Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫),小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含3472字,纯文字阅读大概需要5分钟。
内容图文
")
Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)
一、requests库的基本使用
requests是python语言编写的简单易用的HTTP库,使用起来比urllib更加简洁方便。
requests是第三方库,使用前需要通过pip安装。
pip install requests
1.基本用法:
import
requests
#
以百度首页为例
response = requests.get(‘http://www.baidu.com‘)
#response对象的属性print(response.status_code) # 打印状态码print(response.url) # 打印请求urlprint(response.headers) # 打印头信息print(response.cookies) # 打印cookie信息print(response.text) #以文本形式打印网页源码print(response.content) #以字节流形式打印
运行后显示:
状态码:200 url:www.baidu.com #输出headers信息、cookie信息以及网页源码信息 <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
2.各种请求方式(HTTP测试网站:http://httpbin.org/)
import
requests
requests.get(
‘
http://httpbin.org/get
‘
)
requests.post(
‘
http://httpbin.org/post
‘
)
requests.put(
‘
http://httpbin.org/put
‘
)
requests.delete(
‘
http://httpbin.org/delete
‘
)
requests.head(
‘
http://httpbin.org/get
‘
)
requests.options(
‘
http://httpbin.org/get
‘)
3.response对象的方法
json():能够在HTTP响应内容中解析存在的JSON数据,方便解析HTTP的操作。
raise_for_status():只要返回的请求状态status_code不是200,则产生异常。用于try-except语句。
requests会产生几种常用异常:
ConnectionError异常:网络异常,如DNS查询失败、拒绝连接等。
HTTPError异常:无效HTTP响应。
Timeout异常:请求URL超时。
TooManyRedirects异常:请求超过了设定的最大重定向次数。
获取一个网页的内容的函数建议使用如下代码:
def
getHTMLText(url):
try
:
r=requests.get(url,timeout=30)
r.raise_for_status()#如果状态不是200,抛出异常
r.encoding=‘utf-8‘#无论原来用什么编码都改为utf-8return r.text
except:
return‘‘
二、beautifulsoup4库的基本使用
beautifulsoup4库用于解析和处理HTML和XML。其最大优点是能根据HTML和XML语法建立解析树,提取有用信息。
beautifulsoup4也是第三方库,使用前同样需要通过pip安装。
pip install beautifulsoup4
注意:beautifulsoup4库和beautifulsoup库不能混为一谈,后者由于年久失修,已经不再维护了。
在使用beautifulsoup4库之前需要进行引用:
from bs4 import BeautifulSoup
使用BeautifulSoup()创建一个BeautifulSoup对象。
import
requests
from bs4 import BeautifulSoup
r=requests.get(‘http://www.baidu.com‘)
r.encoding=‘utf-8‘
soup=BeautifulSoup(r.text,‘html.parser‘)
print(type(soup))
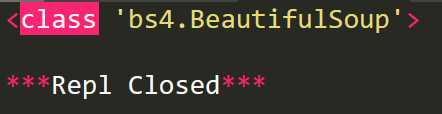
BeautifulSoup对象是一个树形结构,包含HTML页面中每一个Tag标签,这些标签构成BeautifulSoup对象的属性。BeautifulSoup对象常用属性如下:
soup.head:HTML页面的<head>内容
soup.title:HTML页面的标题内容,在<head>之中
soup.body:HTML页面的<body>内容
soup.p:HTML页面第一个<p>内容
soup.strings:HTML页面所有呈现在web上的字符串内容
soup.stripped_strings:HTML页面所有呈现在web上的非空格字符串内容
#
输出百度首页title标签的内容
import
requests
from bs4 import BeautifulSoup
r=requests.get(‘http://www.baidu.com‘)
r.encoding=‘utf-8‘
soup=BeautifulSoup(r.text,‘html.parser‘)
print(soup.title)
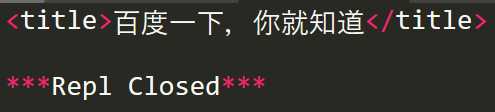
beautifulsoup4库中每一个Tag标签称为一个Tag对象,标签对象的常用属性如下:
name:标签本身的名称,是一个字符串,如a。
attrs:字典,包含了标签的全部属性。
contents:列表,包含当前标签下所有子标签的内容。
string:字符串,标签所包围的文本,网页中真实的文字。
import
requests
from bs4 import BeautifulSoup
r=requests.get(‘http://www.baidu.com‘)
r.encoding=‘utf-8‘
soup=BeautifulSoup(r.text,‘html.parser‘)
print(soup.a)
print(soup.a.name)
print(soup.a.attrs)
print(soup.a.string)
print(soup.p.contents)
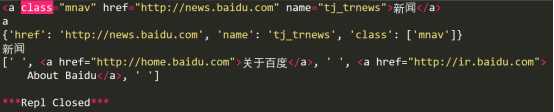
如果需要遍历整个HTML页面列出标签对应的所有内容,可以用到find_all()方法。
BeautifulSoup.find_all( name , attrs , recursive , string , limit )
根据参数找对应标签,返回类型为列表。参数如下:
name:根据标签名查找。
attrs:根据标签属性值查找,需要列出属性名和值,用JSON表示。
recursive:设置查找层次,只查找当前标签下一层时使用recursive=False。
string:根据关键字查找string属性内容,采用string=开始。
limit:返回结果个数,默认返回全部结果。
import
requests
from bs4 import BeautifulSoup
#爬取前程无忧网软件工程师薪资
r=requests.get(‘https://m.51job.com/search/joblist.php?jobarea=180400,180200&keyword=%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B%E5%B8%88&partner=webmeta‘)
r.encoding=‘utf-8‘
soup=BeautifulSoup(r.text,‘html.parser‘)
allsalary=soup.find_all(‘em‘)
for i in allsalary:
if len(i.text)==0:
continueprint(i.text)

原文:https://www.cnblogs.com/BIXIABUMO/p/11831212.html
内容总结
以上是互联网集市为您收集整理的Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)全部内容,希望文章能够帮你解决Python:requests库、BeautifulSoup4库的基本使用(实现简单的网络爬虫)所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。