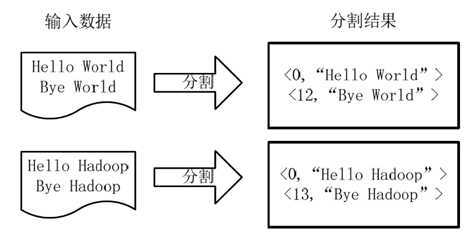
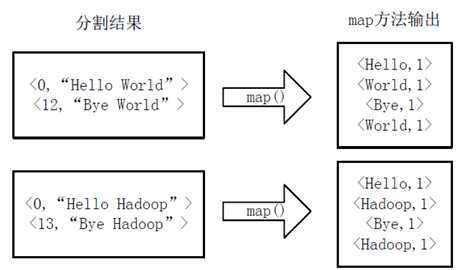
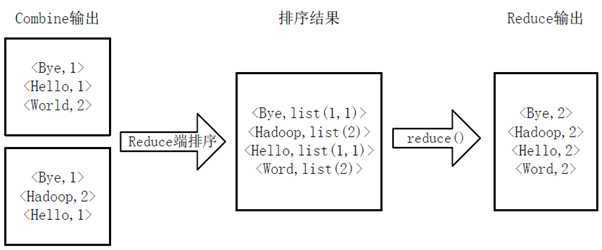
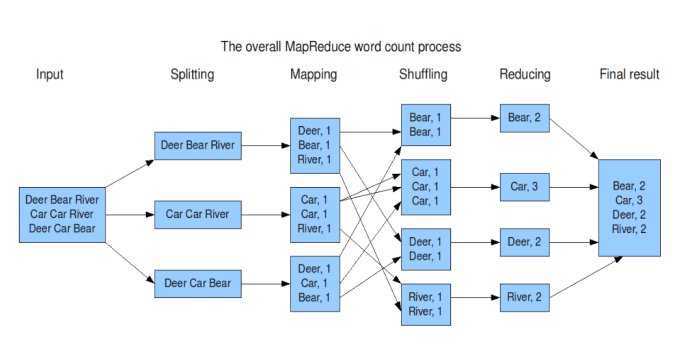
MapReduce的设计思想主要的思想是分而治之(divide and conquer),分治算法。将一个大的问题切分成很多小的问题,然后在集群中的各个节点上执行,这既是Map过程。在Map过程结束之后,会有一个Ruduce的过程,这个过程即将所有的Map阶段产出的结果进行汇集。写MapReduce程序的步骤:1.把问题转化为MapReduce模型2.设置运行的参数3.写map类4.写reduce类例子:统计单词个数将文件拆分成splits,每个文件为一个split,并将文件按行分割形成...
首先编写WordCount.java源文件,分别通过map和reduce方法统计文本中每个单词出现的次数,然后按照字母的顺序排列输出, Map过程首先是多个map并行提取多个句子里面的单词然后分别列出来每个单词,出现次数为1,全部列举出来 Reduce过程首先将相同key的数据进行查找分组然后合并,比如对于key为Hello的数据分组为:<Hello, 1>、<Hello,1>、<Hello,1>,合并之后就是<Hello,1+1+1>,分组也可以理解为reduce的操作,合并减少数据...
一、前言在之前我们已经在 CenOS6.5 下搭建好了 Hadoop2.x 的开发环境。既然环境已经搭建好了,那么现在我们就应该来干点正事嘛!比如来一个Hadoop世界的HelloWorld,也就是WordCount程序(一个简单的单词计数程序)二、WordCount 官方案例的运行2.1 程序简介WordCount程序是hadoop自带的案例,我们可以在 hadoop 解压目录下找到包含这个程序的 jar 文件(hadoop-mapreduce-examples-2.7.1.jar),该文件所在路径为 hadoop/share/hadoo...
1.在hadoop所在目录“usr/local”下创建一个文件夹inputroot@ubuntu:/usr/local# mkdir input2.在文件夹input中创建两个文本文件file1.txt和file2.txt,file1.txt中内容是“hello
word”,file2.txt中内容是“hello hadoop”、“hello mapreduce”(分两行)。root@ubuntu:/usr/local# cd inputroot@ubuntu:/usr/local/input# echo "hello
word" > file1.txtroot@ubuntu:/usr/local/input# echo "hello hadoop" >
file2.txtroot@ub...
最近学习hadoop,在windows+eclipse+虚拟机hadoop集群环境下运行mapreduce程序遇到了很多问题。上网查了查,并经过自己的分析,最终解决,在此分享一下,给遇到同样问题的人提供参考。我的hadoop集群环境:虚拟机上4台机器:192.168.137.111(master)、192.168.137.112(slave1)、192.168.137.113(slave2)、192.168.137.114(slave3)hadoop集群用户名:hadoophadoop版本:hadoop-1.1.2开发环境:windows7+eclipse+hadoop插件异...
1、配置集群(1)在yarn-env.sh中配置JAVA_HOMEexport JAVA_HOME=/opt/module/jdk1.8.0_11(2)在yarn-site.xml中配置<!--Reducer获取数据的方式--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--指定yarn的ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop01</value></property>(3)配置mapred-env.shexport JAVA_HOME=/opt...
按这里的教程: http://www.imooc.com/learn/391 试验时,发现在wordcount的最后一步一直提示如下错误:Exception in thread "main" java.lang.ClassNotFoundException:WordCountat java.net.URLClassLoader$1.run(URLClassLoader.java:366)at java.net.URLClassLoader$1.run(URLClassLoader.java:355)at java.security.AccessController.doPrivileged(Native Method)at java.net.URLClassLoader.findClass(URLClassLoader.java:35...
//这个是在原来的基础上改动以后得到的,将当中的分词的根据给换掉了,而且进行词频统计的时候会自己主动的忽略大写和小写 packageorg.apache.hadoop.mapred; importjava.io.IOException;importjava.util.ArrayList;importjava.util.Iterator;importjava.util.List;importjava.util.StringTokenizer; importorg.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;importorg.apache.hadoop.fs.Path;impor...
花了整整一个下午(6个多小时),整理总结,也算是对这方面有一个深度的了解。日后可以回头多看看。 我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功。在终端中用命令创建一个文件夹,简单的向两个文件中各写入一 花了整整一个下午(6个多小时),整理总结,也算是对这方面有一个深度的了解。日后可以回头多看看。我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,...
上一篇文章搭建Hadoop环境的详细过程中已经详细介绍了如何搭建Hadoop环境,今天介绍如何运行Hadoop环境下的第一个实例WordCount。 在伪分布模式下运行一下hadoop自带的例子WordCount来感受以下MapReduce过程:这时注意程序是在文件系统dfs运行的,创建的文件上一篇文章搭建Hadoop环境的详细过程中已经详细介绍了如何搭建Hadoop环境,今天介绍如何运行Hadoop环境下的第一个实例WordCount。
在伪分布模式下运行一下hadoop自带的例子W...
准备 准备一些输入文件,可以用hdfs dfs -put xxx/*?/user/fatkun/input上传文件 代码 package com.fatkun;?import java.io.IOException;import java.util.ArrayList;import java.util.List;import java.util.StringTokenizer;?import org.apache.commons.lo准备
准备一些输入文件,可以用hdfs dfs -put xxx/*?/user/fatkun/input上传文件
代码
package com.fatkun;
?
import java.io.IOException;
import java.util.ArrayList;
im...
java是hadoop开发的标准官方语言,本文下载了官方的WordCount.java并对其进行了编译和打包,然后使用测试数据运行了该hadoop程序。 这里假定已经装好了hadoop的环境,在Linux下运行hadoop命令能够正常执行; 下载java版本的WordCount.java程序。 将WordCountjava是hadoop开发的标准官方语言,本文下载了官方的WordCount.java并对其进行了编译和打包,然后使用测试数据运行了该hadoop程序。这里假定已经装好了hadoop的环境,在Linux...
hadoop2.2.0的eclipse插件在http://download.csdn.net/detail/acm_er6/6964345 ,下载后直接拷贝到/usr/lib/eclipse/plugins/目录下然后重启eclipse后如果eclipse右边出现一头hadoop标志的小象即说明插件安装成功。然后窗口—首选项,选择Hadoop Map/Reducehadoop2.2.0的eclipse插件在http://download.csdn.net/detail/acm_er6/6964345 ,下载后直接拷贝到/usr/lib/eclipse/plugins/目录下然后重启eclipse后如果eclipse右边出现一头...
纯干活:通过WourdCount程序示例:详细讲解MapReduce之BlockSplitShuffleMapReduce的区别及数据处理流程。 Shuffle过程是MapReduce的核心,集中了MR过程最关键的部分。要想了解MR,Shuffle是必须要理解的。了解Shuffle的过程,更有利于我们在对MapReduce job纯干活:通过WourdCount程序示例:详细讲解MapReduce之Block+Split+Shuffle+Map+Reduce的区别及数据处理流程。Shuffle过程是MapReduce的核心,集中了MR过程最关键的部分。要...
其他都没啥 这个 jar都在这里了。 import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Te
其他都没啥 这个 jar都在这里了。
import java.io.IOException;
import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;
import org.apache.had...