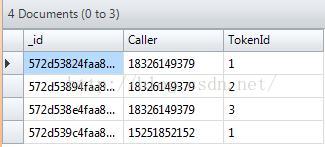
最近在写一个爬虫工具,将网站的数据储存到mongodb中,由于数据有重复的,所以我就在建立数据库的时候,为集合建立了索引,下面说下我的步骤,集合名称为drugitem,下面是集合截图:我要为name字段创建唯一索引,因为要保证name没有重复:就这样我运行程序发现数据比原来没有设置唯一索引时少了好多,我仔细查看发现程序在name字段重复的地方停止了,这不是我想要的结果,因为后面的数据还没有查询完成。于是我就删除了原来创建的n...
场景描述:
现有类似 {key:"value",key1:"value1"} 这样的文档。我使用db.collection.insertMany()将文档批量插入到集合之中,例如:
db.collection.insertMany([{key:"1",key1:"value1"},{key:"2",key1:"value1"},{key:"3",key1:"value1"},……
]);具体问题描述:
我需要key的值是唯一的,在批量插入的时候自动舍弃掉有重复值的文档。我有尝试使用db.collection.createIndex({key:1},{unique:true})给这个集合添加 unique 索引,...
using MongoDB;
using DockSample.DB;
using MongoDB.Driver;
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.IO;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using WeifenLuo.WinFormsUI.Docking;
using MongoDB.Bson;namespace DockSample
{public partial class Form2 : DockContent{public Form2(){Initiali...
下面是集合截图:我要为name字段创建唯一索引,因为要保证name没有重复:就这样我运行程序发现数据比原来没有设置唯一索引时少了好多,我仔细查看发现程序在name字段重复的地方停止了,这不是我想要的结果,因为后面的数据还没有查询完成。于是我就删除了原来创建的name索引:然后remove数据,重新按照老办法重新抓取数据,这样一来数据是得到了,但是本质问题还没解决,里面含有许多重复数据,于是我使用唯一索引+去重操作得到最终...
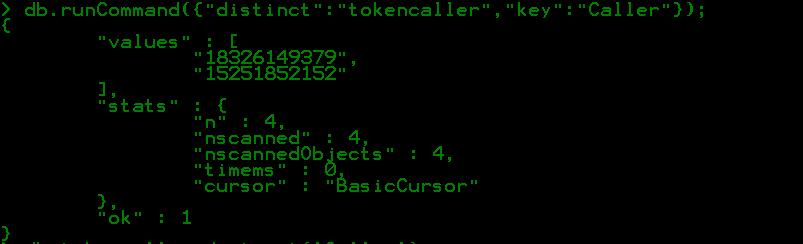
以这个简单的集合为例,我们需要集合中包含多少不同的手机号码,首先想到的应该就是使用distinct关键字,
db.tokencaller.distinct(‘Caller‘).length
如果想查看具体的而不同的手机号码,那么可以省略后面的length属性,因为db.tokencaller.distinct(‘Caller‘)返回的是由所有去重手机号码组成的数组。但是,这种方式对于所有情况都是满足的嘛?并不如此,如果要统计的集合记录数较大,如千万级别的,那么在这么统计的时候往往会...
原表记录:需要把related_type=1 and action_type=3 并且related_id相同的删掉一条。只留一个去重。db.user_action_log.aggregate([
{$match:{related_type:1,action_type:3}}, (查询条件){$group: { _id: {related_id: ‘$related_id‘},count: {$sum: 1},dups: {$addToSet: ‘$_id‘}} (根据related_id分组,$group只会返回参与分组的字段,使用$addToSet在返回结果数组中增加_id字段)
},{$match: {count: {$gt: ...
, dropDups : true} # 无法使用了大概思路是,通过aggregation先group出重复的键值对并做count,之后match所有count>2的键值对,认为他们是重复的,保留其中一条,删除其余。实现代码如下:from pymongo import DeleteOne
from threading import Thread
from apscheduler.schedulers.blocking import BlockingScheduler
from Application.Utils.Log import Logclass DupKeywordRemove:def __init__(self):models = [monde1, monde...
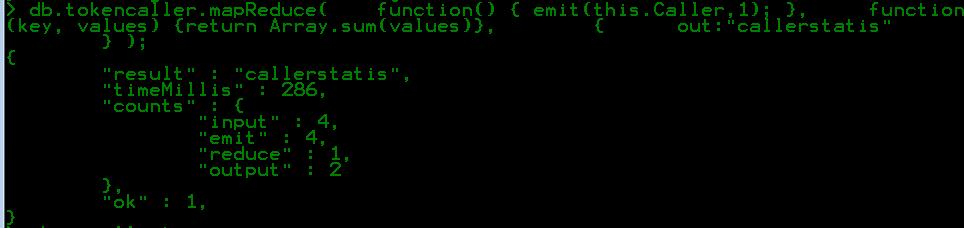
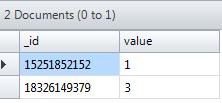
比方说我们有个Mongodb集合, 以这个简单的集合为例,我们需要集合中包含多少不同的手机号码,首先想到的应该就是使用distinct关键字, db.tokencaller.distinct(Caller).length 如果想查看具体的而不同的手机号码,那么可以省略后面的length属性,因为 db比方说我们有个Mongodb集合,以这个简单的集合为例,我们需要集合中包含多少不同的手机号码,首先想到的应该就是使用distinct关键字,
db.tokencaller.distinct(Caller).lengt...
文章前面
关于版本依赖
版本springboot
2.0.8.RELEASEmongodb
4.0.14本内容只是为了介绍mongodb最基础的使用以及配置,作为一个知名的数据库,其存在相当多的高级用法,展开来介绍内容会相当多,当然本人并非相关领域的大神,下面内容只不过整理了自己日常使用的一些积累。是对自己经验的积累,也希望能帮助后来的同学
关于项目
本内容也是我尝试整理工作中接触过各种工具在springboot中使用的方法。下面介绍的所有方法都已经提供了...
由于某些原因,我们的MongoDB里存在重复数据,甚至已经影响到数据统计。
其实在MongoDB 3.2之前可以通过索引直接去重。但这一特性在3.2版本之初已经移除。{unique : true, dropDups : true} # 无法使用了大概思路是,通过aggregation先group出重复的键值对并做count,之后match所有count>2的键值对,认为他们是重复的,保留其中一条,删除其余。实现代码如下:from pymongo import DeleteOne
from threading import Thread
from a...
原表记录:需要把related_type=1 and action_type=3 并且related_id相同的删掉一条。只留一个去重。db.user_action_log.aggregate([
{$match:{related_type:1,action_type:3}}, (查询条件){$group: { _id: {related_id: $related_id},count: {$sum: 1},dups: {$addToSet: $_id}} (根据related_id分组,$group只会返回参与分组的字段,使用$addToSet在返回结果数组中增加_id字段)
},{$match: {count: {$gt: 1}} ...
mongo客户端工具下载? https://robomongo.org/download
?
线上业务,k线 展示出现问题,相同时间戳的数据多次插入导致数据不真实,后经排查发现是每次都是写的四条数据,找开发配合一起查找问题,发现是后台逻辑处理的问题
?
需求:将重复的数据去掉,只保留一份数据
?
客户端数据查询:
?
?
?由于表太多 一张一张去删 很麻烦 于是写了个脚本偷懒
? 1 #!/bin/sh2 # liyongjian5179@163.com3 #将所有的表名导出来4 mongo 192.168.11...