1、过拟合和欠拟合怎么判断,如何解决?答:主要可以通过训练误差和测试误差入手判断是否过拟合或欠拟合。一般而言训练误差很低,但是测试误差较高,过拟合的概率较大,如果训练误差和测试误差都很高,一般是欠拟合。过拟合可以从增加样本量,减少特征数,降低模型复杂度等方面入手,实际的例子比如线性回归中,对于几十个样本的数据点就没必要用几十个变量去拟合。欠拟合则反之,需要考虑模型是否收敛,特征是否过少,模型是否过于...
机器学习与数据挖掘中的十大经典算法背景:top10算法的前期背景是吴教授在香港做了一个关于数据挖掘top10挑战的一个报告,会后有一名内地的教授提出了一个类似的想法。吴教授觉得非常好,开始着手解决这个事情。找了一系列的大牛(都是数据挖掘的大牛),都觉得想法很好,但是都不愿自己干。原因估计有一下几种:1.确实很忙2.得罪人3.一系列工作很繁琐等等。最后和明尼苏达大学的Vipin Kumar教授一起把这件事情承担下来。先是请数据...
大数据时代 数据挖掘十大经典算法不不过选中的十大算法,事实上參加评选的18种算法。实际上随便拿出一种来都能够称得上是经典算法,它们在数据挖掘领域都产生了极为深远的影响。1.C4.5C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法.C4.5算法继承了ID3算法的长处。并在下面几方面对ID3算法进行了改进:1)用信息增益率来选择属性。克服了用信息增益选择属性时偏向选择取值多的属性的不足;2)在树构造过程中进行...
一、无监督学习 1、聚类:是一个将数据集中在某些方面相似的数据成员进行分类组织的过程。因此,一个聚类就是一些数据实例的集合。聚类技术经常被称为无监督学习。二、K-均值聚类 1、k—均值算算法:是发现给定数据集k个簇的算法 2、步骤: 1)、随机选取k个数据点作为初始的聚类中心(要求发现k个簇)。 2)、把每个数据点分配给距离它最近的聚类中心(对图中的所有点求到这K个种子点的距离,假如点P离种子...
300G炼数_云计算_hadoop大数据挖掘_机器学习_推荐系统_算法_视频教程(高清)?全网炼数_云计算_hadoop大数据挖掘_机器学习_推荐系统_算法_视频教程等高端课程,最牛B的集合,基础入门到精通项目实战,带你学习大数据,带你吊炸天!1.机器人学习2.大数据的统计学基础3.大数据的矩阵基础4.SAS数据分析视频教程5.R语言全套视频教程6.Clementine视频教程7.数据挖掘教程8.数据分析与SPSS(完整)共12周9.大数据快速数据挖掘平台RapidMiner...
0 简介0.1 主题0.2 目标0.2.1 能掌握聚类的距离计算方式0.2.2 能够掌握聚类的各种方式1 聚类定义2 距离计算与相似度方法总结2.1 距离算法2.2 余弦相似度与Pearson相似度3 K-Means算法过程3.1 算法过程 3.2 代码实现# 导入包import numpy as np
import sklearn
from sklearn.datasets import make_blobs # 导入产生模拟数据的方法from sklearn.cluster import KMeans # 导入kmeans 类# 1. 产生模拟数据;random_state此参数让结果...
三.FP-tree算法 下面介绍一种使用了与Apriori完全不同的方法来发现频繁项集的算法FP-tree。FP-tree算法在过程中没有像Apriori一样产生候选集,而是采用了更为紧凑的数据结构组织tree, 再直接从这个结构中提取频繁项集。FP-tree算法的过程为:首先对事务中的每个项计算支持度,丢弃其中非频繁的项,每个项的支持度进行倒序排序。同时对每一条事务中的项也按照倒序进行排序。根据每条事务中事务项的新顺序,依此插入到一棵以Null为...
贝叶斯分类器 贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类。眼下研究较多的贝叶斯分类器主要有四种,各自是:Naive
Bayes、TAN、BAN和GBN。 贝叶斯网络是一个带有概率凝视的有向无环图,图中的每个结点均表示一个随机变量,图中两结点间若存在着一条弧,则表示这两结点相相应的随机变量是概率相依的,反之则说...
感知机—神经网络最基本的模型
感知机(perceptron)是二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别(取1和0)。感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面.其中,w0? 是一个偏差值,这个条件是必要的,如果没有这个条件,切平面会经过原点。我们需要这个偏差值控制决策平面到原点的距离。
下图中感知机实现了与门和或门的功能为了求得合适的超平面,我们导入了基于误分类的损...
关联规则挖掘(Association rule mining)是数据挖掘中最活跃的研究方法之一,可以用来发现事情之间的联系,最早是为了发现超市交易数据库中不同的商品之间的关系。(啤酒与尿布)
基本概念
1、支持度的定义:support(X-->Y) = |X交Y|/N=集合X与集合Y中的项在一条记录中同时出现的次数/数据记录的个数。例如:support({啤酒}-->{尿布}) = 啤酒和尿布同时出现的次数/数据记录数 = 3/5=60%。
2、自信度的定义:confidence(X-->Y) = |X交...
2017-02-11 Mail:10867910@qq.comC4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,积累经验,为后续决策服务。
该算法目前能找到各类版本,C、JAVA、PYTHON。而SQL版本闻所未闻,前篇我有提过,数据处理,SQL为王,如何以SQL的思维来实现C4.5决策树算法是本篇的重点。
PS:...
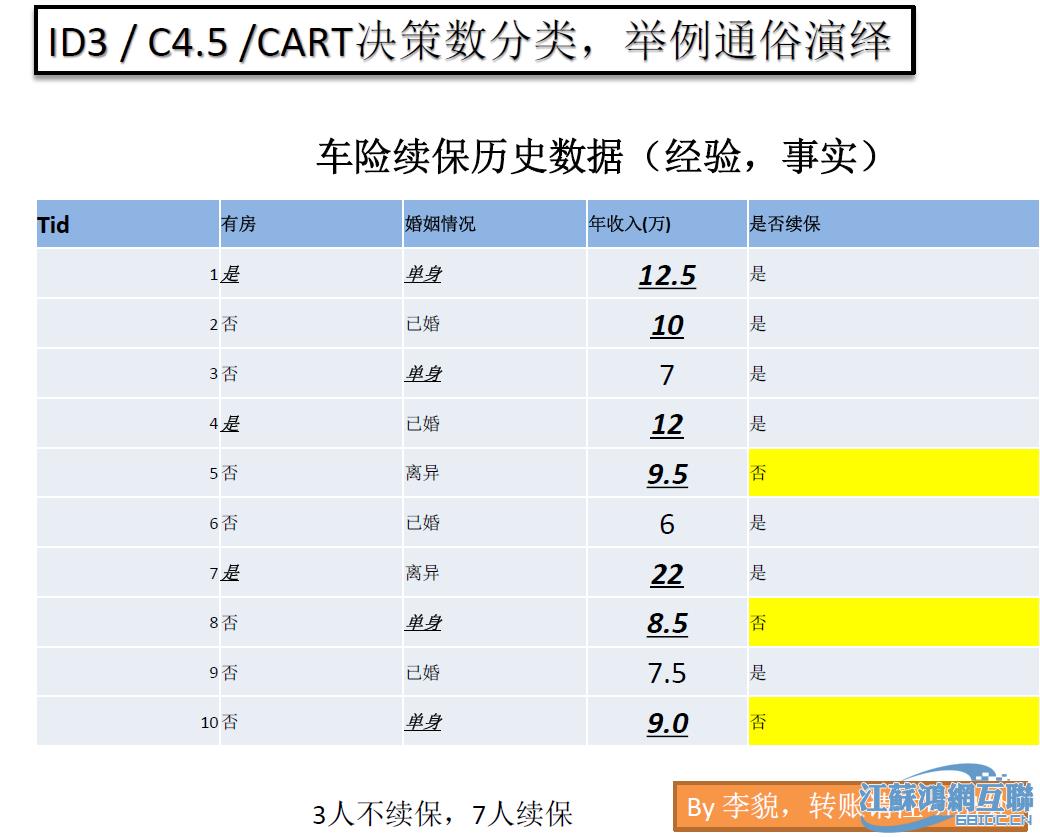
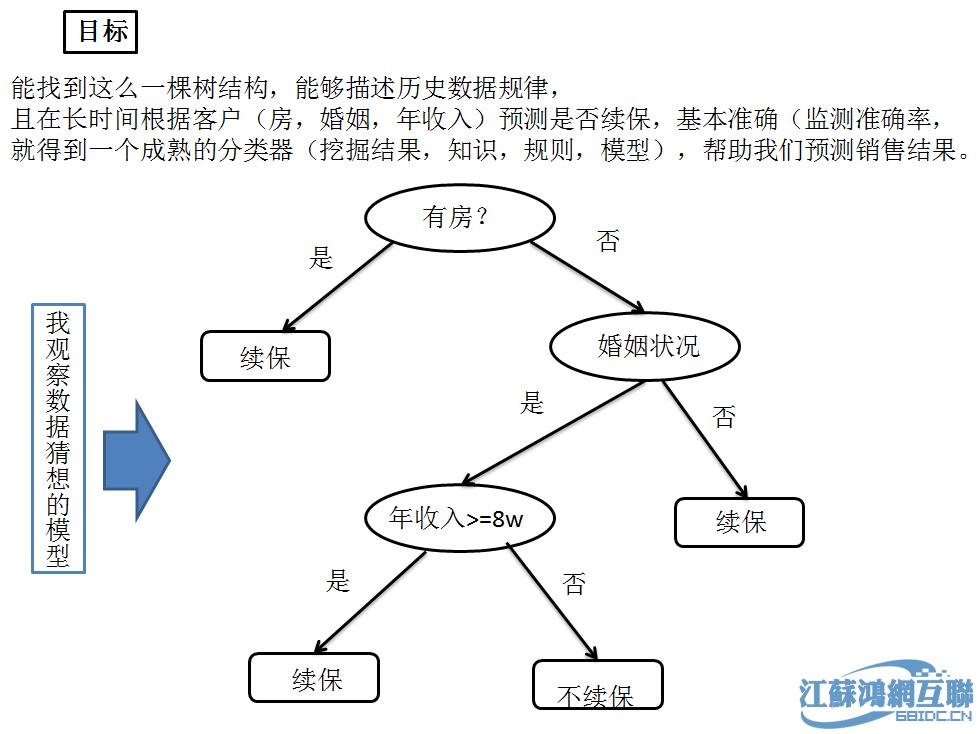
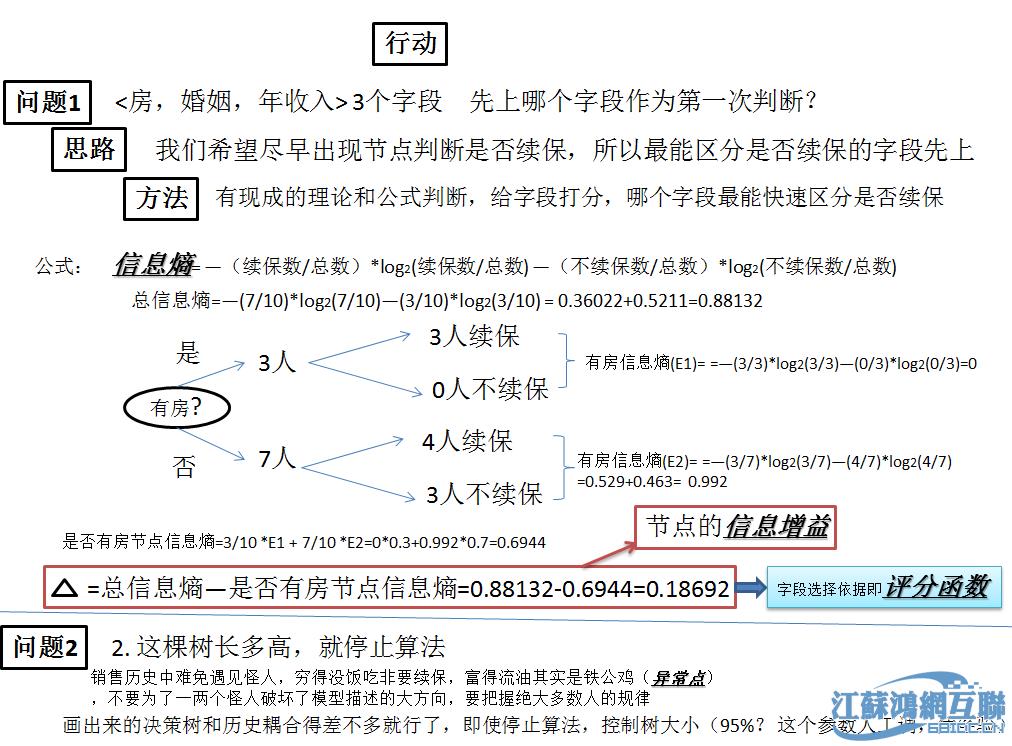
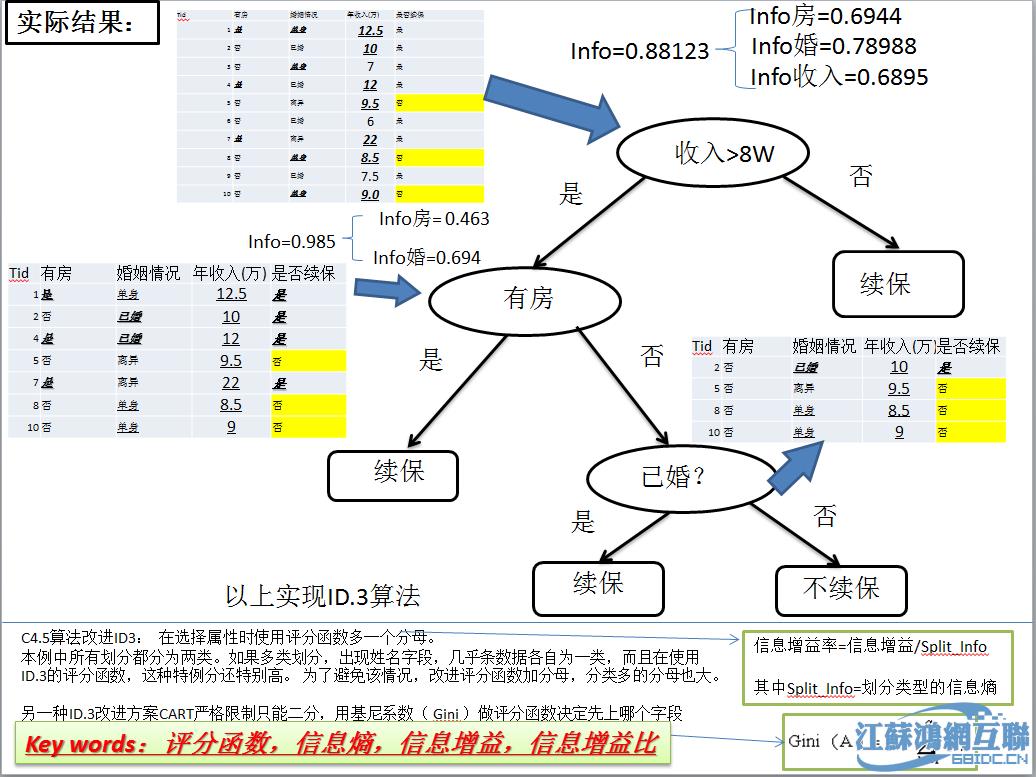
1.决策树算法
决策树,又称判定树,是一种类似二叉树或多叉树的树结构。决策树是用样本的属性作为结点,用属性的取值作为分支,也就是类似流程图的过程,其中每个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点代表类或类分布。它对大量样本的属性进行分析和归纳。根结点是所有样本中信息量最大的属性,中间结点是以该结点为根的子树所包含的样本子集中信息量最大的属性,决策树的叶结点是样本的类别值...
在各种数据挖掘算法中,关联规则挖掘算是比较重要的一种,尤其是受购物篮分析的影响,关联规则被应用到很多实际业务中,本文对关联规则挖掘做一个小的总结。 首先,和聚类算法一样,关联规则挖掘属于无监督学习方法,它描述的是在一个事物中物品间同时出现的在各种数据挖掘算法中,关联规则挖掘算是比较重要的一种,尤其是受购物篮分析的影响,关联规则被应用到很多实际业务中,本文对关联规则挖掘做一个小的总结。 首先,和聚类算...
决策树是对数据进行分类,以此达到预测的目的。该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复该过程一直到形成正确的决策集。决策树代表着决策集的树形结构。 决策树由决策结点决策树是对数据进行分类,以此达到预测的目的。该决策树方法先根据训练集数据形成决策树,如果该树不能对所有对象给出正确的分类,那么选择一些例外加入到训练集数据中,重复...
欢迎进入Windows社区论坛,与300万技术人员互动交流 >>进入 数据挖掘算法是创建挖掘模型的机制。若要创建模型,算法将首先分析一组数据,查找特定模式和趋势。然后,算法将使用此分析的结果来定义挖掘模型的参数。 算法创建的挖掘模型可以采用多种形式,这包欢迎进入Windows社区论坛,与300万技术人员互动交流 >>进入 数据挖掘算法是创建挖掘模型的机制。若要创建模型,算法将首先分析一组数据,查找特定模式和趋势。然后,算法...