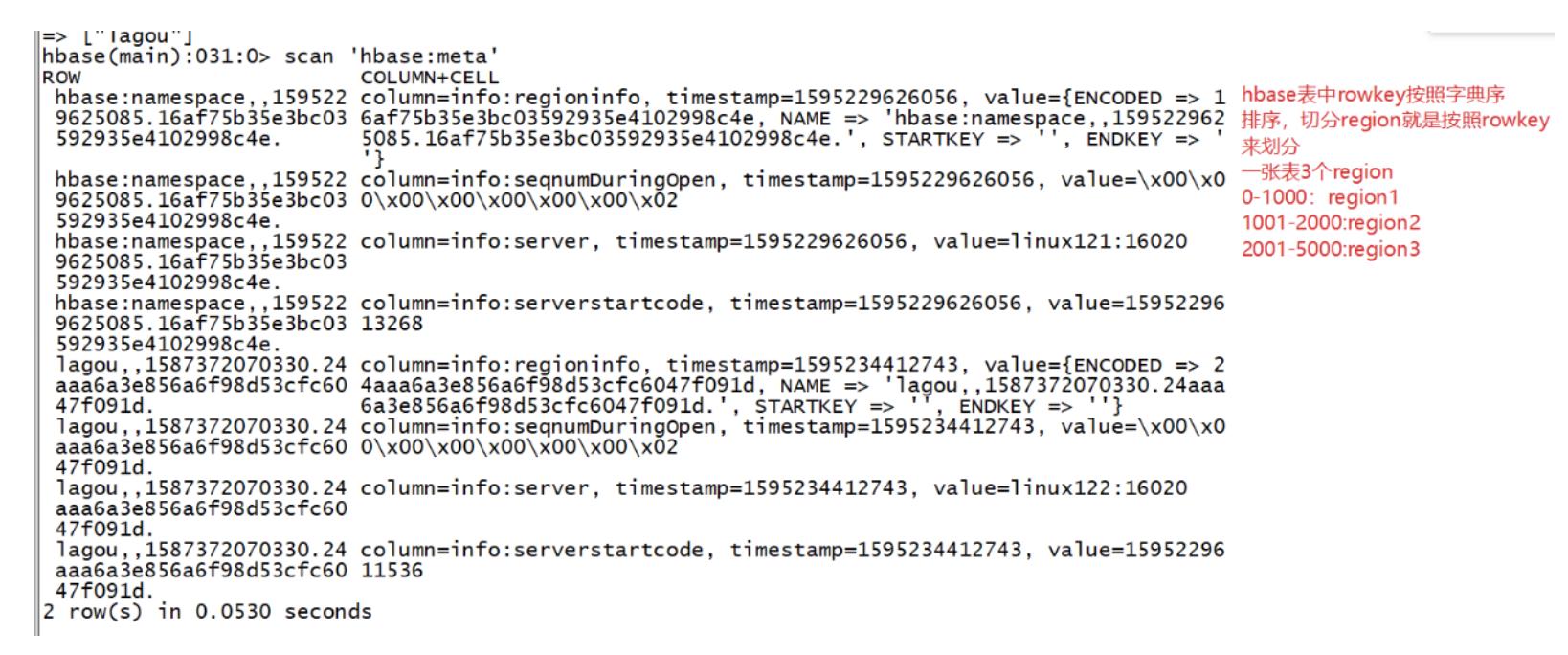
HBase元数据信息.HBase读操作首先从zk中找到meta表的region信息,然后meta表中的数据,meta表中存储了用户的region信息
根据要查询的namespace、表名和rowkey信息,找到对应的真正存储要查询的数据的region信息
找到这个region对应的regionServer,然后发送请求
查找对应的region
先从metastore查找数据,如果没有,再从BlockCache读取。
HBase上的RegionServer的内存分为两个部分
一部分作为...