首页 / 算法 / nowcoder 左神算法Java版2
nowcoder 左神算法Java版2
内容导读
互联网集市收集整理的这篇技术教程文章主要介绍了nowcoder 左神算法Java版2,小编现在分享给大家,供广大互联网技能从业者学习和参考。文章包含46328字,纯文字阅读大概需要67分钟。
内容图文

链表与荷兰国旗问题
将单向链表按某值划分成左边小、中间相等、右边大的形式
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
|
复制含有随机指针结点的链表
借助哈希表,额外空间O(N)
将链表的所有结点复制一份,以key,value为源结点,副本结点的方式存储到哈希表中,再建立副本结点之间的关系(next、rand指针域)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
|
进阶操作:额外空间O(1)
将副本结点追加到对应源结点之后,建立副本结点之间的指针域,最后将副本结点从该链表中分离出来。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
若两个可能有环的单链表相交,请返回相交的第一个结点
根据单链表的定义,每个结点有且只有一个next指针,那么如果单链表有环,它的结构将是如下所示:

相交会导致两个结点指向同一个后继结点,但不可能出现一个结点有两个后继结点的情况。
1、当相交的结点不在环上时,有如下两种情况:
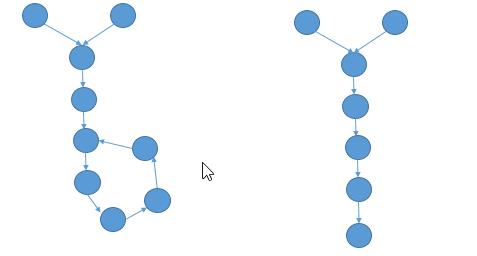
2、当相交的结点在环上时,只有一种情况:
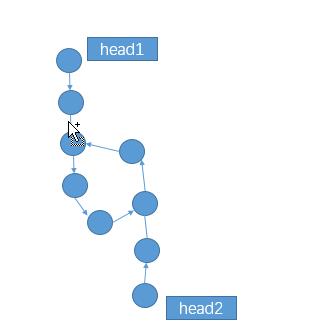
综上,两单链表若相交,要么都无环,要么都有环。
此题还需要注意的一点是如果链表有环,那么如何获取入环呢(因为不能通过next是否为空来判断是否是尾结点了)。这里就涉及到了一个规律:如果快指针fast和慢指针slow同时从头结点出发,fast走两步而slow走一步,当两者相遇时,将fast指针指向头结点,使两者都一次只走一步,两者会在入环结点相遇。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 |
|
对应三种情况测试如下:

| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
|
栈和队列
用数组结构实现大小固定的栈和队列
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
|
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
|
取栈中最小元素
实现一个特殊的栈,在实现栈的基本功能的基础上,再实现返回栈中最小元素的操作getMin。要求如下:
- pop、push、getMin操作的时间复杂度都是O(1)。
- 设计的栈类型可以使用现成的栈结构。
思路:由于每次push之后都会可能导致栈中已有元素的最小值发生变化,因此需要一个容器与该栈联动(记录每次push产生的栈中最小值)。我们可以借助一个辅助栈,数据栈push第一个元素时,将其也push到辅助栈,此后每次向数据栈push元素的同时将其和辅助栈的栈顶元素比较,如果小,则将其也push到辅助栈,否则取辅助栈的栈顶元素push到辅助栈。(数据栈正常push、pop数据,而辅助栈push每次数据栈push后产生的栈中最小值;但数据栈pop时,辅助栈也只需简单的pop即可,保持同步)
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
|
仅用队列结构实现栈结构
思路:只要将关注点放在 后进先出 这个特性就不难实现了。使用一个数据队列和辅助队列,当放入数据时使用队列的操作正常向数据队列中放,但出队元素时,需将数据队列的前n-1个数入队辅助队列,而将数据队列的队尾元素弹出来,最后数据队列和辅助队列交换角色。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
|
仅用栈结构实现队列结构
思路:使用两个栈,一个栈PutStack用来放数据,一个栈GetStack用来取数据。取数据时,如果PulllStack为空则需要将PutStack中的所有元素一次性依次pop并放入GetStack。
特别要注意的是这个 倒数据的时机:
- 只有当GetStack为空时才能往里倒
- 倒数据时必须一次性将PutStack中的数据倒完
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
|
二叉树
实现二叉树的先序、中序、后续遍历,包括递归方式和非递归方式
递归方式
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
|
以先根遍历二叉树为例,可以发现递归方式首先尝试打印当前结点的值,随后尝试打印左子树,打印完左子树后尝试打印右子树,递归过程的base case是当某个结点为空时停止子过程的展开。这种递归尝试是由二叉树本身的结构所决定的,因为二叉树上的任意结点都可看做一棵二叉树的根结点(即使是叶子结点,也可以看做是一棵左右子树为空的二叉树根结点)。
观察先序、中序、后序三个递归方法你会发现,不同点在于打印当前结点的值这一操作的时机。你会发现每个结点会被访问三次:进入方法时算一次、递归处理左子树完成之后返回时算一次、递归处理右子树完成之后返回时算一次。因此在preOrderRecursive中将打印语句放到方法开始时就产生了先序遍历;在midOrderRecursive中,将打印语句放到递归chu处理左子树完成之后就产生了中序遍历。
非递归方式
先序遍历
拿到一棵树的根结点后,首先打印该结点的值,然后将其非空右孩子、非空左孩子依次压栈。栈非空循环:从栈顶弹出结点(一棵子树的根节点)并打印其值,再将其非空右孩子、非空左孩子依次压栈。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
你会发现压栈的顺序和打印的顺序是相反的,压栈是先根结点,然后有右孩子就压右孩子、有左孩子就压左孩子,这是利用栈的后进先出。每次获取到一棵子树的根节点之后就可以获取其左右孩子,因此无需保留其信息,直接弹出并打印,然后保留其左右孩子到栈中即可。
中序遍历
对于一棵树,将该树的左边界全部压栈,root的走向是只要左孩子不为空就走向左孩子。当左孩子为空时弹出栈顶结点(此时该结点是一棵左子树为空的树的根结点,根据中序遍历可以直接打印该结点,然后中序遍历该结点的右子树)打印,如果该结点的右孩子非空(说明有右子树),那么将其右孩子压栈,这个右孩子又可能是一棵子树的根节点,因此将这棵子树的左边界压栈,这时回到了开头,以此类推。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
后序遍历
思路一:准备两个栈,一个栈用来保存遍历时的结点信息,另一个栈用来排列后根顺序(根节点先进栈,右孩子再进,左孩子最后进)。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
思路二:只用一个栈。借助两个变量h和c,h代表最近一次打印过的结点,c代表栈顶结点。首先将根结点压栈,此后栈非空循环,令c等于栈顶元素(c=stack.peek())执行以下三个分支:
- c的左右孩子是否与h相等,如果都不相等,说明c的左右孩子都不是最近打印过的结点,由于左右孩子是左右子树的根节点,根据后根遍历的特点,左右子树肯定都没打印过,那么将左孩子压栈(打印左子树)。
- 分支1没有执行说明c的左孩子要么不存在;要么左子树刚打印过了;要么右子树刚打印过了。这时如果是前两种情况中的一种,那就轮到打印右子树了,因此如果c的右孩子非空就压栈。
- 如果前两个分支都没执行,说明c的左右子树都打印完了,因此弹出并打印c结点,更新一下h。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
在二叉树中找一个结点的后继结点,结点除lleft,right指针外还包含一个parent指针
这里的后继结点不同于链表的后继结点。在二叉树中,前驱结点和后继结点是按照二叉树中两个结点被中序遍历的先后顺序来划分的。比如某二叉树的中序遍历是2 1 3,那么1的后继结点是3,前驱结点是2
你当然可以将二叉树中序遍历一下,在遍历到该结点的时候标记一下,那么下一个要打印的结点就是该结点的后继结点。
我们可以推测一下,当我们来到二叉树中的某个结点时,如果它的右子树非空,那么它的后继结点一定是它的右子树中最靠左的那个结点;如果它的右孩子为空,那么它的后继结点一定是它的祖先结点中,把它当做左子孙(它存在于祖先结点的左子树中)的那一个,否则它没有后继结点。
这里如果它的右孩子为空的情况比较难分析,我们可以借助一个指针parent,当前来到的结点node和其父结点parent的parent.left比较,如果相同则直接返回parent,否则node来到parent的位置,parent则继续向上追溯,直到parent到达根节点为止若node还是不等于parent的左孩子,则返回null表明给出的结点没有后继结点。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
|
介绍二叉树的序列化和反序列化
序列化
二叉树的序列化要注意的两个点如下:
- 每序列化一个结点数值之后都应该加上一个结束符表示一个结点序列化的终止,如!。
- 不能忽视空结点的存在,可以使用一个占位符如#表示空结点的序列化。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
重建
怎么序列化的,就怎么反序列化
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
|
判断一个树是否是平衡二叉树
根据定义可知,要确认一个二叉树是否是平衡二叉树势必要遍历所有结点。而遍历到每个结点时,要想知道以该结点为根结点的子树是否是平衡二叉树,我们要收集两个信息:
- 该结点的左子树、右子树是否是平衡二叉树
- 左右子树的高度分别是多少,相差是否超过1
那么我们来到某个结点时(子过程),我们需要向上层(父过程)返回的信息就是该结点为根结点的树是否是平衡二叉树以及该结点的高度,这样的话,父过程就能继续向上层返回应该收集的信息。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
|
递归很好用,该题中的递归用法也是一种经典用法,可以高度套路:
- 分析问题的解决需要哪些步骤(这里是遍历每个结点,确认每个结点为根节点的子树是否为平衡二叉树)
- 确定递归:父问题是否和子问题相同
- 子过程要收集哪些信息
- 本次递归如何利用子过程返回的信息得到本过程要返回的信息
- base case
判断一棵树是否是搜索二叉树
搜索二叉树的定义:对于二叉树的任意一棵子树,其左子树上的所有结点的值小于该子树的根节点的值,而其右子树上的所有结点的值大于该子树的根结点的值,并且整棵树上任意两个结点的值不同。
根据定义,搜索二叉树的中序遍历打印将是一个升序序列。因此我们可以利用二叉树的中序遍历的非递归方式,比较中序遍历时相邻两个结点的大小,只要有一个结点的值小于其后继结点的那就不是搜索二叉树。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|
判断一棵树是否是完全二叉树
根据完全二叉树的定义,如果二叉树上某个结点有右孩子无左孩子则一定不是完全二叉树;否则如果二叉树上某个结点有左孩子而没有右孩子,那么该结点所在的那一层上,该结点右侧的所有结点应该是叶子结点,否则不是完全二叉树。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
|
已知一棵完全二叉树,求其结点个数,要求时间复杂度0(N)
如果我们遍历二叉树的每个结点来计算结点个数,那么时间复杂度将是O(N^2),我们可以利用满二叉树的结点个数为2^h-1(h为树的层数)来加速这个过程。
首先完全二叉树,如果其左子树的最左结点在树的最后一层,那么其右子树肯定是满二叉树,且高度为h-1;否则其左子树肯定是满二叉树,且高度为h-2。也就是说,对于一个完全二叉树结点个数的求解,我们可以分解求解过程:1个根结点+ 一棵满二叉树(高度为h-1或者h-2)+ 一棵完全二叉树(高度为h-1)。前两者的结点数是可求的(1+2^level -1=2^level),后者就又成了求一棵完全二叉树结点数的问题了,可以使用递归。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
|
并查集
并查集是一种树型的数据结构,用于处理一些不交集(Disjoint Sets)的合并及查询问题。有一个联合-查找算法(union-find algorithm)定义了两个用于此数据结构的操作:
- Find:确定元素属于哪一个子集。它可以被用来确定两个元素是否属于同一子集。
- Union:将两个子集合并成同一个集合。
并查集结构的实现
首先并查集本身是一个结构,我们在构造它的时候需要将所有要操作的数据扔进去,初始时每个数据自成一个结点,且每个结点都有一个父指针(初始时指向自己)。
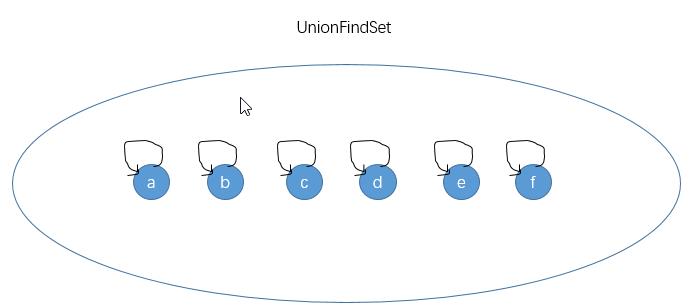
初始时并查集中的每个结点都算是一个子集,我们可以对任意两个元素进行合并操作。值得注意的是,union(nodeA,nodeB)并不是将结点nodeA和nodeB合并成一个集合,而是将nodeA所在的集合和nodeB所在的集合合并成一个新的子集:
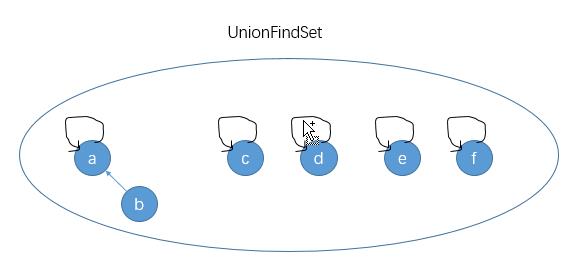
那么合并两个集合的逻辑是什么呢?首先要介绍一下代表结点这个概念:找一结点所在集合的代表结点就是找这个集合中父指针指向自己的结点(并查集初始化时,每个结点都是各自集合的代表结点)。那么合并两个集合就是将结点个数较少的那个集合的代表结点的父指针指向另一个集合的代表结点:
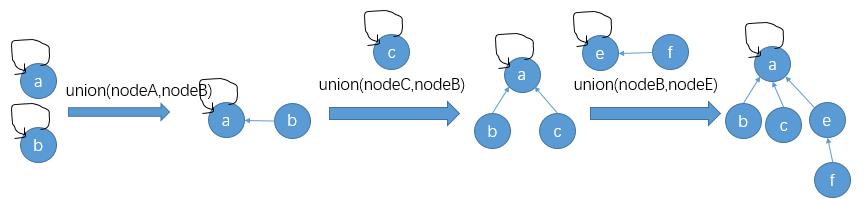
还有一个find操作:查找两个结点是否所属同一个集合。我们只需判断两个结点所在集合的代表结点是否是同一个就可以了:

代码示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
|
你会发现union和find的过程中都会有找一个结点所在集合的代表结点这个过程,所以我把它单独抽出来成一个getRoot,而且利用递归做了一个优化:找一个结点所在集合的代表结点时,会不停地向上找父指针指向自己的结点,最后在递归回退时将沿途路过的结点的父指针改为直接指向代表结点:

诚然,这样做是为了提高下一次查找的效率。
并查集的应用
并查集结构本身其实很简单,但是其应用却很难。这里以岛问题做引子,当矩阵相当大的时候,用单核CPU去跑这个遍历和感染效率是很低的,可能会使用并行计算框架来完成岛数量的统计。也就是说矩阵可能被分割成几个部分,逐个统计,最后在汇总。那么问题来了:
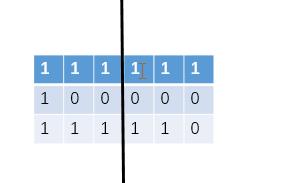
上面这个矩阵的岛数量是1;但如果从中间竖着切开,那么左边的岛数量是1,右边的岛数量是2,总数是3。如何处理切割后,相邻子矩阵之间的边界处的1相邻导致的重复统计呢?其实利用并查集的特性就很容易解决这个问题:
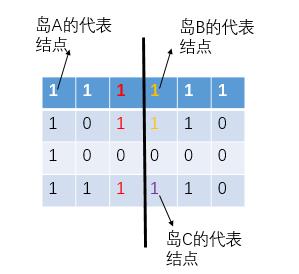
首先将切割边界处的数据封装成结点加入到并查集中并合并同一个岛上的结点,在分析边界时,查边界两边的1是否在同一个集合,如果不在那就union这两个结点,并将总的岛数量减1;否则就跳过此行继续分析下一行边界上的两个点。
内容总结
以上是互联网集市为您收集整理的nowcoder 左神算法Java版2全部内容,希望文章能够帮你解决nowcoder 左神算法Java版2所遇到的程序开发问题。 如果觉得互联网集市技术教程内容还不错,欢迎将互联网集市网站推荐给程序员好友。
内容备注
版权声明:本文内容由互联网用户自发贡献,该文观点与技术仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 gblab@vip.qq.com 举报,一经查实,本站将立刻删除。
内容手机端
扫描二维码推送至手机访问。